promptsource
v0.2.3:
ReptSource - это инструментарий для создания, обмена и использования подсказок естественного языка.
Недавняя работа показала, что крупные языковые модели демонстрируют способность выполнять разумное обобщение с нулевым выстрелом для новых задач. Например, GPT-3 продемонстрировал, что крупные языковые модели обладают сильными способностями нулевого и нескольких выстрелов. Затем Flan и T0 продемонстрировали, что предварительно обученные языковые модели, настраиваемые в массовом многозадачном моде, еще более сильной производительности с нулевым выстрелом. Общим знаменателем в этих работах является использование подсказок, которые вызвали интерес среди исследователей и инженеров НЛП. Это подчеркивает необходимость новых инструментов для создания, обмена и использования подсказок естественного языка.
Подсказки - это функции, которые отображают пример из набора данных на ввод естественного языка и целевой вывод. ReptSource содержит растущую коллекцию подсказок (которые мы называем P3 : Public P ool P -rompts). По состоянию на 20 января 2022 года есть ~ 2000 английских подсказок для 170+ наборов данных английского языка в P3.
RedptSource предоставляет инструменты для создания и обмена подсказками естественного языка (см. Как создать подсказки, а затем используйте тысячи существующих и недавно созданных подсказок с помощью простого API (см. Как использовать подсказки). Подсказки сохраняются в автономных структурированных файлах и написаны на простом языке, называемом Jinja. Примером примера, доступные в Promptsource для SNLI.
{{premise}}
Question: Does this imply that "{{hypothesis}}"? Yes, no, or maybe? ||| {{answer_choices[labe l] }}Вы можете просмотреть существующие подсказки на хостинную версию reptSource.
Если вы не собираетесь создавать новые подсказки, вы можете просто запустить:
pip install promptsourceВ противном случае вам нужно установить репо локально:
pip install -e . Чтобы установить модуль promptsource Примечание. По причинам стабильности вам в настоящее время понадобится среда Python 3.7 для выполнения последнего шага. Однако, если вы только намереваетесь использовать подсказки, а не создавать новые подсказки через интерфейс, вы можете удалить это ограничение в setup.py и установить пакет локально.
Вы можете применить подсказки к примерам из наборов данных библиотеки наборов данных об объятиях.
# Load an example from the datasets ag_news
> >> from datasets import load_dataset
> >> dataset = load_dataset ( "ag_news" , split = "train" )
> >> example = dataset [ 1 ]
# Load prompts for this dataset
> >> from promptsource . templates import DatasetTemplates
> >> ag_news_prompts = DatasetTemplates ( 'ag_news' )
# Print all the prompts available for this dataset. The keys of the dict are the UUIDs the uniquely identify each of the prompt, and the values are instances of `Template` which wraps prompts
> >> print ( ag_news_prompts . templates )
{ '24e44a81-a18a-42dd-a71c-5b31b2d2cb39' : < promptsource . templates . Template object at 0x7fa7aeb20350 > , '8fdc1056-1029-41a1-9c67-354fc2b8ceaf' : < promptsource . templates . Template object at 0x7fa7aeb17c10 > , '918267e0-af68-4117-892d-2dbe66a58ce9' : < promptsource . templates . Template object at 0x7fa7ac7a2310 > , '9345df33-4f23-4944-a33c-eef94e626862' : < promptsource . templates . Template object at 0x7fa7ac7a2050 > , '98534347-fff7-4c39-a795-4e69a44791f7' : < promptsource . templates . Template object at 0x7fa7ac7a1310 > , 'b401b0ee-6ffe-4a91-8e15-77ee073cd858' : < promptsource . templates . Template object at 0x7fa7ac7a12d0 > , 'cb355f33-7e8c-4455-a72b-48d315bd4f60' : < promptsource . templates . Template object at 0x7fa7ac7a1110 > }
# Select a prompt by its name
>> > prompt = ag_news_prompts [ "classify_question_first" ]
# Apply the prompt to the example
>> > result = prompt . apply ( example )
>> > print ( "INPUT: " , result [ 0 ])
INPUT : What label best describes this news article ?
