promptsource
v0.2.3:
ProserSource هي مجموعة أدوات لإنشاء ومشاركة واستخدام مطالبات اللغة الطبيعية.
أظهر العمل الأخير أن نماذج اللغة الكبيرة تظهر القدرة على تنفيذ تعميم معقول صفري على مهام جديدة. على سبيل المثال ، أظهرت GPT-3 أن نماذج اللغة الكبيرة لها قدرات قوية على الصفر والقطعة القليلة. ثم أظهر Flan و T0 أن نماذج اللغة المدربة مسبقًا تم ضبطها بأداء أزياء متعدد المهام على نطاق واسع. يتمثل القاسم المشترك في هذه الأعمال في استخدام المطالبات التي اكتسبت اهتمامًا بين الباحثين والمهندسين في NLP. هذا يؤكد على الحاجة إلى أدوات جديدة لإنشاء ومشاركة واستخدام مطالبات اللغة الطبيعية.
المطالبات هي وظائف تعرض مثالاً من مجموعة بيانات إلى إدخال اللغة الطبيعية والإخراج المستهدف. يحتوي ProserSource على مجموعة متزايدة من المطالبات (التي نسميها p3 : p ublic p ool of p rompts). اعتبارًا من 20 يناير 2022 ، هناك ~ 2'000 مطالبات إنجليزية لـ 170+ مجموعات بيانات إنجليزية في P3.
يوفر ProserSource الأدوات اللازمة لإنشاء ومشاركة مطالبات اللغة الطبيعية (انظر كيفية إنشاء مطالبات ، ثم استخدام الآلاف من المطالبات الحالية والإنشاء حديثًا من خلال واجهة برمجة تطبيقات بسيطة (انظر كيفية استخدام المطالبات).
{{premise}}
Question: Does this imply that "{{hypothesis}}"? Yes, no, or maybe? ||| {{answer_choices[labe l] }}يمكنك تصفح المطالبات الموجودة على الإصدار المستضاف من ProserSource.
إذا كنت لا تنوي إنشاء مطالبات جديدة ، يمكنك ببساطة التشغيل:
pip install promptsourceخلاف ذلك ، تحتاج إلى تثبيت الريبو محليا:
pip install -e . لتثبيت وحدة promptsource ملاحظة: لأسباب استقرار ، ستحتاج حاليًا إلى بيئة Python 3.7 لتشغيل الخطوة الأخيرة. ومع ذلك ، إذا كنت تنوي فقط استخدام المطالبات ، وعدم إنشاء مطالبات جديدة من خلال الواجهة ، يمكنك إزالة هذا القيد في setup.py وتثبيت الحزمة محليًا.
يمكنك تطبيق مطالبات على أمثلة من مجموعات البيانات من مكتبة مجموعات البيانات المعانقة.
# Load an example from the datasets ag_news
> >> from datasets import load_dataset
> >> dataset = load_dataset ( "ag_news" , split = "train" )
> >> example = dataset [ 1 ]
# Load prompts for this dataset
> >> from promptsource . templates import DatasetTemplates
> >> ag_news_prompts = DatasetTemplates ( 'ag_news' )
# Print all the prompts available for this dataset. The keys of the dict are the UUIDs the uniquely identify each of the prompt, and the values are instances of `Template` which wraps prompts
> >> print ( ag_news_prompts . templates )
{ '24e44a81-a18a-42dd-a71c-5b31b2d2cb39' : < promptsource . templates . Template object at 0x7fa7aeb20350 > , '8fdc1056-1029-41a1-9c67-354fc2b8ceaf' : < promptsource . templates . Template object at 0x7fa7aeb17c10 > , '918267e0-af68-4117-892d-2dbe66a58ce9' : < promptsource . templates . Template object at 0x7fa7ac7a2310 > , '9345df33-4f23-4944-a33c-eef94e626862' : < promptsource . templates . Template object at 0x7fa7ac7a2050 > , '98534347-fff7-4c39-a795-4e69a44791f7' : < promptsource . templates . Template object at 0x7fa7ac7a1310 > , 'b401b0ee-6ffe-4a91-8e15-77ee073cd858' : < promptsource . templates . Template object at 0x7fa7ac7a12d0 > , 'cb355f33-7e8c-4455-a72b-48d315bd4f60' : < promptsource . templates . Template object at 0x7fa7ac7a1110 > }
# Select a prompt by its name
>> > prompt = ag_news_prompts [ "classify_question_first" ]
# Apply the prompt to the example
>> > result = prompt . apply ( example )
>> > print ( "INPUT: " , result [ 0 ])
INPUT : What label best describes this news article ?
