promptsource
v0.2.3:
PromptSource adalah toolkit untuk membuat, berbagi, dan menggunakan petunjuk bahasa alami.
Karya terbaru menunjukkan bahwa model bahasa besar menunjukkan kemampuan untuk melakukan generalisasi nol-shot yang masuk akal untuk tugas-tugas baru. Misalnya, GPT-3 menunjukkan bahwa model bahasa besar memiliki kemampuan nol yang kuat dan beberapa shot. FLAN dan T0 kemudian menunjukkan bahwa model bahasa pra-terlatih disempurnakan dalam fashion multitask besar-besaran menghasilkan kinerja nol-shot yang lebih kuat. Penyebut umum dalam karya -karya ini adalah penggunaan petunjuk yang telah mendapatkan minat di antara para peneliti dan insinyur NLP. Ini menekankan perlunya alat baru untuk membuat, berbagi, dan menggunakan petunjuk bahasa alami.
Prompt adalah fungsi yang memetakan contoh dari dataset ke input bahasa alami dan output target. Promptsource berisi koleksi prompt yang semakin besar (yang kami sebut P3 : p ublic p ool dari pangkul ). Pada 20 Januari 2022, ada ~ 2'000 permintaan bahasa Inggris untuk 170+ set data bahasa Inggris di P3.
PromptSource menyediakan alat untuk membuat, dan berbagi petunjuk bahasa alami (lihat cara membuat petunjuk, dan kemudian menggunakan ribuan petunjuk yang ada dan yang baru dibuat melalui API sederhana (lihat cara menggunakan petunjuk). Prompt disimpan dalam file terstruktur mandiri dan ditulis dalam bahasa templating sederhana yang disebut jinja. Contoh dari yang tersedia di Snlice untuk Snli adalah bahasa Templating yang disebut jinja. Contoh yang tersedia di SNLICE SNLI adalah: JINJA.
{{premise}}
Question: Does this imply that "{{hypothesis}}"? Yes, no, or maybe? ||| {{answer_choices[labe l] }}Anda dapat menelusuri petunjuk yang ada pada versi promptsource yang di -host.
Jika Anda tidak bermaksud membuat prompt baru, Anda dapat menjalankan:
pip install promptsourceJika tidak, Anda perlu menginstal repo secara lokal:
pip install -e . untuk menginstal modul promptsource Catatan: Untuk alasan stabilitas, saat ini Anda akan membutuhkan lingkungan Python 3.7 untuk menjalankan langkah terakhir. Namun, jika Anda hanya bermaksud menggunakan prompt, dan tidak membuat prompt baru melalui antarmuka, Anda dapat menghapus kendala ini di setup.py dan instal paket secara lokal.
Anda dapat menerapkan prompt untuk contoh dari kumpulan data perpustakaan Dataset Wajah Memeluk.
# Load an example from the datasets ag_news
> >> from datasets import load_dataset
> >> dataset = load_dataset ( "ag_news" , split = "train" )
> >> example = dataset [ 1 ]
# Load prompts for this dataset
> >> from promptsource . templates import DatasetTemplates
> >> ag_news_prompts = DatasetTemplates ( 'ag_news' )
# Print all the prompts available for this dataset. The keys of the dict are the UUIDs the uniquely identify each of the prompt, and the values are instances of `Template` which wraps prompts
> >> print ( ag_news_prompts . templates )
{ '24e44a81-a18a-42dd-a71c-5b31b2d2cb39' : < promptsource . templates . Template object at 0x7fa7aeb20350 > , '8fdc1056-1029-41a1-9c67-354fc2b8ceaf' : < promptsource . templates . Template object at 0x7fa7aeb17c10 > , '918267e0-af68-4117-892d-2dbe66a58ce9' : < promptsource . templates . Template object at 0x7fa7ac7a2310 > , '9345df33-4f23-4944-a33c-eef94e626862' : < promptsource . templates . Template object at 0x7fa7ac7a2050 > , '98534347-fff7-4c39-a795-4e69a44791f7' : < promptsource . templates . Template object at 0x7fa7ac7a1310 > , 'b401b0ee-6ffe-4a91-8e15-77ee073cd858' : < promptsource . templates . Template object at 0x7fa7ac7a12d0 > , 'cb355f33-7e8c-4455-a72b-48d315bd4f60' : < promptsource . templates . Template object at 0x7fa7ac7a1110 > }
# Select a prompt by its name
>> > prompt = ag_news_prompts [ "classify_question_first" ]
# Apply the prompt to the example
>> > result = prompt . apply ( example )
>> > print ( "INPUT: " , result [ 0 ])
INPUT : What label best describes this news article ?
