BERTopic
v0.16.4

Bertopic ist eine Themenmodellierungstechnik, die nutzt? Transformatoren und C-TF-IDF, um dichte Cluster zu erstellen, die leicht interpretierbare Themen ermöglichen und gleichzeitig wichtige Wörter in den Themenbeschreibungen aufbewahren.
Bertopic unterstützt alle Arten von Themenmodellierungstechniken:
| Geführt | Beaufsichtigt | Halbübergreifend |
| Handbuch | Mehrfach-topische Verteilungen | Hierarchisch |
| Klassenbasierte | Dynamisch | Online/inkrementell |
| Multimodal | Multi-Aspekt | Textgenerierung/LLM |
| Null-Shot (neu!) | Modelle zusammenführen (neu!) | Samenwörter (neu!) |
Entsprechende mittlere Beiträge finden Sie hier und hier. Für einen detaillierteren Überblick können Sie das Papier lesen oder einen kurzen Überblick sehen.
Die Installation mit Satztransformen kann mit PYPI durchgeführt werden:
pip install bertopicWenn Sie Bertopic mit anderen Einbettungsmodellen installieren möchten, können Sie eine der folgenden Aussagen auswählen:
# Choose an embedding backend
pip install bertopic[flair,gensim,spacy,use]
# Topic modeling with images
pip install bertopic[vision]Für eine eingehende Übersicht über die Funktionen von Bertopic können Sie die vollständige Dokumentation überprüfen oder eines der folgenden Beispiele folgen:
| Name | Link |
|---|---|
| Beginnen Sie hier - Best Practices in Bertopic | |
| ? Neu! - Themenmodellierung auf großen Daten (GPU -Beschleunigung) | |
| ? Neu! - Thema Modellierung mit Lama 2? | |
| ? Neu! - Themenmodellierung mit quantisierten LLMs | |
| Themenmodellierung mit Bertopic | |
| (Benutzerdefinierte) Einbettungsmodelle in Bertopic | |
| Erweiterte Anpassung in Bertopic | |
| (semi-) beaufsichtigte Themenmodellierung mit Bertopic | |
| Dynamisches Thema Modellierung mit Trumps Tweets | |
| Themenmodellierung Arxiv Abstracts |
Wir beginnen damit, Themen aus dem bekannten 20 Newsgroups-Datensatz mit englischen Dokumenten zu extrahieren:
from bertopic import BERTopic
from sklearn . datasets import fetch_20newsgroups
docs = fetch_20newsgroups ( subset = 'all' , remove = ( 'headers' , 'footers' , 'quotes' ))[ 'data' ]
topic_model = BERTopic ()
topics , probs = topic_model . fit_transform ( docs )Nachdem wir Themen und deren Wahrscheinlichkeiten generiert haben, können wir zusammen mit ihren Themen Darstellungen auf alle Themen zugreifen:
> >> topic_model . get_topic_info ()
Topic Count Name
- 1 4630 - 1_ can_your_will_any
0 693 49_ windows_drive_dos_file
1 466 32_j esus_bible_christian_faith
2 441 2_ space_launch_orbit_lunar
3 381 22_ key_encryption_keys_encrypted
... Das Thema -1 bezieht sich auf alle Ausreißerdokumente und wird normalerweise ignoriert. Jedes Wort in einem Thema beschreibt das zugrunde liegende Thema dieses Themas und kann zur Interpretation dieses Themas verwendet werden. Schauen wir uns als nächstes das häufigste Thema an, das generiert wurde:
> >> topic_model . get_topic ( 0 )
[( 'windows' , 0.006152228076250982 ),
( 'drive' , 0.004982897610645755 ),
( 'dos' , 0.004845038866360651 ),
( 'file' , 0.004140142872194834 ),
( 'disk' , 0.004131678774810884 ),
( 'mac' , 0.003624848635985097 ),
( 'memory' , 0.0034840976976789903 ),
( 'software' , 0.0034415334250699077 ),
( 'email' , 0.0034239554442333257 ),
( 'pc' , 0.003047105930670237 )] Mit .get_document_info können wir auch Informationen auf einer Dokumentebene extrahieren, z. B. ihre entsprechenden Themen, Wahrscheinlichkeiten, unabhängig davon, ob es sich um repräsentative Dokumente für ein Thema usw.
> >> topic_model . get_document_info ( docs )
Document Topic Name Top_n_words Probability ...
I am sure some bashers of Pens ... 0 0_ game_team_games_season game - team - games ... 0.200010 ...
