promptsource
v0.2.3:
PromptSourceは、自然言語のプロンプトを作成、共有、使用するためのツールキットです。
最近の研究は、大規模な言語モデルが新しいタスクに合理的なゼロショット一般化を実行する能力を示すことを示しています。たとえば、GPT-3は、大規模な言語モデルが強いゼロおよび少数のショット能力を持っていることを実証しました。その後、FlanとT0は、大規模なマルチタスクファッションで微調整された事前に訓練された言語モデルがさらに強力なゼロショットパフォーマンスをもたらすことを実証しました。これらの作品の一般的な分母は、NLPの研究者とエンジニアの間で関心を集めているプロンプトの使用です。これは、自然言語のプロンプトを作成、共有、使用する新しいツールの必要性を強調しています。
プロンプトは、データセットからの例を自然言語入力およびターゲット出力にマッピングする関数です。 PromptSourceには、増え続けるプロンプトのコレクションが含まれています( P3 : P romptsのp ublic p oolと呼ばれます)。 2022年1月20日の時点で、P3には170以上の英語データセットには約2'000の英語プロンプトがあります。
PromptSourceは、自然言語のプロンプトを作成して共有するツールを提供します(プロンプトの作成方法を参照してから、シンプルなAPIを介して数千の既存および新しく作成されたプロンプトを使用します(プロンプトの使用方法を参照)。プロンプトはスタンドアロン構造ファイルに保存され、Jinjaと呼ばれる単純なテンプレート言語で記述されます。
{{premise}}
Question: Does this imply that "{{hypothesis}}"? Yes, no, or maybe? ||| {{answer_choices[labe l] }}プロンプトソースのホストバージョンの既存のプロンプトを閲覧できます。
新しいプロンプトを作成するつもりがない場合は、単純に実行できます。
pip install promptsourceそれ以外の場合は、リポジトリをローカルにインストールする必要があります。
pip install -e . promptsourceモジュールをインストールします注:安定性の理由から、現在、最後のステップを実行するにはPython 3.7環境が必要になります。ただし、インターフェイスを介して新しいプロンプトを作成しない場合のみを使用する場合のみ、 setup.pyでこの制約を削除して、パッケージをローカルにインストールできます。
抱きしめるFace Datasetsライブラリのデータセットの例にプロンプトを適用できます。
# Load an example from the datasets ag_news
> >> from datasets import load_dataset
> >> dataset = load_dataset ( "ag_news" , split = "train" )
> >> example = dataset [ 1 ]
# Load prompts for this dataset
> >> from promptsource . templates import DatasetTemplates
> >> ag_news_prompts = DatasetTemplates ( 'ag_news' )
# Print all the prompts available for this dataset. The keys of the dict are the UUIDs the uniquely identify each of the prompt, and the values are instances of `Template` which wraps prompts
> >> print ( ag_news_prompts . templates )
{ '24e44a81-a18a-42dd-a71c-5b31b2d2cb39' : < promptsource . templates . Template object at 0x7fa7aeb20350 > , '8fdc1056-1029-41a1-9c67-354fc2b8ceaf' : < promptsource . templates . Template object at 0x7fa7aeb17c10 > , '918267e0-af68-4117-892d-2dbe66a58ce9' : < promptsource . templates . Template object at 0x7fa7ac7a2310 > , '9345df33-4f23-4944-a33c-eef94e626862' : < promptsource . templates . Template object at 0x7fa7ac7a2050 > , '98534347-fff7-4c39-a795-4e69a44791f7' : < promptsource . templates . Template object at 0x7fa7ac7a1310 > , 'b401b0ee-6ffe-4a91-8e15-77ee073cd858' : < promptsource . templates . Template object at 0x7fa7ac7a12d0 > , 'cb355f33-7e8c-4455-a72b-48d315bd4f60' : < promptsource . templates . Template object at 0x7fa7ac7a1110 > }
# Select a prompt by its name
>> > prompt = ag_news_prompts [ "classify_question_first" ]
# Apply the prompt to the example
>> > result = prompt . apply ( example )
>> > print ( "INPUT: " , result [ 0 ])
INPUT : What label best describes this news article ?
