BERTopic
v0.16.4

Bertopic est une technique de modélisation de sujets qui exploite? Transformers et C-TF-IDF pour créer des grappes denses permettant des sujets facilement interprétables tout en gardant des mots importants dans les descriptions de sujet.
Bertopic prend en charge toutes sortes de techniques de modélisation de sujets:
| Guidé | Supervisé | Semi-surveillé |
| Manuel | Distributions multi-topiques | Hiérarchique |
| En cours | Dynamique | En ligne / incrémentiel |
| Multimodal | Multi-aspect | Génération de texte / LLM |
| Zéro-shot (nouveau!) | Modèle de fusion (nouveau!) | Mots de semence (Nouveau!) |
Des messages moyens correspondants peuvent être trouvés ici, ici et ici. Pour un aperçu plus détaillé, vous pouvez lire le document ou voir un bref aperçu.
L'installation, avec des transformateurs de phrase, peut être effectuée à l'aide de PYPI:
pip install bertopicSi vous souhaitez installer Bertopic avec d'autres modèles d'incorporation, vous pouvez choisir l'une des opérations suivantes:
# Choose an embedding backend
pip install bertopic[flair,gensim,spacy,use]
# Topic modeling with images
pip install bertopic[vision]Pour un aperçu approfondi des fonctionnalités de Bertopic, vous pouvez vérifier la documentation complète ou vous pouvez suivre l'un des exemples ci-dessous:
| Nom | Lien |
|---|---|
| Commencez ici - les meilleures pratiques en bertopique | |
| ? Nouveau! - Modélisation des sujets sur les grandes données (accélération du GPU) | |
| ? Nouveau! - Modélisation du sujet avec Llama 2? | |
| ? Nouveau! - Modélisation de sujets avec LLMS quantifiée | |
| Modélisation de sujets avec bertopique | |
| (Personnalisé) Modèles d'intégration en bertopique | |
| Personnalisation avancée en bertopique | |
| (semi-) modélisation de sujets supervisés avec bertopique | |
| Modélisation de sujets dynamiques avec les tweets de Trump | |
| Modélisation de sujets ARXIV RÉSUMÉS |
Nous commençons par extraire des sujets de l'ensemble de données de groupes de deux groupes bien connu contenant des documents anglais:
from bertopic import BERTopic
from sklearn . datasets import fetch_20newsgroups
docs = fetch_20newsgroups ( subset = 'all' , remove = ( 'headers' , 'footers' , 'quotes' ))[ 'data' ]
topic_model = BERTopic ()
topics , probs = topic_model . fit_transform ( docs )Après avoir généré des sujets et leurs probabilités, nous pouvons accéder à tous les sujets avec leurs représentations de sujet:
> >> topic_model . get_topic_info ()
Topic Count Name
- 1 4630 - 1_ can_your_will_any
0 693 49_ windows_drive_dos_file
1 466 32_j esus_bible_christian_faith
2 441 2_ space_launch_orbit_lunar
3 381 22_ key_encryption_keys_encrypted
... Le sujet -1 fait référence à tous les documents aberrants et est généralement ignoré. Chaque mot d'un sujet décrit le thème sous-jacent de ce sujet et peut être utilisé pour interpréter ce sujet. Ensuite, jetons un coup d'œil au sujet le plus fréquent généré:
> >> topic_model . get_topic ( 0 )
[( 'windows' , 0.006152228076250982 ),
( 'drive' , 0.004982897610645755 ),
( 'dos' , 0.004845038866360651 ),
( 'file' , 0.004140142872194834 ),
( 'disk' , 0.004131678774810884 ),
( 'mac' , 0.003624848635985097 ),
( 'memory' , 0.0034840976976789903 ),
( 'software' , 0.0034415334250699077 ),
( 'email' , 0.0034239554442333257 ),
( 'pc' , 0.003047105930670237 )] En utilisant .get_document_info , nous pouvons également extraire des informations sur un niveau de document, telles que leurs sujets correspondants, les probabilités, qu'il s'agisse de documents représentatifs pour un sujet, etc.:
> >> topic_model . get_document_info ( docs )
Document Topic Name Top_n_words Probability ...
I am sure some bashers of Pens ... 0 0_ game_team_games_season game - team - games ... 0.200010 ...
