promptsource
v0.2.3:
PrompTsource는 자연어 프롬프트를 만들고 공유 및 사용하기위한 툴킷입니다.
최근의 연구에 따르면 대형 언어 모델은 새로운 작업에 합리적인 제로 샷 일반화를 수행 할 수있는 능력을 보여줍니다. 예를 들어, GPT-3은 큰 언어 모델이 강한 제로 및 소수의 능력을 가지고 있음을 보여주었습니다. FLAN과 T0은 미리 훈련 된 언어 모델이 대규모 멀티 태스킹 패션으로 미세 조정 된 것으로 입증되었습니다. 이 작품의 일반적인 분모는 NLP 연구원과 엔지니어들 사이에 관심을 끌었던 프롬프트를 사용하는 것입니다. 이것은 자연어 프롬프트를 만들고 공유 및 사용할 수있는 새로운 도구가 필요하다는 것을 강조합니다.
프롬프트는 데이터 세트에서 자연어 입력 및 대상 출력에 대한 예제를 매핑하는 기능입니다. PromptSource에는 점점 더 많은 프롬프트 모음이 포함되어 있습니다 ( P3 : P ublic p ool의 p rompt). 2022 년 1 월 20 일 현재 P3에는 170 개 이상의 영어 데이터 세트에 대한 ~ 2'000 영어 프롬프트가 있습니다.
프롬프트 소스는 자연어 프롬프트를 만들고 공유하는 도구를 제공합니다 (프롬프트를 만드는 방법을 참조 한 다음 간단한 API를 통해 기존 및 새로 만든 프롬프트를 사용하는 방법을 참조하십시오 (프롬프트 사용 방법 참조). 프롬프트는 독립형 구조화 된 파일로 저장되며 Jinja라는 간단한 템플릿 언어로 작성되었습니다.
{{premise}}
Question: Does this imply that "{{hypothesis}}"? Yes, no, or maybe? ||| {{answer_choices[labe l] }}호스팅 된 PromptSource 버전에서 기존 프롬프트를 찾아 볼 수 있습니다.
새로운 프롬프트를 만들려고하지 않으면 간단히 실행할 수 있습니다.
pip install promptsource그렇지 않으면 로컬로 리포지를 설치해야합니다.
pip install -e . promptsource 모듈을 설치합니다 참고 : 안정성의 이유로 현재 마지막 단계를 실행하려면 Python 3.7 환경이 필요합니다. 그러나 프롬프트 만 사용하고 인터페이스를 통해 새로운 프롬프트를 만들지 않는 경우 setup.py 에서이 제약 조건을 제거하고 로컬로 패키지를 설치할 수 있습니다.
Hugging Face DataSets 라이브러리의 데이터 세트의 예제에 프롬프트를 적용 할 수 있습니다.
# Load an example from the datasets ag_news
> >> from datasets import load_dataset
> >> dataset = load_dataset ( "ag_news" , split = "train" )
> >> example = dataset [ 1 ]
# Load prompts for this dataset
> >> from promptsource . templates import DatasetTemplates
> >> ag_news_prompts = DatasetTemplates ( 'ag_news' )
# Print all the prompts available for this dataset. The keys of the dict are the UUIDs the uniquely identify each of the prompt, and the values are instances of `Template` which wraps prompts
> >> print ( ag_news_prompts . templates )
{ '24e44a81-a18a-42dd-a71c-5b31b2d2cb39' : < promptsource . templates . Template object at 0x7fa7aeb20350 > , '8fdc1056-1029-41a1-9c67-354fc2b8ceaf' : < promptsource . templates . Template object at 0x7fa7aeb17c10 > , '918267e0-af68-4117-892d-2dbe66a58ce9' : < promptsource . templates . Template object at 0x7fa7ac7a2310 > , '9345df33-4f23-4944-a33c-eef94e626862' : < promptsource . templates . Template object at 0x7fa7ac7a2050 > , '98534347-fff7-4c39-a795-4e69a44791f7' : < promptsource . templates . Template object at 0x7fa7ac7a1310 > , 'b401b0ee-6ffe-4a91-8e15-77ee073cd858' : < promptsource . templates . Template object at 0x7fa7ac7a12d0 > , 'cb355f33-7e8c-4455-a72b-48d315bd4f60' : < promptsource . templates . Template object at 0x7fa7ac7a1110 > }
# Select a prompt by its name
>> > prompt = ag_news_prompts [ "classify_question_first" ]
# Apply the prompt to the example
>> > result = prompt . apply ( example )
>> > print ( "INPUT: " , result [ 0 ])
INPUT : What label best describes this news article ?