My brother is in the market for ... - 1 - 1_ can_your_will_any can - your - will ... 0.420668 ...
Finally you said what you dream ... - 1 - 1_ can_your_will_any can - your - will ... 0.807259 ...
Think ! It ' s the SCSI card doing ... 49 49_ windows_drive_dos_file windows - drive - docs ... 0.071746 ...
1 ) I have an old Jasmine drive ... 49 49_ windows_drive_dos_file windows - drive - docs ... 0.038983 ... Tip : Verwenden Sie BERTopic(language="multilingual") um ein Modell auszuwählen, das mehr als 50 Sprachen unterstützt.
In Bertopic gibt es eine Reihe verschiedener Themen Darstellungen, aus denen wir auswählen können. Sie unterscheiden sich alle ganz voneinander und geben interessante Perspektiven und Variationen von Themenrepräsentationen. Ein guter Start ist KeyBERTInspired , was für viele Benutzer die Kohärenz erhöht und die Stoppwörter aus den daraus resultierenden Themenrepräsentationen verringert:
from bertopic . representation import KeyBERTInspired
# Fine-tune your topic representations
representation_model = KeyBERTInspired ()
topic_model = BERTopic ( representation_model = representation_model )Möglicherweise möchten Sie jedoch etwas Mächtigeres verwenden, um Ihre Cluster zu beschreiben. Sie können sogar Chatgpt oder andere Modelle von OpenAI verwenden, um Etiketten, Zusammenfassungen, Phrasen, Schlüsselwörter und mehr zu generieren:
import openai
from bertopic . representation import OpenAI
# Fine-tune topic representations with GPT
client = openai . OpenAI ( api_key = "sk-..." )
representation_model = OpenAI ( client , model = "gpt-3.5-turbo" , chat = True )
