BERTopic
v0.16.4

Bertopic은 활용하는 주제 모델링 기술입니까? 트랜스포머와 C-TF-IDF는 조밀 한 클러스터를 만들어 쉽게 해석 가능한 주제를 허용하면서 주제 설명에서 중요한 단어를 유지합니다.
Bertopic은 모든 종류의 주제 모델링 기술을 지원합니다.
| 안내 | 감독 | 반 감독 |
| 수동 | 다소 주제 분포 | 계층 적 |
| 수업 기반 | 동적 | 온라인/증분 |
| 멀티 모달 | 다국적 관점 | 텍스트 생성/llm |
| 제로 샷 (New!) | 병합 모델 (NEW!) | 씨앗 단어 (새로운!) |
해당 중간 게시물은 여기, 여기 및 여기에서 찾을 수 있습니다. 보다 자세한 개요는 논문을 읽거나 간단한 개요를 볼 수 있습니다.
문장 변환기와 함께 설치는 PYPI를 사용하여 수행 할 수 있습니다.
pip install bertopic다른 임베딩 모델과 함께 Bertopic을 설치하려면 다음 중 하나를 선택할 수 있습니다.
# Choose an embedding backend
pip install bertopic[flair,gensim,spacy,use]
# Topic modeling with images
pip install bertopic[vision]Bertopic의 기능에 대한 심층적 인 개요는 전체 문서를 확인하거나 아래 예제 중 하나를 따라갈 수 있습니다.
| 이름 | 링크 |
|---|---|
| 여기에서 시작하십시오 - Bertopic의 모범 사례 | |
| ? 새로운! - 큰 데이터에 대한 주제 모델링 (GPU 가속도) | |
| ? 새로운! -Llama 2를 사용한 주제 모델링? | |
| ? 새로운! - 양자화 된 LLM을 가진 주제 모델링 | |
| Bertopic을 사용한 주제 모델링 | |
| (커스텀) Bertopic에 모델 임베딩 모델 | |
| Bertopic의 고급 사용자 정의 | |
| (반) Bertopic을 사용한 감독 주제 모델링 | |
| 트럼프의 트윗을 사용한 동적 주제 모델링 | |
| 주제 모델링 ARXIV 초록 |
우리는 영어 문서가 포함 된 잘 알려진 20 개의 뉴스 그룹 데이터 세트에서 주제를 추출하는 것으로 시작합니다.
from bertopic import BERTopic
from sklearn . datasets import fetch_20newsgroups
docs = fetch_20newsgroups ( subset = 'all' , remove = ( 'headers' , 'footers' , 'quotes' ))[ 'data' ]
topic_model = BERTopic ()
topics , probs = topic_model . fit_transform ( docs )주제와 확률을 생성 한 후 주제 표현과 함께 모든 주제에 액세스 할 수 있습니다.
> >> topic_model . get_topic_info ()
Topic Count Name
- 1 4630 - 1_ can_your_will_any
0 693 49_ windows_drive_dos_file
1 466 32_j esus_bible_christian_faith
2 441 2_ space_launch_orbit_lunar
3 381 22_ key_encryption_keys_encrypted
... -1 주제는 모든 이상치 문서를 나타냅니다. 일반적으로 무시됩니다. 주제의 각 단어는 해당 주제의 기본 주제를 설명하며 해당 주제를 해석하는 데 사용할 수 있습니다. 다음으로 생성 된 가장 빈번한 주제를 살펴 보겠습니다.
> >> topic_model . get_topic ( 0 )
[( 'windows' , 0.006152228076250982 ),
( 'drive' , 0.004982897610645755 ),
( 'dos' , 0.004845038866360651 ),
( 'file' , 0.004140142872194834 ),
( 'disk' , 0.004131678774810884 ),
( 'mac' , 0.003624848635985097 ),
( 'memory' , 0.0034840976976789903 ),
( 'software' , 0.0034415334250699077 ),
( 'email' , 0.0034239554442333257 ),
( 'pc' , 0.003047105930670237 )] .get_document_info 사용하면 해당 주제, 확률, 주제에 대한 대표적인 문서 등과 같은 문서 수준에서 정보를 추출 할 수도 있습니다.
> >> topic_model . get_document_info ( docs )
Document Topic Name Top_n_words Probability ...
I am sure some bashers of Pens ... 0 0_ game_team_games_season game - team - games ... 0.200010 ...