Carlyle Looks Toward Commercial Aerospace ( Reuters ) Reuters - Private investment firm Carlyle Group , which has a reputation for making well - timed and occasionally controversial plays in the defense industry , has quietly placed its bets on another part of the market .
> >> print ( "TARGET: " , result [ 1 ])
TARGET : Businessデータセットの特定のサブセットで利用可能なプロンプトを探している場合、次の構文を使用する必要があります。
dataset_name , subset_name = "super_glue" , "rte"
dataset = load_dataset ( f" { dataset_name } / { subset_name } " , split = "train" )
example = dataset [ 0 ]
prompts = DatasetTemplates ( f" { dataset_name } / { subset_name } " )また、関連するデータセットに利用可能なすべてのプロンプトを収集することもできます。
> >> from promptsource . templates import TemplateCollection
# Get all the prompts available in PromptSource
> >> collection = TemplateCollection ()
# Print a dict where the key is the pair (dataset name, subset name)
# and the value is an instance of DatasetTemplates
> >> print ( collection . datasets_templates )
{( 'poem_sentiment' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7939d0 > , ( 'common_gen' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac795410 > , ( 'anli' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac794590 > , ( 'cc_news' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac798a90 > , ( 'craigslist_bargains' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7a2c10 > ,...}PromptSourceのAPIの詳細については、ドキュメントでプロンプトを保存、操作、および使用できます。
PromptSourceは、開発者がテンプレート言語でプロンプトを作成し、すぐにさまざまな例で出力を表示できるWebベースのGUIを提供します。
アプリには3つのモードがあります。
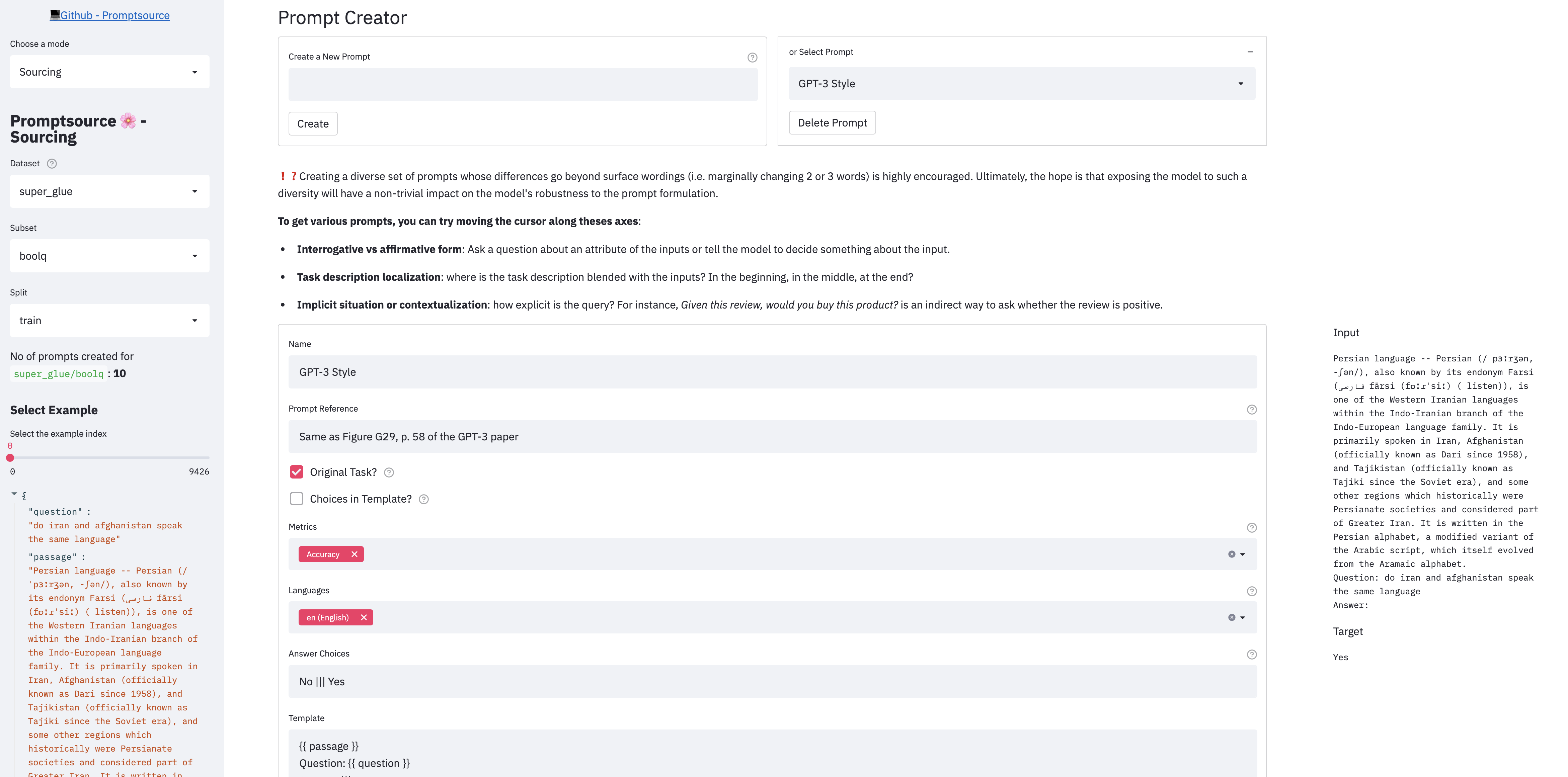
アプリをローカルに起動するには、まずセットアップの手順に従って、およびリポジトリのルートディレクトリから、実行してください。
streamlit run promptsource/app.pyまた、プロンプトソースのホストバージョンで既存のプロンプトを閲覧することもできます。注ホストバージョンは、Sourcingモードを無効にします( streamlit run promptsource/app.py -- --read-only )。
