promptsource
v0.2.3:
O PromptSource é um kit de ferramentas para criar, compartilhar e usar os avisos de linguagem natural.
Trabalhos recentes mostraram que grandes modelos de idiomas exibem a capacidade de executar uma generalização razoável de tiro zero para novas tarefas. Por exemplo, o GPT-3 demonstrou que os grandes modelos de linguagem possuem fortes habilidades zero e poucas fotos. Flan e T0 demonstraram que os modelos de idiomas pré-treinados são ajustados de maneira massivamente multitarefa, produzem um desempenho zero ainda mais forte. Um denominador comum nesses trabalhos é o uso de avisos que ganharam interesse entre pesquisadores e engenheiros da PNL. Isso enfatiza a necessidade de novas ferramentas para criar, compartilhar e usar os avisos de linguagem natural.
Os avisos são funções que mapeiam um exemplo de um conjunto de dados para uma entrada de linguagem natural e saída de destino. O PromptSource contém uma crescente coleção de avisos (que chamamos de p3 : p ublic p Ool of P Rompts). Em 20 de janeiro de 2022, existem ~ 2.000 solicitações em inglês para mais de 170 conjuntos de dados em inglês em P3.
O PromptSource fornece as ferramentas para criar e compartilhar instruções de linguagem natural (consulte como criar prompts e, em seguida, usar os milhares de instruções existentes e criadas recentemente por meio de uma API simples (consulte como usar os avisos). Os avisos são salvos em arquivos estruturados independentes e são escritos em um modelo simples chamado Jinja. Um exemplo de prompts em Promotes
{{premise}}
Question: Does this imply that "{{hypothesis}}"? Yes, no, or maybe? ||| {{answer_choices[labe l] }}Você pode navegar pelas instruções existentes na versão hospedada do PromptSource.
Se você não pretende criar novos avisos, poderá simplesmente executar:
pip install promptsourceCaso contrário, você precisa instalar o repositório localmente:
pip install -e . Para instalar o módulo promptsource Nota: Por motivos de estabilidade, você precisará atualmente de um ambiente Python 3.7 para executar a última etapa. No entanto, se você pretende usar apenas os prompts e não criar novos avisos através da interface, poderá remover essa restrição no setup.py e instalar o pacote localmente.
Você pode aplicar instruções a exemplos dos conjuntos de dados da biblioteca de conjuntos de dados de face abraçados.
# Load an example from the datasets ag_news
> >> from datasets import load_dataset
> >> dataset = load_dataset ( "ag_news" , split = "train" )
> >> example = dataset [ 1 ]
# Load prompts for this dataset
> >> from promptsource . templates import DatasetTemplates
> >> ag_news_prompts = DatasetTemplates ( 'ag_news' )
# Print all the prompts available for this dataset. The keys of the dict are the UUIDs the uniquely identify each of the prompt, and the values are instances of `Template` which wraps prompts
> >> print ( ag_news_prompts . templates )
{ '24e44a81-a18a-42dd-a71c-5b31b2d2cb39' : < promptsource . templates . Template object at 0x7fa7aeb20350 > , '8fdc1056-1029-41a1-9c67-354fc2b8ceaf' : < promptsource . templates . Template object at 0x7fa7aeb17c10 > , '918267e0-af68-4117-892d-2dbe66a58ce9' : < promptsource . templates . Template object at 0x7fa7ac7a2310 > , '9345df33-4f23-4944-a33c-eef94e626862' : < promptsource . templates . Template object at 0x7fa7ac7a2050 > , '98534347-fff7-4c39-a795-4e69a44791f7' : < promptsource . templates . Template object at 0x7fa7ac7a1310 > , 'b401b0ee-6ffe-4a91-8e15-77ee073cd858' : < promptsource . templates . Template object at 0x7fa7ac7a12d0 > , 'cb355f33-7e8c-4455-a72b-48d315bd4f60' : < promptsource . templates . Template object at 0x7fa7ac7a1110 > }
# Select a prompt by its name
>> > prompt = ag_news_prompts [ "classify_question_first" ]
# Apply the prompt to the example
>> > result = prompt . apply ( example )
>> > print ( "INPUT: " , result [ 0 ])
INPUT : What label best describes this news article ?