My brother is in the market for ... - 1 - 1_ can_your_will_any can - your - will ... 0.420668 ...
Finally you said what you dream ... - 1 - 1_ can_your_will_any can - your - will ... 0.807259 ...
Think ! It ' s the SCSI card doing ... 49 49_ windows_drive_dos_file windows - drive - docs ... 0.071746 ...
1 ) I have an old Jasmine drive ... 49 49_ windows_drive_dos_file windows - drive - docs ... 0.038983 ... Tip : Utilisez BERTopic(language="multilingual") pour sélectionner un modèle qui prend en charge plus de 50 langues.
Dans Bertopic, il existe un certain nombre de représentations de sujets différentes que nous pouvons choisir. Ils sont tous très différents les uns des autres et donnent des perspectives intéressantes et des variations des représentations de sujets. Un excellent début est KeyBERTInspired , ce qui, pour de nombreux utilisateurs, augmente la cohérence et réduit les mots d'arrêt des représentations de sujet résultantes:
from bertopic . representation import KeyBERTInspired
# Fine-tune your topic representations
representation_model = KeyBERTInspired ()
topic_model = BERTopic ( representation_model = representation_model )Cependant, vous voudrez peut-être utiliser quelque chose de plus puissant pour décrire vos grappes. Vous pouvez même utiliser ChatGpt ou d'autres modèles d'OpenAI pour générer des étiquettes, des résumés, des phrases, des mots clés, etc.
import openai
from bertopic . representation import OpenAI
# Fine-tune topic representations with GPT
client = openai . OpenAI ( api_key = "sk-..." )
representation_model = OpenAI ( client , model = "gpt-3.5-turbo" , chat = True )