Carlyle Looks Toward Commercial Aerospace ( Reuters ) Reuters - Private investment firm Carlyle Group , which has a reputation for making well - timed and occasionally controversial plays in the defense industry , has quietly placed its bets on another part of the market .
> >> print ( "TARGET: " , result [ 1 ])
TARGET : Businessفي حالة البحث عن المطالبات المتاحة لمجموعة فرعية معينة من مجموعة البيانات ، يجب عليك استخدام بناء الجملة التالي:
dataset_name , subset_name = "super_glue" , "rte"
dataset = load_dataset ( f" { dataset_name } / { subset_name } " , split = "train" )
example = dataset [ 0 ]
prompts = DatasetTemplates ( f" { dataset_name } / { subset_name } " )يمكنك أيضًا جمع جميع المطالبات المتاحة لمجموعات البيانات المرتبطة بها:
> >> from promptsource . templates import TemplateCollection
# Get all the prompts available in PromptSource
> >> collection = TemplateCollection ()
# Print a dict where the key is the pair (dataset name, subset name)
# and the value is an instance of DatasetTemplates
> >> print ( collection . datasets_templates )
{( 'poem_sentiment' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7939d0 > , ( 'common_gen' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac795410 > , ( 'anli' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac794590 > , ( 'cc_news' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac798a90 > , ( 'craigslist_bargains' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7a2c10 > ,...}يمكنك معرفة المزيد حول واجهة برمجة تطبيقات ProserSource لتخزين ومعالجة واستخدام المطالبات في الوثائق.
يوفر ProserSource واجهة المستخدم الرسومية المستندة إلى الويب يمكّن المطورين من كتابة مطالبات بلغة مبدّرة وعرض مخرجاتهم على الفور على أمثلة مختلفة.
هناك 3 أوضاع في التطبيق:
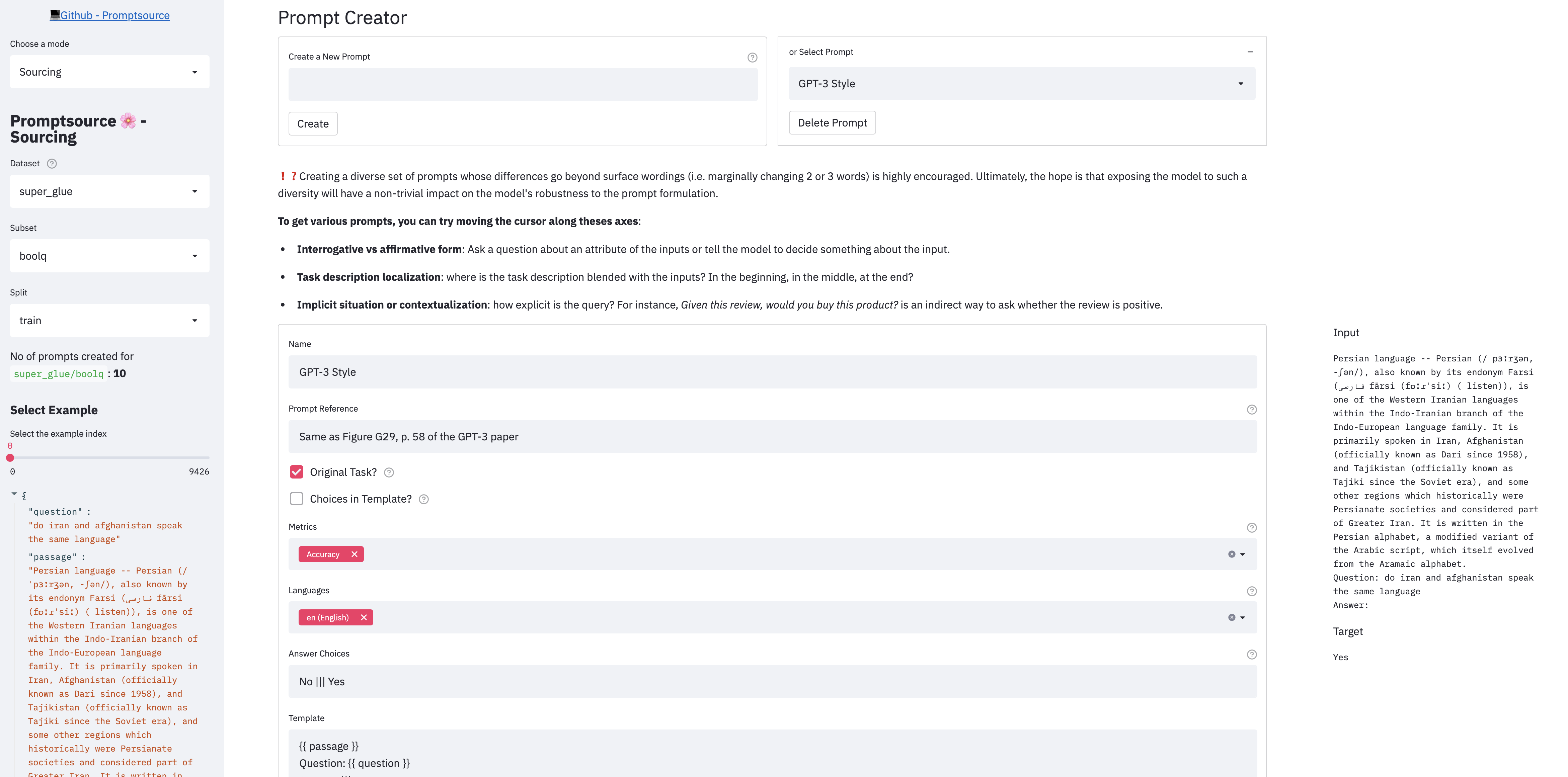
لإطلاق التطبيق محليًا ، يرجى أولاً التأكد من اتباع الخطوات في الإعداد ، ومن الدليل الجذري لإعادة الريبو ، تشغيل:
streamlit run promptsource/app.py يمكنك أيضًا تصفح المطالبات الموجودة على الإصدار المستضاف من ProserSource. لاحظ أن الإصدار المستضاف يعطل وضع المصادر ( streamlit run promptsource/app.py -- --read-only ).