Carlyle Looks Toward Commercial Aerospace ( Reuters ) Reuters - Private investment firm Carlyle Group , which has a reputation for making well - timed and occasionally controversial plays in the defense industry , has quietly placed its bets on another part of the market .
> >> print ( "TARGET: " , result [ 1 ])
TARGET : BusinessNo caso de você estar procurando os avisos disponíveis para um subconjunto específico de um conjunto de dados, você deve usar a seguinte sintaxe:
dataset_name , subset_name = "super_glue" , "rte"
dataset = load_dataset ( f" { dataset_name } / { subset_name } " , split = "train" )
example = dataset [ 0 ]
prompts = DatasetTemplates ( f" { dataset_name } / { subset_name } " )Você também pode coletar todos os avisos disponíveis para seus conjuntos de dados associados:
> >> from promptsource . templates import TemplateCollection
# Get all the prompts available in PromptSource
> >> collection = TemplateCollection ()
# Print a dict where the key is the pair (dataset name, subset name)
# and the value is an instance of DatasetTemplates
> >> print ( collection . datasets_templates )
{( 'poem_sentiment' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7939d0 > , ( 'common_gen' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac795410 > , ( 'anli' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac794590 > , ( 'cc_news' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac798a90 > , ( 'craigslist_bargains' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7a2c10 > ,...}Você pode aprender mais sobre a API da PromptSource para armazenar, manipular e usar prompts na documentação.
O PromptSource fornece uma GUI baseada na Web que permite que os desenvolvedores escrevam instruções em um idioma de modelos e visualizem imediatamente seus resultados em diferentes exemplos.
Existem 3 modos no aplicativo:
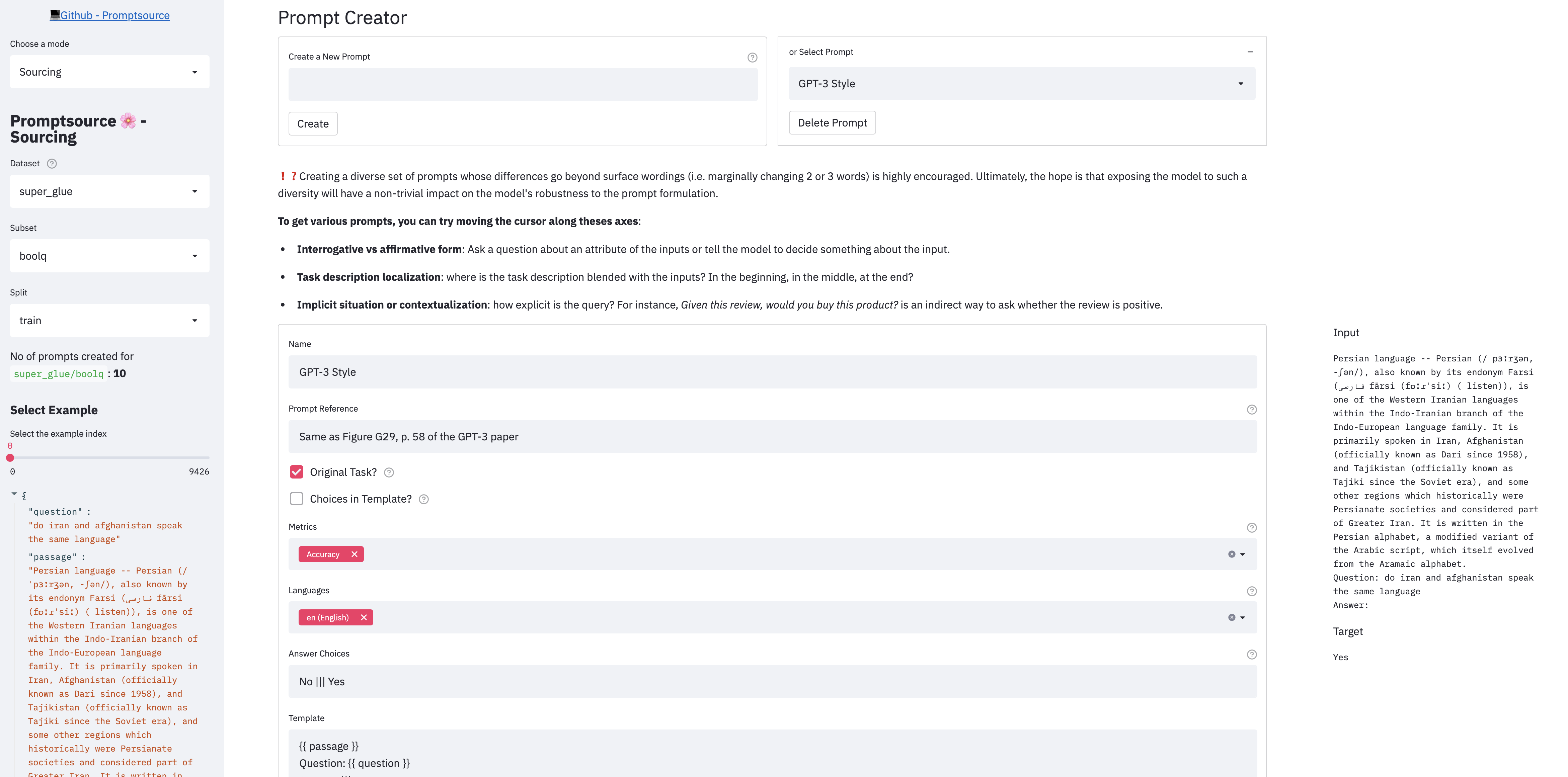
Para iniciar o aplicativo localmente, primeiro verifique se você seguiu as etapas da instalação e, a partir do diretório raiz do repositório, execute:
streamlit run promptsource/app.py Você também pode navegar pelos avisos existentes na versão hospedada do PromptSource. NOTA A versão hospedada desativa o modo de fornecimento ( streamlit run promptsource/app.py -- --read-only ).
Antes de criar novos avisos, você deve ler as diretrizes de contribuição que fornecem uma descrição passo a passo de como contribuir para a coleta de prompts.