Carlyle Looks Toward Commercial Aerospace ( Reuters ) Reuters - Private investment firm Carlyle Group , which has a reputation for making well - timed and occasionally controversial plays in the defense industry , has quietly placed its bets on another part of the market .
> >> print ( "TARGET: " , result [ 1 ])
TARGET : BusinessВ случае, когда вы ищете подсказки, доступные для определенного подмножества набора данных, вы должны использовать следующий синтаксис:
dataset_name , subset_name = "super_glue" , "rte"
dataset = load_dataset ( f" { dataset_name } / { subset_name } " , split = "train" )
example = dataset [ 0 ]
prompts = DatasetTemplates ( f" { dataset_name } / { subset_name } " )Вы также можете собрать все доступные подсказки для связанных с ними наборов данных:
> >> from promptsource . templates import TemplateCollection
# Get all the prompts available in PromptSource
> >> collection = TemplateCollection ()
# Print a dict where the key is the pair (dataset name, subset name)
# and the value is an instance of DatasetTemplates
> >> print ( collection . datasets_templates )
{( 'poem_sentiment' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7939d0 > , ( 'common_gen' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac795410 > , ( 'anli' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac794590 > , ( 'cc_news' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac798a90 > , ( 'craigslist_bargains' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7a2c10 > ,...}Вы можете узнать больше об API reptSource для хранения, манипулирования и использования подсказок в документации.
ReptSource предоставляет веб-графический интерфейс, который позволяет разработчикам писать подсказки на языке шаблона и сразу же просматривать свои результаты на разных примерах.
В приложении есть 3 режима:
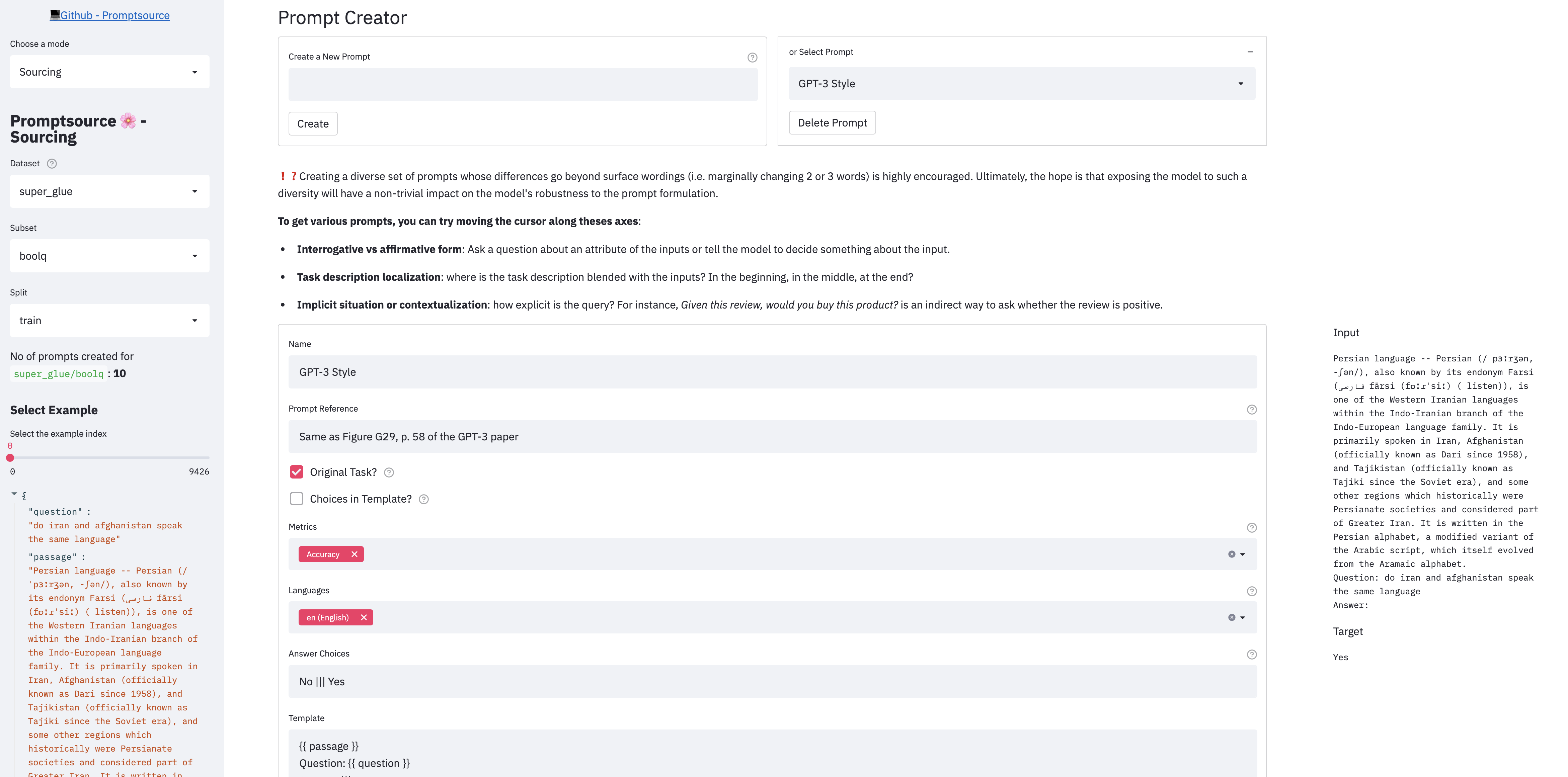
Чтобы запустить приложение локально, сначала убедитесь, что вы выполнили шаги в настройке, и из корневого каталога репо, запустите:
streamlit run promptsource/app.py Вы также можете просмотреть существующие подсказки на размещенной версии reptSource. Обратите внимание, что размещенная версия отключает режим Sourcing ( streamlit run promptsource/app.py -- --read-only ).
Прежде чем создавать новые подсказки, вы должны прочитать рекомендации по вкладу, которые дают пошаговое описание того, как внести свой вклад в сбор подсказки.