topic_model = BERTopic ( representation_model = representation_model ) Tip : Au lieu d'itérer sur toutes ces différentes représentations de sujets, vous pouvez les modéliser simultanément avec des représentations de sujet multi-aspect en bertopique.
Après avoir formé notre modèle bertopique, nous pouvons parcourir de manière itérative des centaines de sujets pour obtenir une bonne compréhension des sujets qui ont été extraits. Cependant, cela prend un certain temps et n'a pas de représentation mondiale. Au lieu de cela, nous pouvons utiliser l'une des nombreuses options de visualisation de Bertopic. Par exemple, nous pouvons visualiser les sujets générés d'une manière très similaire à LDAVIS:
topic_model . visualize_topics ()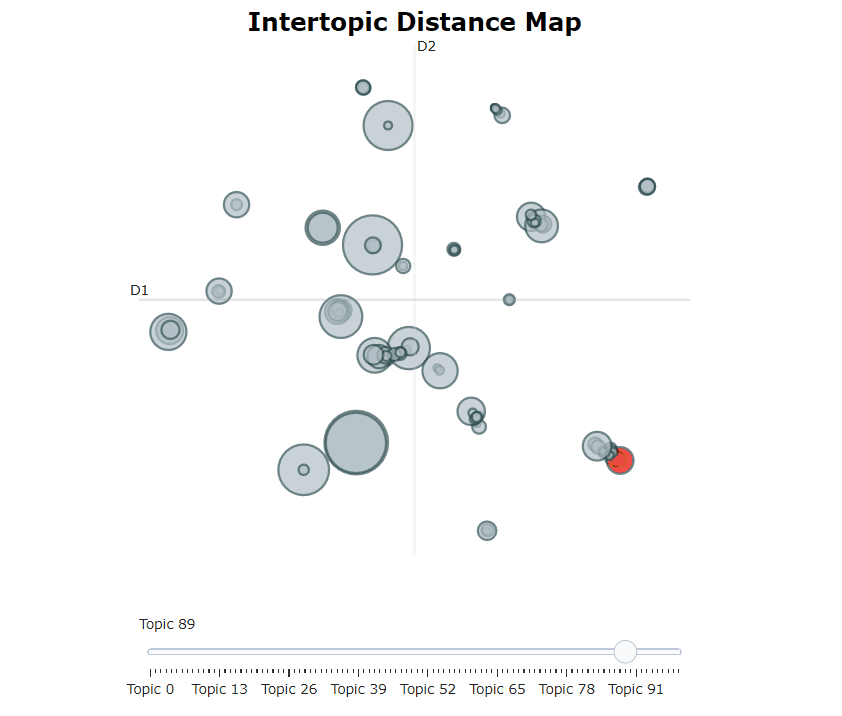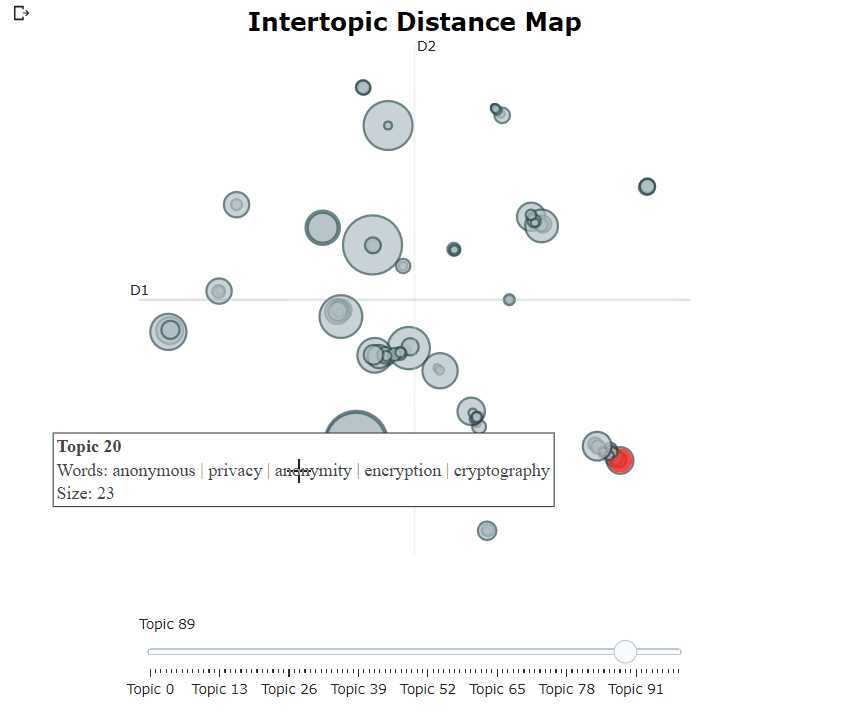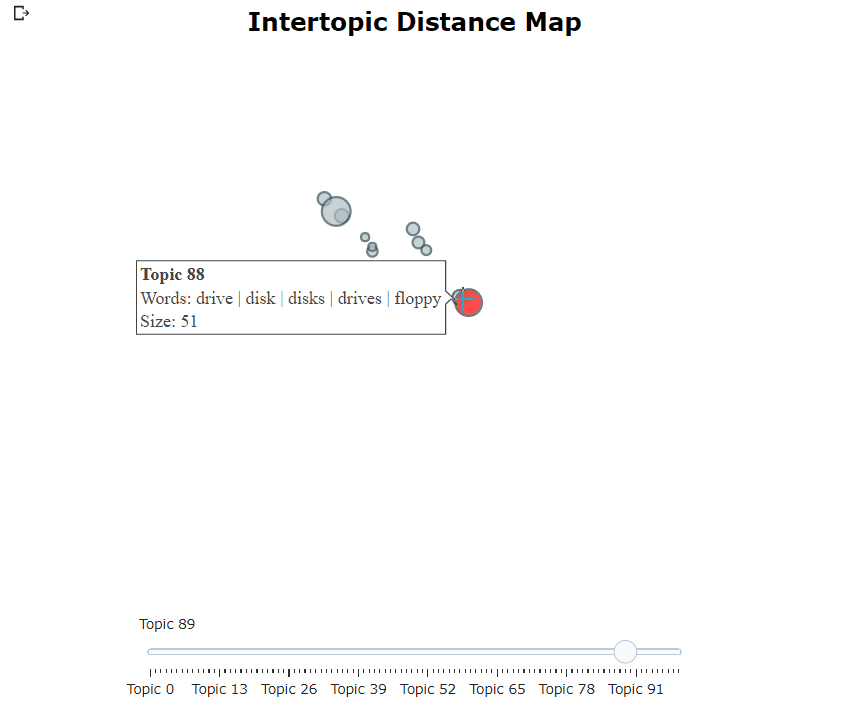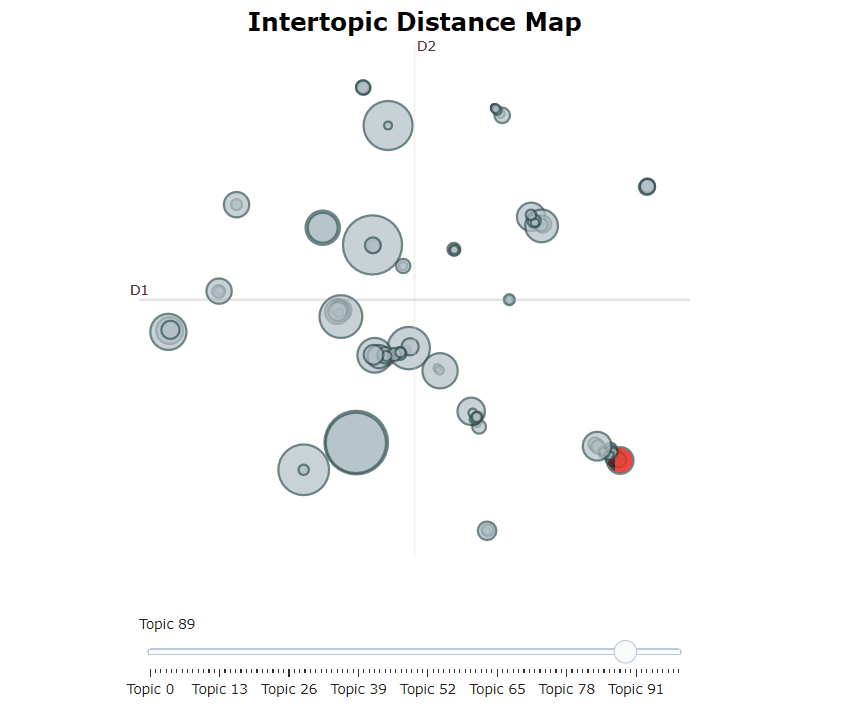
Par défaut, les principales étapes de la modélisation des sujets avec Bertopic sont les transformateurs de phrase, UMAP, HDBSCAN et C-TF-IDF exécutés en séquence. Cependant, il suppose une certaine indépendance entre ces étapes, ce qui rend le bertopique assez modulaire. En d'autres termes, Bertopic vous permet non seulement de créer votre propre modèle de sujet, mais d'explorer plusieurs techniques de modélisation de sujets en plus de votre modèle de sujet personnalisé:
Vous pouvez échanger l'un de ces modèles ou même les supprimer entièrement. Les étapes suivantes sont complètement modulaires:
Bertopic a de nombreuses fonctions qui peuvent rapidement devenir écrasantes. Pour atténuer ce problème, vous trouverez un aperçu de toutes les méthodes et une brève description de son objectif.
