promptsource
v0.2.3:
Promptsource เป็นชุดเครื่องมือสำหรับการสร้างการแบ่งปันและการใช้พรอมต์ภาษาธรรมชาติ
งานล่าสุดแสดงให้เห็นว่ารูปแบบภาษาขนาดใหญ่แสดงความสามารถในการดำเนินการทั่วไปที่สมเหตุสมผลเป็นศูนย์ให้กับงานใหม่ ตัวอย่างเช่น GPT-3 แสดงให้เห็นว่าแบบจำลองภาษาขนาดใหญ่มีความสามารถแบบศูนย์และไม่กี่ จากนั้น Flan และ T0 แสดงให้เห็นว่าแบบจำลองภาษาที่ผ่านการฝึกอบรมมาก่อนได้รับการปรับแต่งในแฟชั่นมัลติทาสก์อย่างมากทำให้ประสิทธิภาพการทำงานเป็นศูนย์ที่แข็งแกร่งยิ่งขึ้น ตัวหารร่วมในงานเหล่านี้คือการใช้พรอมต์ซึ่งได้รับความสนใจในหมู่นักวิจัยและวิศวกรของ NLP สิ่งนี้เน้นถึงความจำเป็นสำหรับเครื่องมือใหม่ในการสร้างแบ่งปันและใช้การแจ้งเตือนภาษาธรรมชาติ
พรอมต์เป็นฟังก์ชั่นที่แมปตัวอย่างจากชุดข้อมูลไปยังอินพุตภาษาธรรมชาติและเอาต์พุตเป้าหมาย Promptsource มีคอลเลกชันที่เพิ่มขึ้นของพรอมต์ (ซึ่งเราเรียกว่า p3 : p ublic p ool ของ p rompts) ณ วันที่ 20 มกราคม 2022 มีการแจ้งเตือนภาษาอังกฤษ ~ 2'000 สำหรับชุดข้อมูลภาษาอังกฤษ 170+ ใน P3
Promptsource จัดเตรียมเครื่องมือในการสร้างและแบ่งปันพรอมต์ภาษาธรรมชาติ (ดูวิธีการสร้างพรอมต์จากนั้นใช้พรอมต์ที่มีอยู่และสร้างใหม่หลายพันรายการผ่าน API ง่าย ๆ (ดูวิธีการใช้พรอมต์) การแจ้งเตือนจะถูกบันทึกไว้ในไฟล์โครงสร้างแบบสแตนด์อโลน
{{premise}}
Question: Does this imply that "{{hypothesis}}"? Yes, no, or maybe? ||| {{answer_choices[labe l] }}คุณสามารถเรียกดูพรอมต์ที่มีอยู่ในเวอร์ชันที่โฮสต์ของ PromptSource
หากคุณไม่ได้ตั้งใจที่จะสร้างพรอมต์ใหม่คุณสามารถเรียกใช้:
pip install promptsourceมิฉะนั้นคุณต้องติดตั้ง repo ในเครื่อง:
pip install -e . ในการติดตั้งโมดูล promptsource หมายเหตุ: ด้วยเหตุผลด้านความมั่นคงในขณะนี้คุณจะต้องมีสภาพแวดล้อม Python 3.7 เพื่อเรียกใช้ขั้นตอนสุดท้าย อย่างไรก็ตามหากคุณตั้งใจจะใช้พรอมต์เท่านั้นและไม่สร้างพรอมต์ใหม่ผ่านอินเทอร์เฟซคุณสามารถลบข้อ จำกัด นี้ใน setup.py และติดตั้งแพ็คเกจในเครื่อง
คุณสามารถใช้พรอมต์กับตัวอย่างจากชุดข้อมูลของไลบรารีชุดข้อมูล Hugging Face
# Load an example from the datasets ag_news
> >> from datasets import load_dataset