My brother is in the market for ... - 1 - 1_ can_your_will_any can - your - will ... 0.420668 ...
Finally you said what you dream ... - 1 - 1_ can_your_will_any can - your - will ... 0.807259 ...
Think ! It ' s the SCSI card doing ... 49 49_ windows_drive_dos_file windows - drive - docs ... 0.071746 ...
1 ) I have an old Jasmine drive ... 49 49_ windows_drive_dos_file windows - drive - docs ... 0.038983 ... Tip : BERTopic(language="multilingual") 사용하여 50 개 이상의 언어를 지원하는 모델을 선택하십시오.
Bertopic에는 선택할 수있는 여러 가지 주제 표현이 있습니다. 그것들은 서로 상당히 다르며 주제 표현의 흥미로운 관점과 변형을 제공합니다. 좋은 시작은 KeyBERTInspired , 많은 사용자에게 일관성을 높이고 결과 주제 표현에서 스톱워드를 줄입니다.
from bertopic . representation import KeyBERTInspired
# Fine-tune your topic representations
representation_model = KeyBERTInspired ()
topic_model = BERTopic ( representation_model = representation_model )그러나 클러스터를 설명하기 위해 더 강력한 것을 사용하고 싶을 수도 있습니다. OpenAI의 ChatGpt 또는 기타 모델을 사용하여 레이블, 요약, 문구, 키워드 등을 생성 할 수도 있습니다.
import openai
from bertopic . representation import OpenAI