topic_model = BERTopic ( representation_model = representation_model ) Tip : Anstatt all diese verschiedenen Themenrepräsentationen zu iterieren, können Sie sie gleichzeitig mit Multisparce-Themendarstellungen in Bertopic modellieren.
Nachdem wir unser Bertopic -Modell trainiert haben, können wir iterativ Hunderte von Themen durchlaufen, um ein gutes Verständnis für die extrahierten Themen zu erhalten. Dies dauert jedoch einige Zeit und fehlt eine globale Darstellung. Stattdessen können wir eine der vielen Visualisierungsoptionen in Bertopic verwenden. Zum Beispiel können wir die Themen visualisieren, die LDAVIS sehr ähnlich erzeugt wurden:
topic_model . visualize_topics ()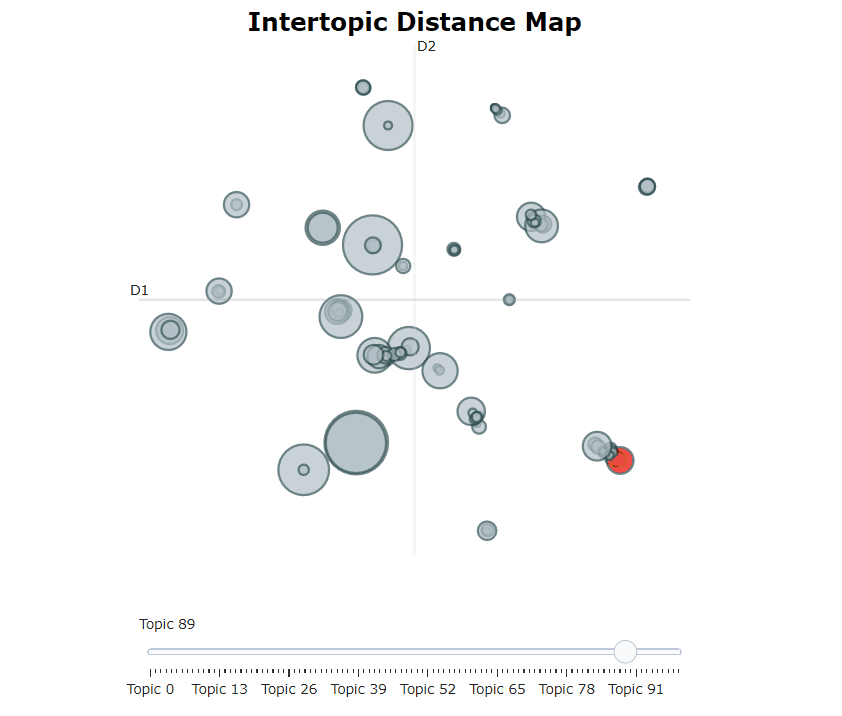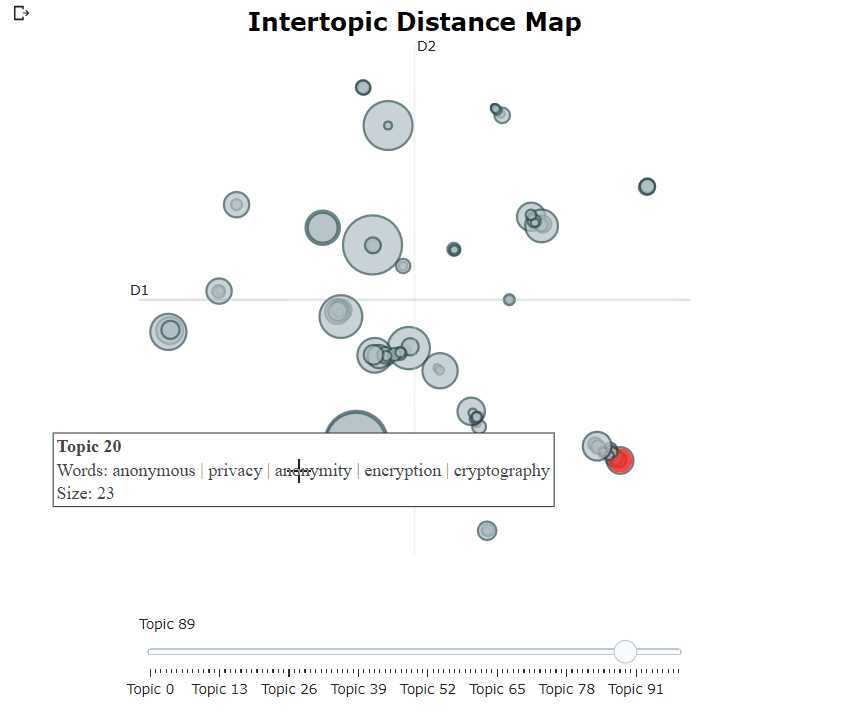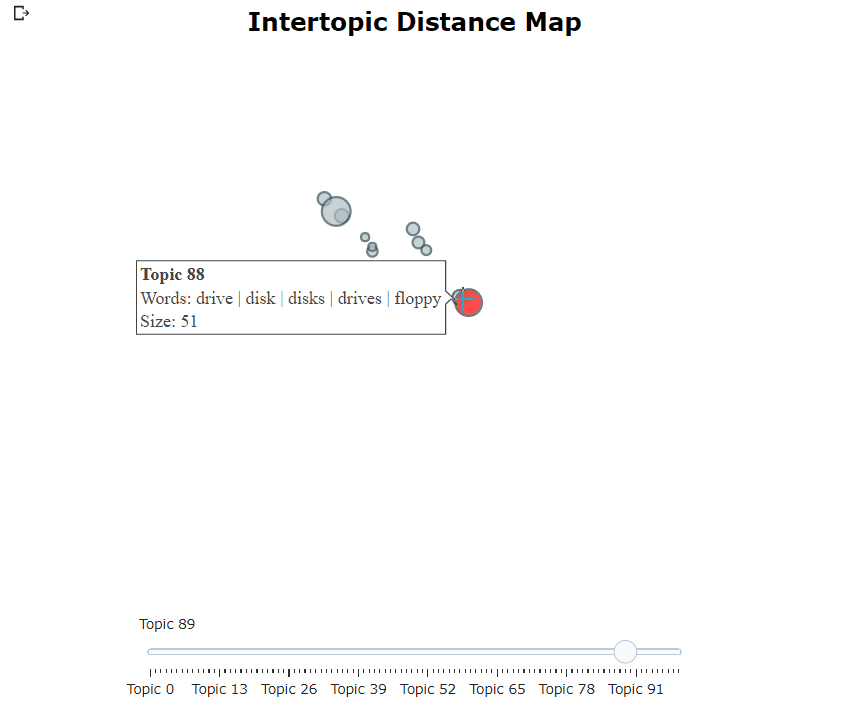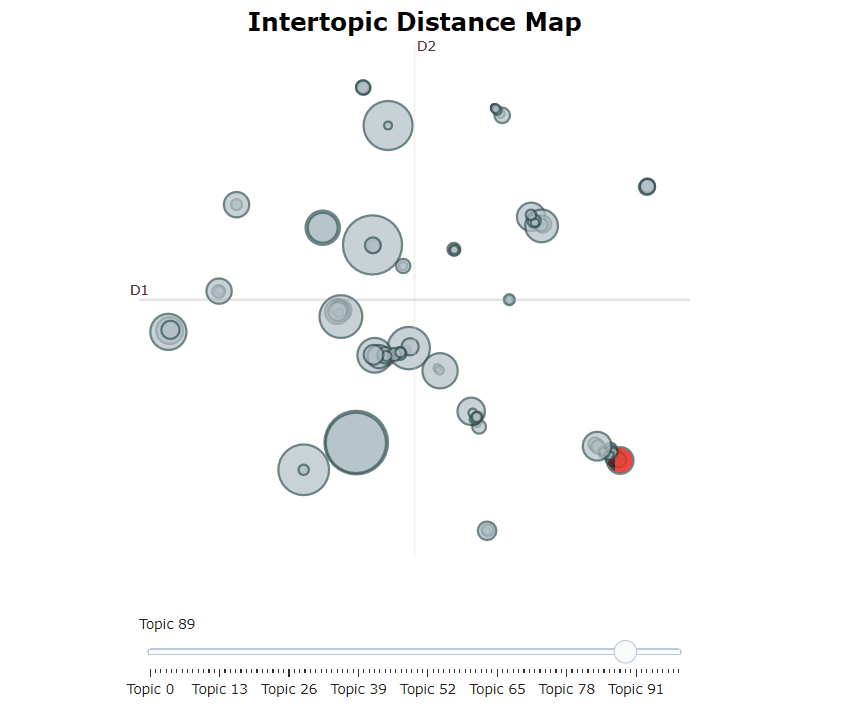
Standardmäßig sind die Hauptschritte für die Themenmodellierung mit Bertopic Satztransformer, UMAP, HDBSCAN und C-TF-IDF-Lauf nacheinander. Es wird jedoch eine gewisse Unabhängigkeit zwischen diesen Schritten vorausgesetzt, was Bertopic ziemlich modular macht. Mit anderen Worten, Bertopic ermöglicht es Ihnen nicht nur, Ihr eigenes Themenmodell zu erstellen, sondern auch mehrere Themenmodellierungstechniken auf Ihrem maßgeschneiderten Themenmodell zu untersuchen:
Sie können eines dieser Modelle austauschen oder sie sogar vollständig entfernen. Die folgenden Schritte sind vollständig modular:
Bertopic hat viele Funktionen, die schnell überwältigend werden können. Um dieses Problem zu lindern, finden Sie einen Überblick über alle Methoden und eine kurze Beschreibung seines Zwecks.