Ci-dessous, vous trouverez un aperçu des fonctions communes dans Bertopic.
| Méthode | Code |
|---|---|
| Ajuster le modèle | .fit(docs) |
| Ajuster le modèle et prédire les documents | .fit_transform(docs) |
| Prédire les nouveaux documents | .transform([new_doc]) |
| Accéder à un sujet unique | .get_topic(topic=12) |
| Accéder à tous les sujets | .get_topics() |
| Obtenez un sujet Freq | .get_topic_freq() |
| Obtenez toutes les informations sur le sujet | .get_topic_info() |
| Obtenez toutes les informations de document | .get_document_info(docs) |
| Obtenez des documents représentatifs par sujet | .get_representative_docs() |
| Mettre à jour la représentation du sujet | .update_topics(docs, n_gram_range=(1, 3)) |
| Générer des étiquettes de sujet | .generate_topic_labels() |
| Définir les étiquettes du sujet | .set_topic_labels(my_custom_labels) |
| Fusionner les sujets | .merge_topics(docs, topics_to_merge) |
| Réduire le NR des sujets | .reduce_topics(docs, nr_topics=30) |
| Réduire les valeurs aberrantes | .reduce_outliers(docs, topics) |
| Trouver des sujets | .find_topics("vehicle") |
| SAVER MODÈLE | .save("my_model", serialization="safetensors") |
| Modèle de chargement | BERTopic.load("my_model") |
| Obtenir des paramètres | .get_params() |
Après avoir formé votre modèle bertopique, plusieurs attributs sont enregistrés dans votre modèle. Ces attributs, en partie, se réfèrent à la façon dont les informations du modèle sont stockées sur un estimateur pendant l'ajustement. Les attributs que vous voyez ci-dessous se terminent par _ et sont des attributs publics qui peuvent être utilisés pour accéder aux informations du modèle.