# Fine-tune topic representations with GPT
client = openai . OpenAI ( api_key = "sk-..." )
representation_model = OpenAI ( client , model = "gpt-3.5-turbo" , chat = True )
topic_model = BERTopic ( representation_model = representation_model ) Tip : 이러한 다양한 주제 표현을 모두 반복하는 대신 Bertopic의 다중 관점 주제 표현과 동시에 모델링 할 수 있습니다.
Bertopic 모델을 훈련 한 후, 우리는 수백 가지 주제를 반복하여 추출한 주제를 잘 이해할 수 있습니다. 그러나 시간이 많이 걸리고 전 세계적으로 표현이 부족합니다. 대신, 우리는 Bertopic에서 많은 시각화 옵션 중 하나를 사용할 수 있습니다. 예를 들어, 우리는 ldavis와 매우 유사한 방식으로 생성 된 주제를 시각화 할 수 있습니다.
topic_model . visualize_topics ()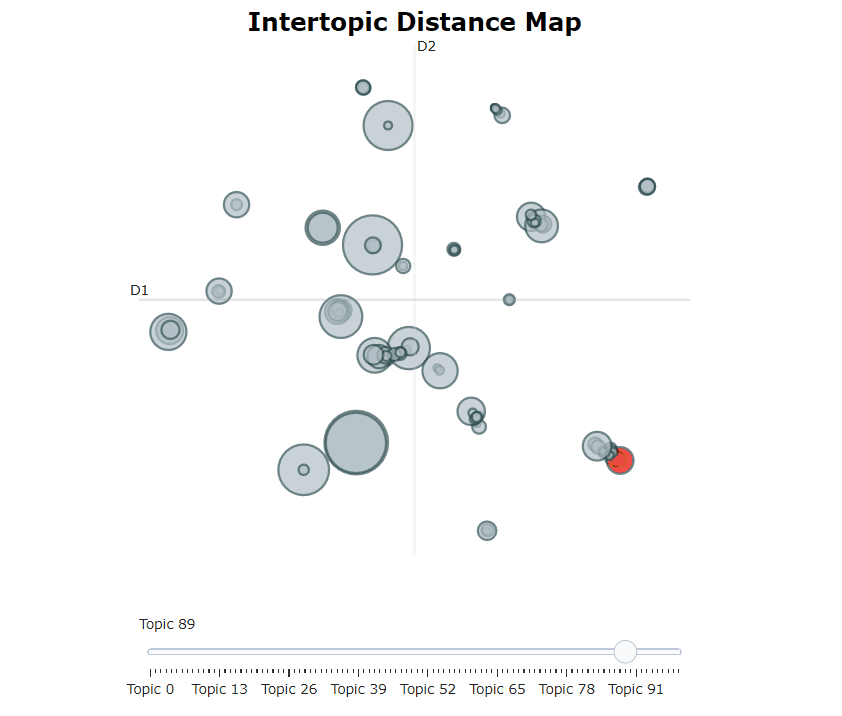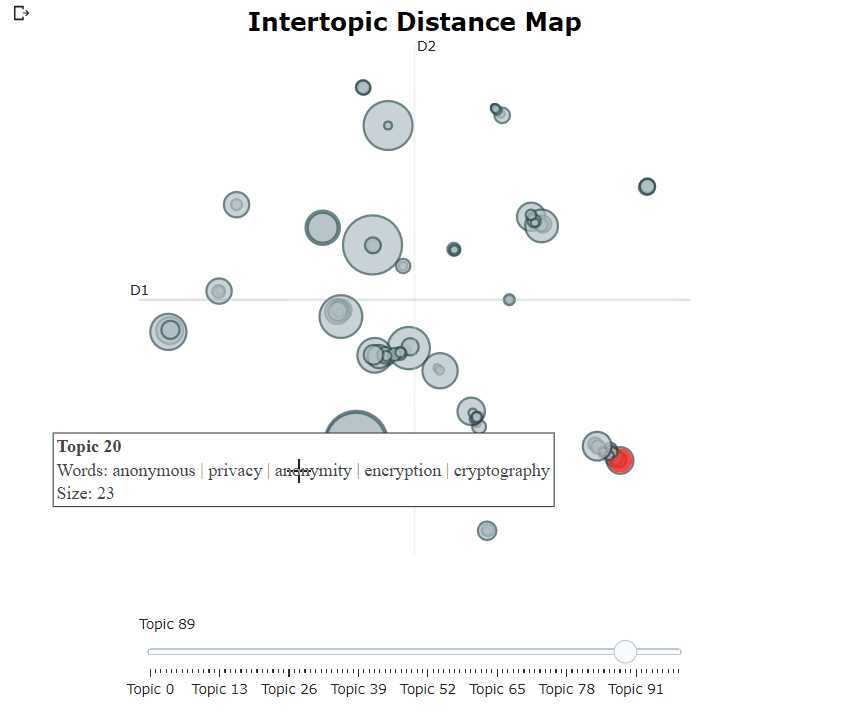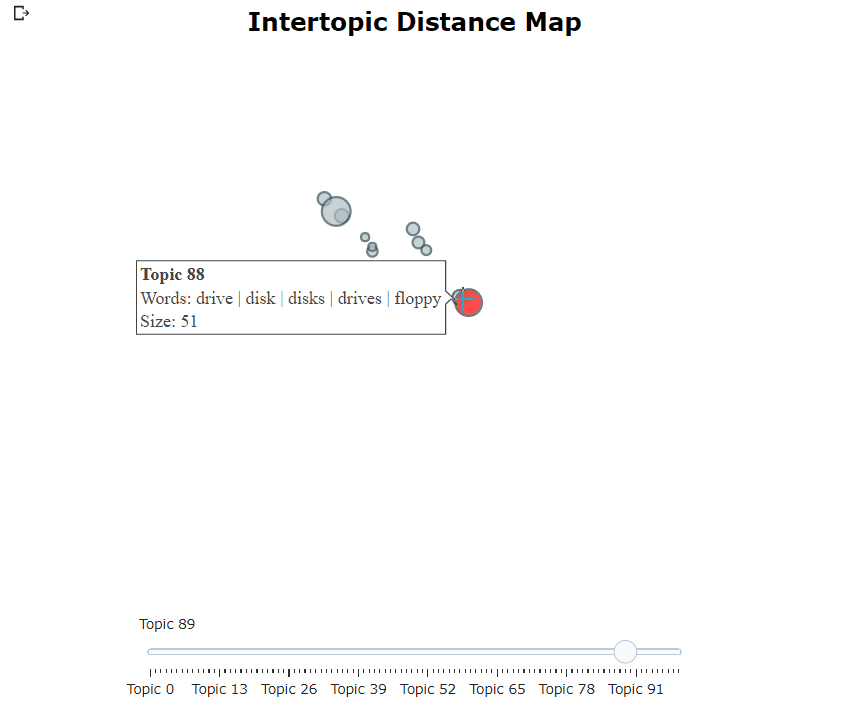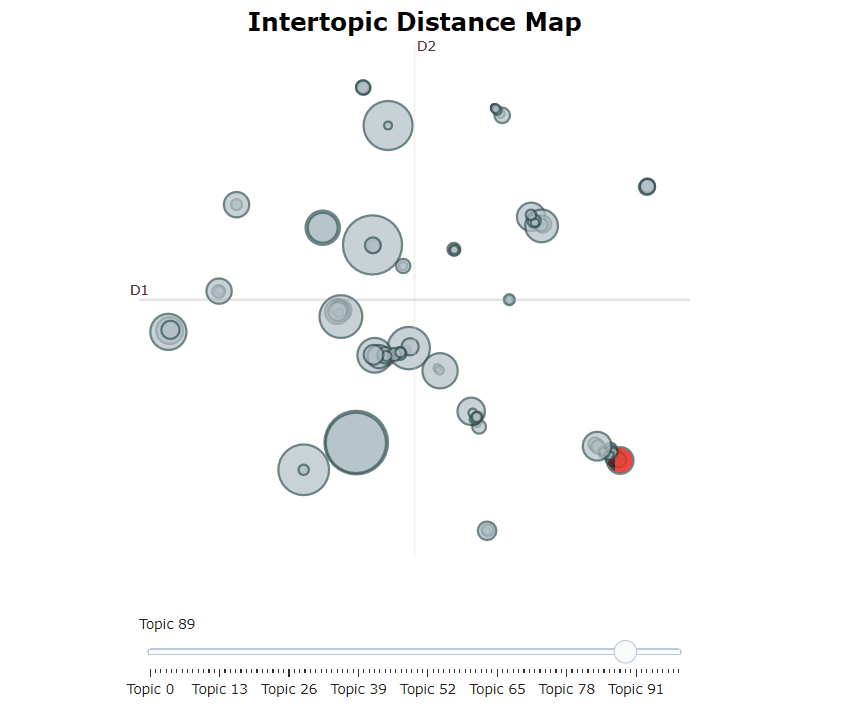
기본적으로 Bertopic을 사용한 주제 모델링의 주요 단계는 문장 전환기, UMAP, HDBSCAN 및 C-TF-IDF가 순서대로 실행됩니다. 그러나이 단계들 사이의 독립성을 가정하여 Bertopic을 상당히 모듈화합니다. 다시 말해, Bertopic은 자신의 주제 모델을 구축 할 수있을뿐만 아니라 맞춤형 주제 모델 위에 여러 주제 모델링 기술을 탐색 할 수 있습니다.
이러한 모델을 교체하거나 완전히 제거 할 수도 있습니다. 다음 단계는 완전히 모듈 식입니다.
Bertopic은 압도적이 될 수있는 많은 기능을 가지고 있습니다. 이 문제를 완화하기 위해 모든 방법에 대한 개요와 그 목적에 대한 간단한 설명이 있습니다.