Carlyle Looks Toward Commercial Aerospace ( Reuters ) Reuters - Private investment firm Carlyle Group , which has a reputation for making well - timed and occasionally controversial plays in the defense industry , has quietly placed its bets on another part of the market .
> >> print ( "TARGET: " , result [ 1 ])
TARGET : Business데이터 세트의 특정 하위 집합에 사용할 수있는 프롬프트를 찾고있는 경우 다음 구문을 사용해야합니다.
dataset_name , subset_name = "super_glue" , "rte"
dataset = load_dataset ( f" { dataset_name } / { subset_name } " , split = "train" )
example = dataset [ 0 ]
prompts = DatasetTemplates ( f" { dataset_name } / { subset_name } " )관련 데이터 세트에 사용 가능한 모든 프롬프트를 수집 할 수도 있습니다.
> >> from promptsource . templates import TemplateCollection
# Get all the prompts available in PromptSource
> >> collection = TemplateCollection ()
# Print a dict where the key is the pair (dataset name, subset name)
# and the value is an instance of DatasetTemplates
> >> print ( collection . datasets_templates )
{( 'poem_sentiment' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7939d0 > , ( 'common_gen' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac795410 > , ( 'anli' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac794590 > , ( 'cc_news' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac798a90 > , ( 'craigslist_bargains' , None ): < promptsource . templates . DatasetTemplates object at 0x7fa7ac7a2c10 > ,...}문서에 PromptSource의 API에 대한 자세한 내용을 알 수 있습니다.
PromptSource는 개발자가 템플릿 언어로 프롬프트를 작성하고 다른 예제에서 즉시 출력을 볼 수있는 웹 기반 GUI를 제공합니다.
앱에는 3 가지 모드가 있습니다.
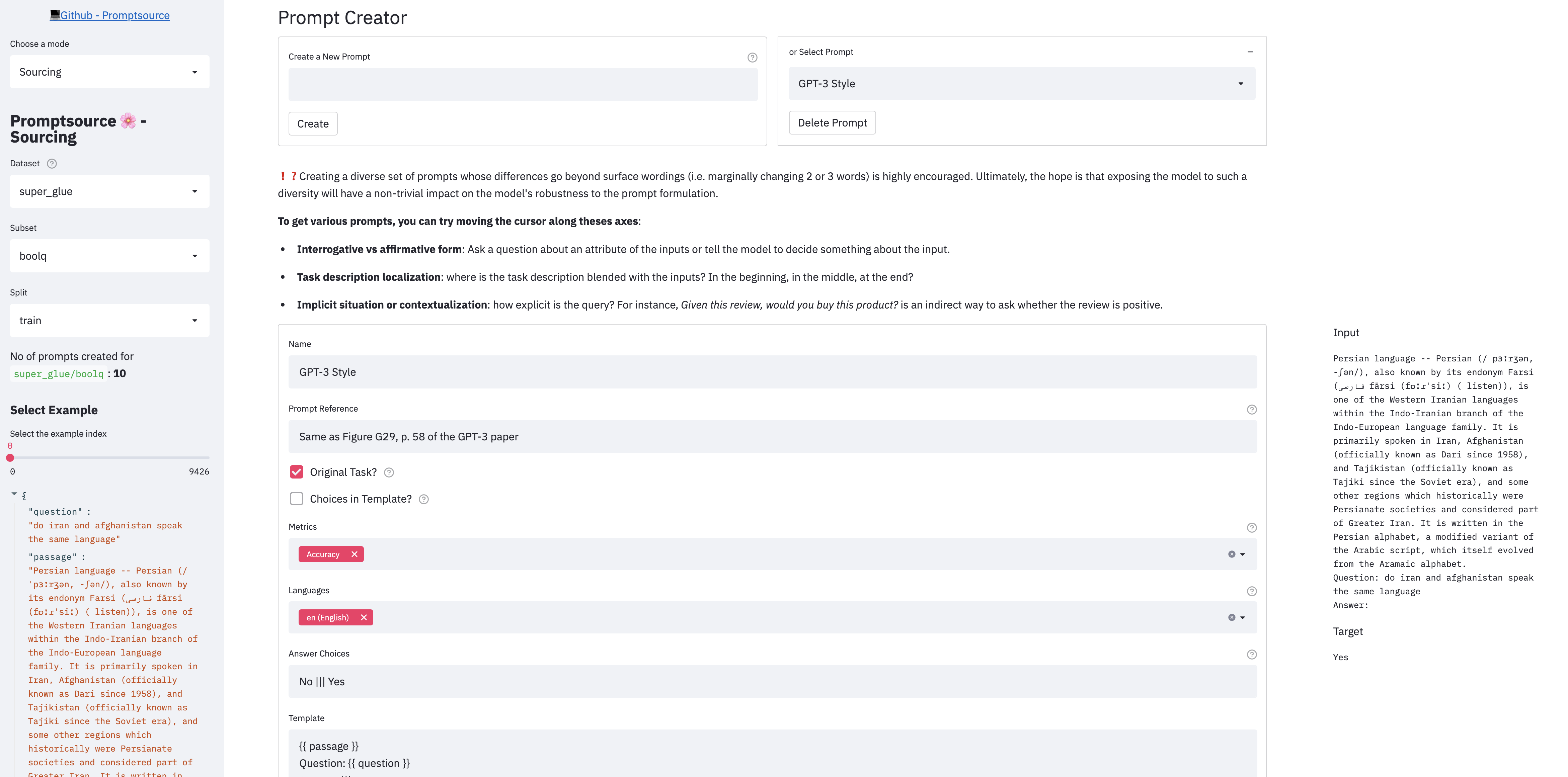
앱을 로컬로 시작하려면 먼저 설정 단계를 따르고 Repo의 루트 디렉토리에서 실행하십시오.