> >> dataset = load_dataset ( "ag_news" , split = "train" )
> >> example = dataset [ 1 ]
# Load prompts for this dataset
> >> from promptsource . templates import DatasetTemplates
> >> ag_news_prompts = DatasetTemplates ( 'ag_news' )
# Print all the prompts available for this dataset. The keys of the dict are the UUIDs the uniquely identify each of the prompt, and the values are instances of `Template` which wraps prompts
> >> print ( ag_news_prompts . templates )
{ '24e44a81-a18a-42dd-a71c-5b31b2d2cb39' : < promptsource . templates . Template object at 0x7fa7aeb20350 > , '8fdc1056-1029-41a1-9c67-354fc2b8ceaf' : < promptsource . templates . Template object at 0x7fa7aeb17c10 > , '918267e0-af68-4117-892d-2dbe66a58ce9' : < promptsource . templates . Template object at 0x7fa7ac7a2310 > , '9345df33-4f23-4944-a33c-eef94e626862' : < promptsource . templates . Template object at 0x7fa7ac7a2050 > , '98534347-fff7-4c39-a795-4e69a44791f7' : < promptsource . templates . Template object at 0x7fa7ac7a1310 > , 'b401b0ee-6ffe-4a91-8e15-77ee073cd858' : < promptsource . templates . Template object at 0x7fa7ac7a12d0 > , 'cb355f33-7e8c-4455-a72b-48d315bd4f60' : < promptsource . templates . Template object at 0x7fa7ac7a1110 > }
# Select a prompt by its name
>> > prompt = ag_news_prompts [ "classify_question_first" ]
# Apply the prompt to the example
>> > result = prompt . apply ( example )
>> > print ( "INPUT: " , result [ 0 ])
INPUT : What label best describes this news article ?
Carlyle Looks Toward Commercial Aerospace ( Reuters ) Reuters - Private investment firm Carlyle Group , which has a reputation for making well - timed and occasionally controversial plays in the defense industry , has quietly placed its bets on another part of the market .
> >> print ( "TARGET: " , result [ 1 ])
TARGET : Businessในกรณีที่คุณกำลังมองหาพรอมต์ที่มีอยู่สำหรับชุดย่อยเฉพาะของชุดข้อมูลคุณควรใช้ไวยากรณ์ต่อไปนี้:
dataset_name , subset_name = "super_glue" , "rte"
dataset = load_dataset ( f" { dataset_name } / { subset_name } " , split = "train" )
example = dataset [ 0 ]
prompts = DatasetTemplates ( f" { dataset_name } / { subset_name } " )คุณยังสามารถรวบรวมพรอมต์ที่มีอยู่ทั้งหมดสำหรับชุดข้อมูลที่เกี่ยวข้อง:
> >> from promptsource . templates import TemplateCollection
# Get all the prompts available in PromptSource
> >> collection = TemplateCollection ()
# Print a dict where the key is the pair (dataset name, subset name)
# and the value is an instance of DatasetTemplates
> >> print ( collection . datasets_templates )
{( 'poem_sentiment' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7939d0 > , ( 'common_gen' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac795410 > , ( 'anli' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac794590 > , ( 'cc_news' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac798a90 > , ( 'craigslist_bargains' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7a2c10 > ,...}คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับ API ของ Promptsource เพื่อจัดเก็บจัดการและใช้พรอมต์ในเอกสาร
Promptsource จัดเตรียม GUI บนเว็บที่ช่วยให้นักพัฒนาสามารถเขียนพรอมต์ในภาษาเทมเพลตและดูผลลัพธ์ของพวกเขาในตัวอย่างที่แตกต่างกันทันที
มี 3 โหมดในแอพ:
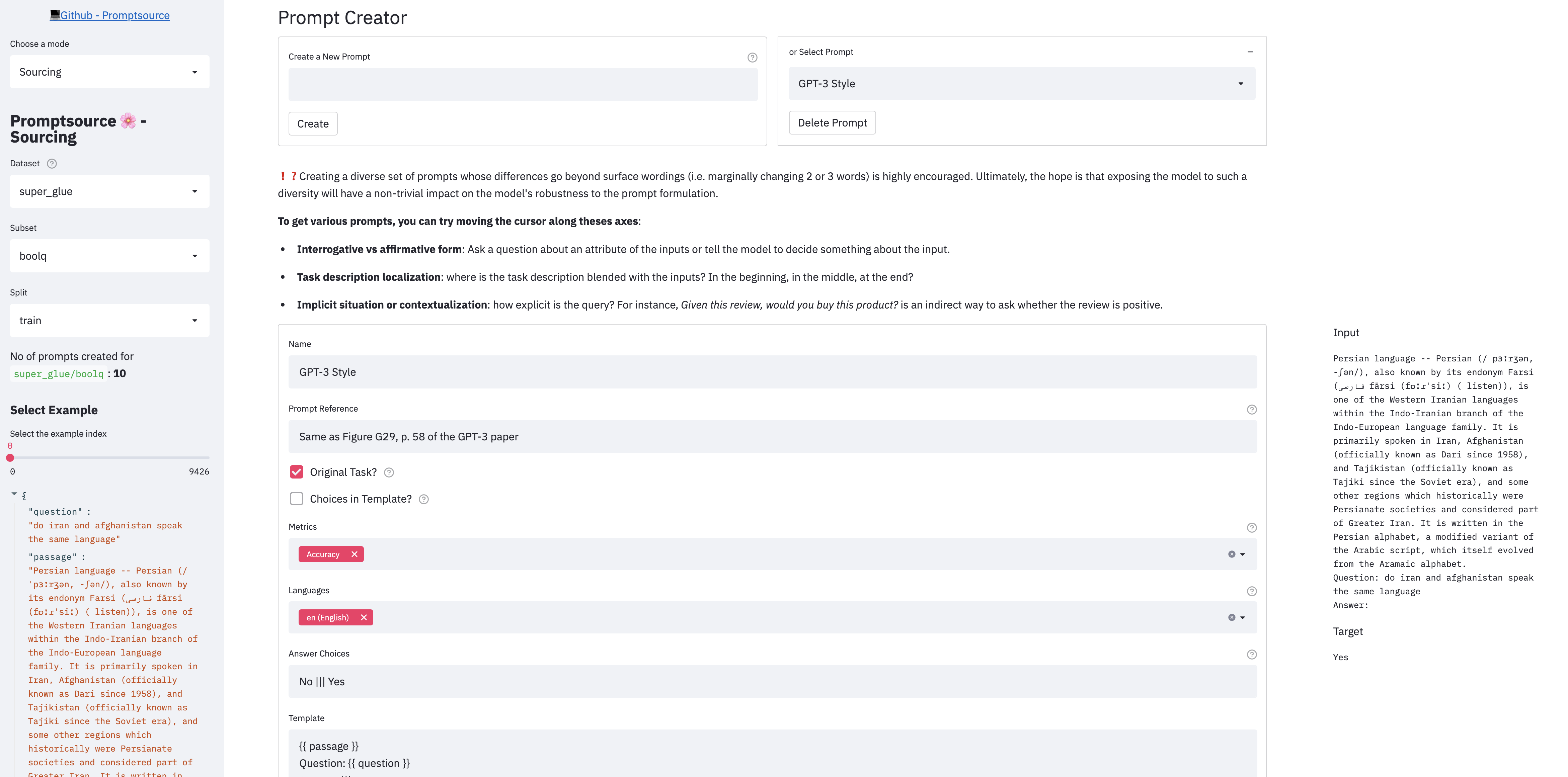
ในการเปิดใช้งานแอพในพื้นที่โปรดตรวจสอบให้แน่ใจก่อนว่าคุณได้ทำตามขั้นตอนในการตั้งค่าและจากไดเรกทอรีรากของ repo run:
streamlit run promptsource/app.py นอกจากนี้คุณยังสามารถเรียกดูพรอมต์ที่มีอยู่ในเวอร์ชันที่โฮสต์ของ PromptSource หมายเหตุเวอร์ชันที่โฮสต์ปิดใช้งานโหมดการจัดหา ( streamlit run promptsource/app.py -- --read-only )
ก่อนที่จะสร้างพรอมต์ใหม่คุณควรอ่านแนวทางการบริจาคซึ่งให้คำอธิบายทีละขั้นตอนเกี่ยวกับวิธีการมีส่วนร่วมในการรวบรวมพรอมต์
ชุดข้อมูลบางชุดไม่ได้รับการจัดการโดยอัตโนมัติโดย datasets และกำหนดให้ผู้ใช้ดาวน์โหลดชุดข้อมูลด้วยตนเอง ( story_cloze เป็นต้น)