아래에서는 Bertopic에서 일반적인 기능에 대한 개요를 찾을 수 있습니다.
| 방법 | 암호 |
|---|---|
| 모델에 맞습니다 | .fit(docs) |
| 모델에 맞고 문서를 예측하십시오 | .fit_transform(docs) |
| 새로운 문서를 예측하십시오 | .transform([new_doc]) |
| 단일 주제에 액세스하십시오 | .get_topic(topic=12) |
| 모든 주제에 액세스하십시오 | .get_topics() |
| 주제를 얻으십시오 | .get_topic_freq() |
| 모든 주제 정보를 얻으십시오 | .get_topic_info() |
| 모든 문서 정보를 얻으십시오 | .get_document_info(docs) |
| 주제 당 대표 문서를 받으십시오 | .get_representative_docs() |
| 주제 표현을 업데이트하십시오 | .update_topics(docs, n_gram_range=(1, 3)) |
| 주제 레이블을 생성합니다 | .generate_topic_labels() |
| 주제 레이블을 설정하십시오 | .set_topic_labels(my_custom_labels) |
| 주제를 병합하십시오 | .merge_topics(docs, topics_to_merge) |
| 주제의 NR을 줄입니다 | .reduce_topics(docs, nr_topics=30) |
| 이상치를 줄입니다 | .reduce_outliers(docs, topics) |
| 주제를 찾으십시오 | .find_topics("vehicle") |
| 모델 저장 | .save("my_model", serialization="safetensors") |
| 로드 모델 | BERTopic.load("my_model") |
| 매개 변수를 얻으십시오 | .get_params() |
Bertopic 모델을 교육 한 후 모델 내에 몇 가지 속성이 저장됩니다. 이러한 속성은 부분적으로 모델 정보가 피팅 중에 추정기에 저장되는 방법을 나타냅니다. 아래에있는 속성은 _ 의 모든 끝이며 모델 정보에 액세스하는 데 사용할 수있는 공개 속성입니다.