新しいプロンプトを作成する前に、プロンプトのコレクションに貢献する方法の段階的な説明を提供する貢献ガイドラインを読む必要があります。
一部のデータセットはdatasetsによって自動的に処理されず、ユーザーがデータセットを手動でダウンロードする必要があります(たとえばstory_cloze )。
これらのデータセットも処理するには、ユーザーにデータセットをダウンロードして~/.cache/promptsourceに配置する必要があります。これは、手動でダウンロードされたすべてのデータセットを含むルートディレクトリです。
PROMPTSOURCE_MANUAL_DATASET_DIR環境変数を使用して、このデフォルトパスをオーバーライドできます。これは、ルートディレクトリを指す必要があります。
プロンプトソースとP3は、元々、オープンリサーチのためのBigScienceプロジェクトの一部として開発されました。これは、大規模なモデルとデータセットの研究を対象とした1年間のイニシアチブです。このプロジェクトの目標は、大規模なテクノロジー企業以外の公共環境で言語モデルを調査することです。このプロジェクトには、50か国から600人の研究者と250を超える機関がいます。
特に、PromptSourceとP3が紙のマルチタスクの最初のステップであり、トレーニングがゼロショットタスクの一般化を可能にします。
公式リポジトリは、https://github.com/bigscience-workshop/t-zeroで、論文の結果を再現するための公式リポジトリを見つけるでしょう。また、P3で訓練され、論文で提示された一連のモデルであるT0*(「T Zero」と発音)をリリースしました。チェックポイントはこちらから入手できます。
OS Xのダーウィンに関する警告またはエラー: Pyarrowを3.0.0に格下げしてみてください。
ConnectionRefusedError:[errno 61]接続が拒否されました:時折発生します。アプリを再起動してみてください。
P3またはPromptSourceが便利だと思う場合は、次のリファレンスを引用してください。
@misc { bach2022promptsource ,
title = { PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts } ,
author = { Stephen H. Bach and Victor Sanh and Zheng-Xin Yong and Albert Webson and Colin Raffel and Nihal V. Nayak and Abheesht Sharma and Taewoon Kim and M Saiful Bari and Thibault Fevry and Zaid Alyafeai and Manan Dey and Andrea Santilli and Zhiqing Sun and Srulik Ben-David and Canwen Xu and Gunjan Chhablani and Han Wang and Jason Alan Fries and Maged S. Al-shaibani and Shanya Sharma and Urmish Thakker and Khalid Almubarak and Xiangru Tang and Xiangru Tang and Mike Tian-Jian Jiang and Alexander M. Rush } ,
year = { 2022 } ,
eprint = { 2202.01279 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