Некоторые наборы данных не обрабатываются автоматически с помощью datasets и требуют, чтобы пользователи загружали набор данных вручную (например, story_cloze ).
Чтобы обрабатывать эти наборы данных, мы требуем, чтобы пользователи загружали набор данных и размещали его в ~/.cache/promptsource . Это корневый каталог, содержащий все загруженные вручную наборы данных.
Вы можете переопределить этот путь по умолчанию, используя переменную среды PROMPTSOURCE_MANUAL_DATASET_DIR . Это должно указывать на корневой каталог.
AdptSource и P3 были первоначально разработаны в рамках проекта BigScience для открытых исследований?, Годовой инициативы, нацеленной на изучение крупных моделей и наборов данных. Цель проекта - исследовать языковые модели в общественной среде за пределами крупных технологических компаний. Проект имеет 600 исследователей из 50 стран и более 250 учреждений.
В частности, redptSource и P3 были первыми шагами для многозадачной работы бумаги, вызванных обучением, позволяющим обобщать задачи с нулевым выстрелом.
Вы найдете официальный репозиторий для воспроизведения результатов бумаги здесь: https://github.com/bigscience-workshop/t-zero. Мы также выпустили T0* (произносится «T Zero»), серию моделей, обученных P3 и представленные в статье. Контрольные точки доступны здесь.
Предупреждение или ошибка о Дарвине на OS X: попробуйте понизить Pyarrow до 3.0.0.
ConnectionRefusError: [Errno 61] Соединение отказано: случается иногда. Попробуйте перезапустить приложение.
Если вы найдете P3 или PromptSource полезным, пожалуйста, укажите следующую ссылку:
@misc { bach2022promptsource ,
title = { PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts } ,
author = { Stephen H. Bach and Victor Sanh and Zheng-Xin Yong and Albert Webson and Colin Raffel and Nihal V. Nayak and Abheesht Sharma and Taewoon Kim and M Saiful Bari and Thibault Fevry and Zaid Alyafeai and Manan Dey and Andrea Santilli and Zhiqing Sun and Srulik Ben-David and Canwen Xu and Gunjan Chhablani and Han Wang and Jason Alan Fries and Maged S. Al-shaibani and Shanya Sharma and Urmish Thakker and Khalid Almubarak and Xiangru Tang and Xiangru Tang and Mike Tian-Jian Jiang and Alexander M. Rush } ,
year = { 2022 } ,
eprint = { 2202.01279 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