| Attribut | Description |
|---|---|
.topics_ | Les sujets générés pour chaque document après la formation ou la mise à jour du modèle de sujet. |
.probabilities_ | Les probabilités générées pour chaque document si HDBSCAN est utilisée. |
.topic_sizes_ | La taille de chaque sujet |
.topic_mapper_ | Une classe pour suivre les sujets et leurs mappages chaque fois qu'ils sont fusionnés / réduits. |
.topic_representations_ | Les N supérieurs par sujet par sujet et leurs valeurs C-TF-IDF respectives. |
.c_tf_idf_ | La matrice à terme comme calculé via C-TF-IDF. |
.topic_aspects_ | Les différents aspects, ou représentations de chaque sujet. |
.topic_labels_ | Les étiquettes par défaut pour chaque sujet. |
.custom_labels_ | Étiquettes personnalisées pour chaque sujet générées via .set_topic_labels . |
.topic_embeddings_ | Les incorporations pour chaque sujet si embedding_model ont été utilisées. |
.representative_docs_ | Le représentant documente pour chaque sujet si HDBSCAN est utilisé. |
Il existe de nombreux cas d'utilisation différents dans lesquels la modélisation de sujets peut être utilisée. En tant que tels, plusieurs variations de bertopique ont été développées de sorte qu'un package peut être utilisé dans de nombreux cas d'utilisation.
| Méthode | Code |
|---|---|
| Approximation de distribution de sujet | .approximate_distribution(docs) |
| Modélisation du sujet en ligne | .partial_fit(doc) |
| Modélisation de sujet semi-supervisée | .fit(docs, y=y) |
| Modélisation de sujets supervisés | .fit(docs, y=y) |
| Modélisation du sujet manuel | .fit(docs, y=y) |
| Modélisation du sujet multimodal | .fit(docs, images=images) |
| Modélisation de sujets par classe | .topics_per_class(docs, classes) |
| Modélisation du sujet dynamique | .topics_over_time(docs, timestamps) |
| Modélisation du sujet hiérarchique | .hierarchical_topics(docs) |
| Modélisation du sujet guidé | BERTopic(seed_topic_list=seed_topic_list) |
| Modélisation du sujet zéro-shot | BERTopic(zeroshot_topic_list=zeroshot_topic_list) |
| Fusionner plusieurs modèles | BERTopic.merge_models([topic_model_1, topic_model_2]) |
L'évaluation des modèles de sujets peut être assez difficile en raison de la nature quelque peu subjective de l'évaluation. La visualisation de différents aspects du modèle de sujet aide à comprendre le modèle et facilite la modification du modèle à votre goût.
| Méthode | Code |
|---|---|
| Visualiser les sujets | .visualize_topics() |
| Visualiser les documents | .visualize_documents() |
| Visualiser la hiérarchie des documents | .visualize_hierarchical_documents() |
| Visualiser la hiérarchie du sujet | .visualize_hierarchy() |
| Visualiser l'arborescence du sujet | .get_topic_tree(hierarchical_topics) |
| Visualiser les termes du sujet | .visualize_barchart() |
| Visualiser la similitude du sujet | .visualize_heatmap() |
| Visualiser le déclin du score à terme | .visualize_term_rank() |
| Visualiser la distribution des probabilités de sujet | .visualize_distribution(probs[0]) |
| Visualiser les sujets au fil du temps | .visualize_topics_over_time(topics_over_time) |
| Visualiser les sujets par classe | .visualize_topics_per_class(topics_per_class) |
Pour citer le papier bertopique, veuillez utiliser la référence Bibtex suivante:
@article{grootendorst2022bertopic,
title={BERTopic: Neural topic modeling with a class-based TF-IDF procedure},
author={Grootendorst, Maarten},
journal={arXiv preprint arXiv:2203.05794},
year={2022}
}