| 기인하다 | 설명 |
|---|---|
.topics_ | 주제 모델을 교육하거나 업데이트 한 후 각 문서에 대해 생성 된 주제. |
.probabilities_ | HDBSCAN을 사용하는 경우 각 문서에 대해 생성되는 확률. |
.topic_sizes_ | 각 주제의 크기 |
.topic_mapper_ | 주제를 추적하기위한 클래스와 합병/축소 될 때마다 매핑. |
.topic_representations_ | 주제 당 상단 N 항 및 해당 C-TF-IDF 값. |
.c_tf_idf_ | C-TF-IDF를 통해 계산 된 주제 행렬. |
.topic_aspects_ | 각 주제의 다른 측면 또는 표현. |
.topic_labels_ | 각 주제에 대한 기본 레이블. |
.custom_labels_ | .set_topic_labels 를 통해 생성 된 각 주제에 대한 사용자 정의 레이블. |
.topic_embeddings_ | embedding_model 사용한 경우 각 주제에 대한 임베딩. |
.representative_docs_ | HDBSCAN을 사용하는 경우 각 주제에 대한 대표적인 문서. |
주제 모델링을 사용할 수있는 다양한 사용 사례가 있습니다. 따라서, 여러 가지 사용 사례에서 하나의 패키지를 사용할 수 있도록 몇 가지 변형의 Bertopic이 개발되었습니다.
| 방법 | 암호 |
|---|---|
| 주제 분포 근사 | .approximate_distribution(docs) |
| 온라인 주제 모델링 | .partial_fit(doc) |
| 반 감독 주제 모델링 | .fit(docs, y=y) |
| 감독 된 주제 모델링 | .fit(docs, y=y) |
| 수동 주제 모델링 | .fit(docs, y=y) |
| 멀티 모달 주제 모델링 | .fit(docs, images=images) |
| 수업 당 주제 모델링 | .topics_per_class(docs, classes) |
| 동적 주제 모델링 | .topics_over_time(docs, timestamps) |
| 계층 적 주제 모델링 | .hierarchical_topics(docs) |
| 안내 주제 모델링 | BERTopic(seed_topic_list=seed_topic_list) |
| 제로 샷 주제 모델링 | BERTopic(zeroshot_topic_list=zeroshot_topic_list) |
| 여러 모델을 병합합니다 | BERTopic.merge_models([topic_model_1, topic_model_2]) |
평가의 주관적인 특성으로 인해 주제 모델을 평가하는 것이 다소 어려울 수 있습니다. 주제 모델의 다양한 측면을 시각화하면 모델을 이해하는 데 도움이되고 원하는 모델을보다 쉽게 조정할 수 있습니다.
| 방법 | 암호 |
|---|---|
| 주제를 시각화하십시오 | .visualize_topics() |
| 문서를 시각화하십시오 | .visualize_documents() |
| 문서 계층 구조를 시각화합니다 | .visualize_hierarchical_documents() |
| 주제 계층 구조를 시각화합니다 | .visualize_hierarchy() |
| 주제 트리를 시각화하십시오 | .get_topic_tree(hierarchical_topics) |
| 주제 용어를 시각화하십시오 | .visualize_barchart() |
| 주제 유사성을 시각화합니다 | .visualize_heatmap() |
| 용어 점수 감소를 시각화합니다 | .visualize_term_rank() |
| 주제 확률 분포를 시각화합니다 | .visualize_distribution(probs[0]) |
| 시간이 지남에 따라 주제를 시각화합니다 | .visualize_topics_over_time(topics_over_time) |
| 수업 당 주제를 시각화합니다 | .visualize_topics_per_class(topics_per_class) |
Bertopic 용지를 인용하려면 다음 Bibtex 참조를 사용하십시오.
@article{grootendorst2022bertopic,
title={BERTopic: Neural topic modeling with a class-based TF-IDF procedure},
author={Grootendorst, Maarten},
journal={arXiv preprint arXiv:2203.05794},
year={2022}
}