Alguns conjuntos de dados não são tratados automaticamente pelos datasets e exigem que os usuários baixem o conjunto de dados manualmente ( story_cloze , por exemplo).
Para lidar com esses conjuntos de dados também, exigimos que os usuários baixem o conjunto de dados e o coloquem em ~/.cache/promptsource . Este é o diretório raiz que contém todos os conjuntos de dados baixados manualmente.
Você pode substituir esse caminho padrão usando PROMPTSOURCE_MANUAL_DATASET_DIR Ambiente. Isso deve apontar para o diretório raiz.
Promptsource e P3 foram originalmente desenvolvidos como parte do projeto Bigscience para pesquisa aberta?, Uma iniciativa de um ano direcionada ao estudo de grandes modelos e conjuntos de dados. O objetivo do projeto é pesquisar modelos de idiomas em um ambiente público fora de grandes empresas de tecnologia. O projeto possui 600 pesquisadores de 50 países e mais de 250 instituições.
Em particular, o Prompsource e o P3 foram os primeiros passos para o treinamento de treinamento solicitado por várias tarefas, permite a generalização de tarefas zero.
Você encontrará o repositório oficial para reproduzir os resultados do artigo aqui: https://github.com/bigscience-workshop/t-zero. Também lançamos o T0* (pronuncia "t zero"), uma série de modelos treinados em p3 e apresentados no artigo. Os pontos de verificação estão disponíveis aqui.
Aviso ou erro sobre Darwin no OS X: tente rebaixar Pyarrow para 3.0.0.
ConnectionRefusedError: [ERRNO 61] Conexão recusada: acontece ocasionalmente. Tente reiniciar o aplicativo.
Se você achar útil p3 ou prontsource, cite a seguinte referência:
@misc { bach2022promptsource ,
title = { PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts } ,
author = { Stephen H. Bach and Victor Sanh and Zheng-Xin Yong and Albert Webson and Colin Raffel and Nihal V. Nayak and Abheesht Sharma and Taewoon Kim and M Saiful Bari and Thibault Fevry and Zaid Alyafeai and Manan Dey and Andrea Santilli and Zhiqing Sun and Srulik Ben-David and Canwen Xu and Gunjan Chhablani and Han Wang and Jason Alan Fries and Maged S. Al-shaibani and Shanya Sharma and Urmish Thakker and Khalid Almubarak and Xiangru Tang and Xiangru Tang and Mike Tian-Jian Jiang and Alexander M. Rush } ,
year = { 2022 } ,
eprint = { 2202.01279 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