Carlyle Looks Toward Commercial Aerospace ( Reuters ) Reuters - Private investment firm Carlyle Group , which has a reputation for making well - timed and occasionally controversial plays in the defense industry , has quietly placed its bets on another part of the market .
> >> print ( "TARGET: " , result [ 1 ])
TARGET : BusinessDalam hal Anda mencari petunjuk yang tersedia untuk subset tertentu dari dataset, Anda harus menggunakan sintaks berikut:
dataset_name , subset_name = "super_glue" , "rte"
dataset = load_dataset ( f" { dataset_name } / { subset_name } " , split = "train" )
example = dataset [ 0 ]
prompts = DatasetTemplates ( f" { dataset_name } / { subset_name } " )Anda juga dapat mengumpulkan semua prompt yang tersedia untuk set data terkait:
> >> from promptsource . templates import TemplateCollection
# Get all the prompts available in PromptSource
> >> collection = TemplateCollection ()
# Print a dict where the key is the pair (dataset name, subset name)
# and the value is an instance of DatasetTemplates
> >> print ( collection . datasets_templates )
{( 'poem_sentiment' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7939d0 > , ( 'common_gen' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac795410 > , ( 'anli' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac794590 > , ( 'cc_news' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac798a90 > , ( 'craigslist_bargains' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7a2c10 > ,...}Anda dapat mempelajari lebih lanjut tentang API Promptsource untuk menyimpan, memanipulasi, dan menggunakan prompt dalam dokumentasi.
PromptSource menyediakan GUI berbasis web yang memungkinkan pengembang untuk menulis prompt dalam bahasa templating dan segera melihat output mereka pada berbagai contoh.
Ada 3 mode di aplikasi:
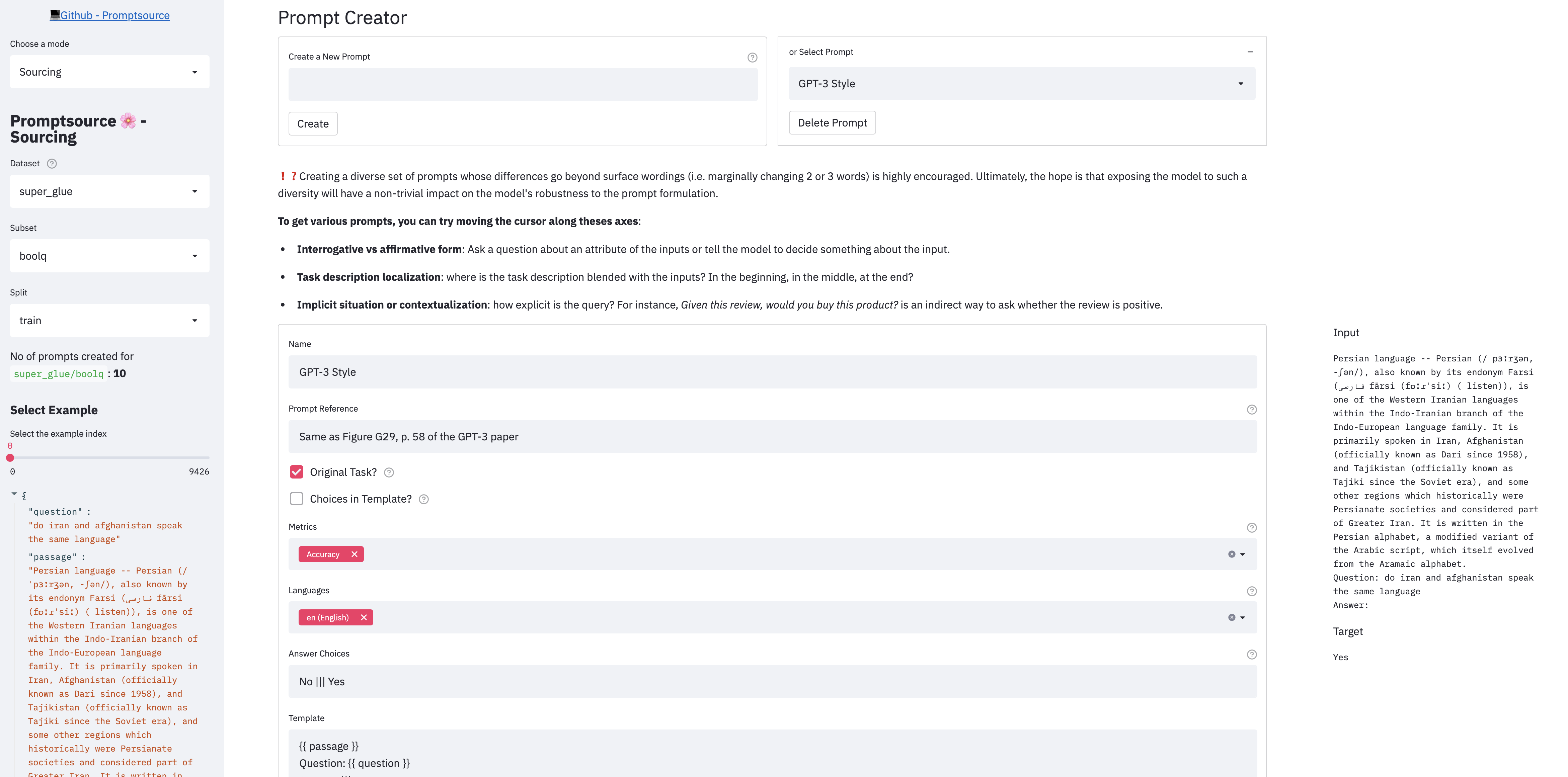
Untuk meluncurkan aplikasi secara lokal, harap pertama -tama pastikan Anda telah mengikuti langkah -langkah dalam pengaturan, dan dari direktori root repo, jalankan:
streamlit run promptsource/app.py Anda juga dapat menelusuri permintaan yang ada pada versi promptsource yang di -host. Catatan versi yang di-host menonaktifkan mode sumber ( streamlit run promptsource/app.py -- --read-only ).
Sebelum membuat petunjuk baru, Anda harus membaca pedoman kontribusi yang memberikan deskripsi langkah demi langkah tentang cara berkontribusi pada kumpulan petunjuk.