streamlit run promptsource/app.py 호스팅 된 PromptSource 버전에서 기존 프롬프트를 탐색 할 수도 있습니다. 호스팅 된 버전은 소싱 모드를 비활성화합니다 ( streamlit run promptsource/app.py -- --read-only ).
새로운 프롬프트를 만들기 전에 프롬프트 수집에 기여하는 방법에 대한 단계별 설명을 제공하는 기여 지침을 읽어야합니다.
일부 데이터 세트는 datasets 에 의해 자동으로 처리되지 않으며 사용자는 데이터 세트를 수동으로 다운로드해야합니다 (예 : story_cloze ).
해당 데이터 세트도 처리하려면 사용자가 데이터 세트를 다운로드하여 ~/.cache/promptsource 에 넣어야합니다. 이것은 수동으로 다운로드 된 모든 데이터 세트를 포함하는 루트 디렉토리입니다.
PROMPTSOURCE_MANUAL_DATASET_DIR 환경 변수를 사용 하여이 기본 경로를 무시할 수 있습니다. 이것은 루트 디렉토리를 가리켜 야합니다.
Promptsource와 P3는 원래 대규모 모델 및 데이터 세트의 연구를 목표로 한 1 년 동안의 이니셔티브 인 Open Research?의 Bigscience Project?의 일부로 개발되었습니다. 이 프로젝트의 목표는 대기업 이외의 공공 환경에서 언어 모델을 연구하는 것입니다. 이 프로젝트에는 50 개국의 600 명의 연구원과 250 개 이상의 기관이 있습니다.
특히, PromptSource와 P3은 종이 멀티 태스킹 프롬프트 훈련의 첫 번째 단계였으며 샷 작업 일반화를 가능하게합니다.
논문의 결과를 여기에서 재현하기위한 공식 저장소를 찾을 수 있습니다 : https://github.com/bigscience-workshop/t-zero. 또한 P3에 대해 교육을 받고 논문에 제시된 일련의 모델 인 T0* ( "T Zero")도 발표했습니다. 체크 포인트는 여기에서 제공됩니다.
OS X에서 Darwin에 대한 경고 또는 오류 : Pyarrow를 3.0.0으로 다운 그레이드하십시오.
ConnectionRefusedError : [Errno 61] 연결 거부 : 가끔 발생합니다. 앱을 다시 시작하십시오.
P3 또는 프롬프트 소스가 유용하다면 다음 참조를 인용하십시오.
@misc { bach2022promptsource ,
title = { PromptSource: An Integrated Development Environment and Repository for Natural Language Prompts } ,
author = { Stephen H. Bach and Victor Sanh and Zheng-Xin Yong and Albert Webson and Colin Raffel and Nihal V. Nayak and Abheesht Sharma and Taewoon Kim and M Saiful Bari and Thibault Fevry and Zaid Alyafeai and Manan Dey and Andrea Santilli and Zhiqing Sun and Srulik Ben-David and Canwen Xu and Gunjan Chhablani and Han Wang and Jason Alan Fries and Maged S. Al-shaibani and Shanya Sharma and Urmish Thakker and Khalid Almubarak and Xiangru Tang and Xiangru Tang and Mike Tian-Jian Jiang and Alexander M. Rush } ,
year = { 2022 } ,
eprint = { 2202.01279 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
}