Im Folgenden finden Sie einen Überblick über gemeinsame Funktionen in Bertopic.
| Verfahren | Code |
|---|---|
| Passen Sie das Modell ein | .fit(docs) |
| Passen Sie das Modell an und prognostizieren Dokumente | .fit_transform(docs) |
| Neue Dokumente vorhersagen | .transform([new_doc]) |
| Zugriff auf ein einzelnes Thema | .get_topic(topic=12) |
| Zugreifen Sie auf alle Themen | .get_topics() |
| Erhalten Sie Thema Freq | .get_topic_freq() |
| Holen Sie sich alle Themeninformationen | .get_topic_info() |
| Holen Sie sich alle Dokumentinformationen | .get_document_info(docs) |
| Holen Sie sich repräsentative Dokumente pro Thema | .get_representative_docs() |
| Topic -Darstellung aktualisieren | .update_topics(docs, n_gram_range=(1, 3)) |
| Erstellen Sie Themenbezeichnungen | .generate_topic_labels() |
| Setzen Sie Themenbezeichnungen | .set_topic_labels(my_custom_labels) |
| Themen zusammenführen | .merge_topics(docs, topics_to_merge) |
| NR von Themen reduzieren | .reduce_topics(docs, nr_topics=30) |
| Ausreißer reduzieren | .reduce_outliers(docs, topics) |
| Finden Sie Themen | .find_topics("vehicle") |
| Modell speichern | .save("my_model", serialization="safetensors") |
| Lastmodell | BERTopic.load("my_model") |
| Parameter erhalten | .get_params() |
Nachdem Sie Ihr Bertopic -Modell trainiert haben, werden in Ihrem Modell mehrere Attribute gespeichert. Diese Attribute beziehen sich teilweise darauf, wie Modellinformationen während eines Schätzers während der Anpassung gespeichert werden. Die Attribute, die Sie unten sehen, enden in _ und sind öffentliche Attribute, die zum Zugriff auf Modellinformationen verwendet werden können.