Beberapa set data tidak ditangani secara otomatis oleh datasets dan mengharuskan pengguna untuk mengunduh dataset secara manual (misalnya story_cloze ).
Untuk menangani kumpulan data tersebut juga, kami mengharuskan pengguna untuk mengunduh dataset dan memasukkannya ke dalam ~/.cache/promptsource . Ini adalah direktori root yang berisi semua dataset yang diunduh secara manual.
Anda dapat mengganti jalur default ini menggunakan variabel lingkungan PROMPTSOURCE_MANUAL_DATASET_DIR . Ini harus menunjuk ke direktori root.
PromptSource dan P3 awalnya dikembangkan sebagai bagian dari Proyek BigScience untuk penelitian terbuka?, Inisiatif selama setahun yang menargetkan studi model dan set data besar. Tujuan dari proyek ini adalah untuk meneliti model bahasa di lingkungan publik di luar perusahaan teknologi besar. Proyek ini memiliki 600 peneliti dari 50 negara dan lebih dari 250 lembaga.
Secara khusus, PromptSource dan P3 adalah langkah pertama untuk kertas multitask yang diminta memungkinkan generalisasi tugas zero-shot.
Anda akan menemukan repositori resmi untuk mereproduksi hasil kertas di sini: https://github.com/bigscience-workshop/t-zero. Kami juga merilis T0* (ucapkan "T Zero"), serangkaian model yang dilatih pada P3 dan disajikan di koran. Pos pemeriksaan tersedia di sini.
Peringatan atau kesalahan tentang Darwin di OS X: Cobalah penurunan peringkat Pyarrow ke 3.0.0.
ConnectionRefusedError: [errno 61] Koneksi ditolak: Terjadi sesekali. Coba mulai ulang aplikasi.
Jika Anda menemukan P3 atau PromptSource bermanfaat, silakan kutip referensi berikut:
@misc { bach2022promptsource ,
title = { PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts } ,
author = { Stephen H. Bach and Victor Sanh and Zheng-Xin Yong and Albert Webson and Colin Raffel and Nihal V. Nayak and Abheesht Sharma and Taewoon Kim and M Saiful Bari and Thibault Fevry and Zaid Alyafeai and Manan Dey and Andrea Santilli and Zhiqing Sun and Srulik Ben-David and Canwen Xu and Gunjan Chhablani and Han Wang and Jason Alan Fries and Maged S. Al-shaibani and Shanya Sharma and Urmish Thakker and Khalid Almubarak and Xiangru Tang and Xiangru Tang and Mike Tian-Jian Jiang and Alexander M. Rush } ,
year = { 2022 } ,
eprint = { 2202.01279 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