ในการจัดการชุดข้อมูลเหล่านั้นเช่นกันเราต้องการให้ผู้ใช้ดาวน์โหลดชุดข้อมูลและใส่ไว้ใน ~/.cache/promptsource นี่คือไดเรกทอรีรากที่มีชุดข้อมูลที่ดาวน์โหลดด้วยตนเองทั้งหมด
คุณสามารถแทนที่เส้นทางเริ่มต้นนี้โดยใช้ตัวแปรสภาพแวดล้อม PROMPTSOURCE_MANUAL_DATASET_DIR สิ่งนี้ควรชี้ไปที่ไดเรกทอรีราก
Promptsource และ P3 ได้รับการพัฒนา แต่เดิมเป็นส่วนหนึ่งของโครงการ BigScience สำหรับการวิจัยแบบเปิด? ซึ่งเป็นโครงการริเริ่มตลอดทั้งปีที่กำหนดเป้าหมายการศึกษาแบบจำลองและชุดข้อมูลขนาดใหญ่ เป้าหมายของโครงการคือการวิจัยแบบจำลองภาษาในสภาพแวดล้อมสาธารณะนอก บริษัท เทคโนโลยีขนาดใหญ่ โครงการมีนักวิจัย 600 คนจาก 50 ประเทศและมากกว่า 250 สถาบัน
โดยเฉพาะอย่างยิ่ง Promptsource และ P3 เป็นขั้นตอนแรกสำหรับการทำงานหลายอย่างของกระดาษที่ได้รับแจ้งการฝึกอบรมช่วยให้การจัดงานแบบไม่มีการยิง
คุณจะพบที่เก็บอย่างเป็นทางการเพื่อทำซ้ำผลลัพธ์ของบทความที่นี่: https://github.com/bigscience-workshop/t-zero นอกจากนี้เรายังเปิดตัว T0* (ออกเสียง "T Zero") ชุดของรุ่นที่ผ่านการฝึกอบรมเกี่ยวกับ P3 และนำเสนอในกระดาษ มีจุดตรวจที่นี่
คำเตือนหรือข้อผิดพลาดเกี่ยวกับดาร์วินบน OS X: ลองลดระดับ Pyarrow เป็น 3.0.0
ConnectionRefusedError: [Errno 61] การเชื่อมต่อปฏิเสธ: เกิดขึ้นเป็นครั้งคราว ลองรีสตาร์ทแอป
หากคุณพบว่า P3 หรือ PromptSource มีประโยชน์โปรดอ้างอิงการอ้างอิงต่อไปนี้:
@misc { bach2022promptsource ,
title = { PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts } ,
author = { Stephen H. Bach and Victor Sanh and Zheng-Xin Yong and Albert Webson and Colin Raffel and Nihal V. Nayak and Abheesht Sharma and Taewoon Kim and M Saiful Bari and Thibault Fevry and Zaid Alyafeai and Manan Dey and Andrea Santilli and Zhiqing Sun and Srulik Ben-David and Canwen Xu and Gunjan Chhablani and Han Wang and Jason Alan Fries and Maged S. Al-shaibani and Shanya Sharma and Urmish Thakker and Khalid Almubarak and Xiangru Tang and Xiangru Tang and Mike Tian-Jian Jiang and Alexander M. Rush } ,
year = { 2022 } ,
eprint = { 2202.01279 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