| Attribut | Beschreibung |
|---|---|
.topics_ | Die Themen, die für jedes Dokument nach dem Training oder der Aktualisierung des Themasmodells generiert werden. |
.probabilities_ | Die Wahrscheinlichkeiten, die für jedes Dokument generiert werden, wenn Hdbscan verwendet wird. |
.topic_sizes_ | Die Größe jedes Themas |
.topic_mapper_ | Eine Klasse zum Nachverfolgen von Themen und ihre Zuordnungen, die jederzeit zusammengeführt/reduziert werden. |
.topic_representations_ | Die Top -N- Begriffe pro Thema und ihre jeweiligen C-TF-IDF-Werte. |
.c_tf_idf_ | Die Themenmatrix, die durch C-TF-IDF berechnet wird. |
.topic_aspects_ | Die verschiedenen Aspekte oder Darstellungen jedes Themas. |
.topic_labels_ | Die Standardbezeichnungen für jedes Thema. |
.custom_labels_ | Benutzerdefinierte Beschriftungen für jedes Thema, wie er über .set_topic_labels generiert wurde. |
.topic_embeddings_ | Die Einbettungen für jedes Thema, wenn embedding_model verwendet wurde. |
.representative_docs_ | Die repräsentativen Dokumente für jedes Thema, wenn HDBSCAN verwendet wird. |
Es gibt viele verschiedene Anwendungsfälle, in denen die Themenmodellierung verwendet werden kann. Daher wurden verschiedene Variationen von Bertopic entwickelt, sodass ein Paket für viele Anwendungsfälle verwendet werden kann.
| Verfahren | Code |
|---|---|
| Themenverteilungsnäherung | .approximate_distribution(docs) |
| Online -Thema Modellierung | .partial_fit(doc) |
| Halbüberwachung Themenmodellierung | .fit(docs, y=y) |
| Beaufsichtigtes Themenmodellieren | .fit(docs, y=y) |
| Handbuchmodellierung | .fit(docs, y=y) |
| Multimodale Themamodellierung | .fit(docs, images=images) |
| Themenmodellierung pro Klasse | .topics_per_class(docs, classes) |
| Dynamische Themenmodellierung | .topics_over_time(docs, timestamps) |
| Hierarchische Themenmodellierung | .hierarchical_topics(docs) |
| Geführte Themenmodellierung | BERTopic(seed_topic_list=seed_topic_list) |
| Null-Shot-Themenmodellierung | BERTopic(zeroshot_topic_list=zeroshot_topic_list) |
| Mehrere Modelle zusammenführen | BERTopic.merge_models([topic_model_1, topic_model_2]) |
Die Bewertung von Themenmodellen kann aufgrund der subjektiven Bewertung ziemlich schwierig sein. Das Visualisieren verschiedener Aspekte des Themasmodells hilft beim Verständnis des Modells und erleichtert es, das Modell nach Ihren Wünschen zu optimieren.
| Verfahren | Code |
|---|---|
| Themen visualisieren | .visualize_topics() |
| Dokumente visualisieren | .visualize_documents() |
| Visualisieren Sie die Dokumenthierarchie | .visualize_hierarchical_documents() |
| Themenhierarchie visualisieren | .visualize_hierarchy() |
| Visualisieren Sie den Themenbaum | .get_topic_tree(hierarchical_topics) |
| Visualisieren Sie Themenbegriffe | .visualize_barchart() |
| Topic -Ähnlichkeit visualisieren | .visualize_heatmap() |
| Visualisieren Sie die Begriffsbewertung ab Rückgang | .visualize_term_rank() |
| Visualisieren Sie Themenwahrscheinlichkeitsverteilung | .visualize_distribution(probs[0]) |
| Visualisieren Sie Themen im Laufe der Zeit | .visualize_topics_over_time(topics_over_time) |
| Visualisieren Sie Themen pro Klasse | .visualize_topics_per_class(topics_per_class) |
Um das Bertopic -Papier zu zitieren, verwenden Sie bitte die folgende Bibtex -Referenz:
@article{grootendorst2022bertopic,
title={BERTopic: Neural topic modeling with a class-based TF-IDF procedure},
author={Grootendorst, Maarten},
journal={arXiv preprint arXiv:2203.05794},
year={2022}
}