قبل إنشاء مطالبات جديدة ، يجب عليك قراءة إرشادات المساهمة التي تعطي وصفًا خطوة بخطوة لكيفية المساهمة في مجموعة المطالبات.
لا تتم معالجة بعض مجموعات البيانات تلقائيًا بواسطة datasets وتتطلب من المستخدمين تنزيل مجموعة البيانات يدويًا ( story_cloze على سبيل المثال).
للتعامل مع مجموعات البيانات هذه أيضًا ، نطلب من المستخدمين تنزيل مجموعة البيانات ووضعها في ~/.cache/promptsource . هذا هو الدليل الجذر الذي يحتوي على جميع مجموعات البيانات التي تم تنزيلها يدويًا.
يمكنك تجاوز هذا المسار الافتراضي باستخدام متغير بيئة PROMPTSOURCE_MANUAL_DATASET_DIR . هذا يجب أن يشير إلى دليل الجذر.
تم تطوير ProderSource و P3 في الأصل كجزء من مشروع BigScience للبحث المفتوح؟ ، مبادرة لمدة عام تستهدف دراسة النماذج الكبيرة ومجموعات البيانات. الهدف من المشروع هو البحث في نماذج اللغة في بيئة عامة خارج شركات التكنولوجيا الكبيرة. يضم المشروع 600 باحث من 50 دولة وأكثر من 250 مؤسسة.
على وجه الخصوص ، كانت Productsource و P3 هي الخطوات الأولى للورقة التي دفعت المهام المتعددة التي دفعت التدريب إلى تمكين تعميم مهمة صفرية.
ستجد المستودع الرسمي لإعادة إنتاج نتائج الورقة هنا: https://github.com/bigscience-workshop/t-zero. أصدرنا أيضًا T0* (نطق "T Zero") ، سلسلة من النماذج المدربين على P3 وعرضت في الورقة. نقاط التفتيش متوفرة هنا.
تحذير أو خطأ حول داروين على OS X: حاول تقليل تصنيف Pyarrow إلى 3.0.0.
ConnectionRefusederror: [Errno 61] تم رفض الاتصال: يحدث من حين لآخر. حاول إعادة تشغيل التطبيق.
إذا وجدت P3 أو ProserSource مفيدة ، فيرجى الاستشهاد بالمرجع التالي:
@misc { bach2022promptsource ,
title = { PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts } ,
author = { Stephen H. Bach and Victor Sanh and Zheng-Xin Yong and Albert Webson and Colin Raffel and Nihal V. Nayak and Abheesht Sharma and Taewoon Kim and M Saiful Bari and Thibault Fevry and Zaid Alyafeai and Manan Dey and Andrea Santilli and Zhiqing Sun and Srulik Ben-David and Canwen Xu and Gunjan Chhablani and Han Wang and Jason Alan Fries and Maged S. Al-shaibani and Shanya Sharma and Urmish Thakker and Khalid Almubarak and Xiangru Tang and Xiangru Tang and Mike Tian-Jian Jiang and Alexander M. Rush } ,
year = { 2022 } ,
eprint = { 2202.01279 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

