PyKoSpacing
1.0.0
แพ็คเกจ Python สำหรับระยะห่างของคำภาษาเกาหลีอัตโนมัติ
R Verson สามารถพบได้ที่นี่
ระยะห่างของคำเป็นหนึ่งในส่วนสำคัญของการประมวลผลล่วงหน้าของการวิเคราะห์ข้อความเกาหลี ระยะห่างที่แม่นยำส่งผลกระทบอย่างมากต่อความถูกต้องของการวิเคราะห์ข้อความที่ตามมา PyKoSpacing มีประสิทธิภาพการเว้นวรรคคำอัตโนมัติที่แม่นยำโดยเฉพาะอย่างยิ่งดีสำหรับข้อความออนไลน์ที่มาจาก SNS หรือ SMS
ตัวอย่างเช่น.
"아버지가방에들어가신다." สามารถเว้นระยะห่างด้านล่าง
สามัญสำนึกประการแรกคือคำตอบที่ถูกต้อง
PyKoSpacing ขึ้นอยู่กับรูปแบบการเรียนรู้เชิงลึกที่ได้รับการฝึกฝนจากคลังข้อมูลขนาดใหญ่ (บทความข่าวกว่า 100 ล้านบทความจาก Chan-Yub Park)
| ชุดทดสอบ | ความแม่นยำ |
|---|---|
| Sejong (รูปแบบภาษาพูด) คลังข้อมูล (1m) | 97.1% |
| oooo (รูปแบบวรรณกรรม) คลังข้อมูล (3M) | 94.3% |
สิ่งที่ต้องทำล่วงหน้า:
proper installation of python3
proper installation of pip
pip install tensorflow
pip install keras
Windows-Ubuntu case: On following error.
On error: /usr/lib/x86_64-linux-gnu/libstdc++.so.6: version ` GLIBCXX_3.4.22 ' not found
sudo apt-get install libstdc++6
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get upgrade
sudo apt-get dist-upgrade (This takes long time.)กรณีดาร์วิน (M1): คุณควรติดตั้ง tensorflow ในวิธีที่แตกต่างกัน (ใช้ miniforge3)
# Install Miniforge3 for mac
curl -O https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
chmod +x Miniforge3-MacOSX-arm64.sh
sh Miniforge3-MacOSX-arm64.sh
# Activate Miniforge3 virtualenv
# You should use Python version 3.10 or less.
source ~ /miniforge3/bin/activate
# Install the Tensorflow dependencies
conda install -c apple tensorflow-deps
# Install base tensorflow
python -m pip install tensorflow-macos
# Install metal plugin
python -m pip install tensorflow-metalหากต้องการติดตั้งจาก GitHub ให้ใช้
pip install git+https://github.com/haven-jeon/PyKoSpacing.git
> >> from pykospacing import Spacing
> >> spacing = Spacing ()
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> # Apply a list of words that must be non-spacing
>> > spacing ( '귀밑에서턱까지잇따라난수염을구레나룻이라고한다.' )
'귀 밑에서 턱까지 잇따라 난 수염을 구레나 룻이라고 한다.'
> >> spacing = Spacing ( rules = [ '구레나룻' ])
> >> spacing ( '귀밑에서턱까지잇따라난수염을구레나룻이라고한다.' )
'귀 밑에서 턱까지 잇따라 난 수염을 구레나룻이라고 한다.' การตั้งค่ากฎด้วยไฟล์ CSV (คุณจะต้องใช้เมธอด set_rules_by_csv() เท่านั้น)
$ cat test.csv
인덱스,단어
1,네이버영화
2,언급된단어 > >> from pykospacing import Spacing
> >> spacing = Spacing ( rules = [ '' ])
> >> spacing . set_rules_by_csv ( './test.csv' , '단어' )
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." )
"김형호 영화시장 분석가는 '1987'의 네이버영화 정보 네티즌 10점 평에서 언급된단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."รันบนบรรทัดคำสั่ง (ขอบคุณ lqez)
$ cat test_in.txt
김형호영화시장분석가는 ' 1987 ' 의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다.
아버지가방에들어가신다.
$ python -m pykospacing.pykos test_in.txt
김형호 영화시장 분석가는 ' 1987 ' 의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다.
아버지가 방에 들어가신다. รุ่นปัจจุบันมีปัญหาในบางกรณีเมื่ออินพุตมีอักขระภาษาอังกฤษ
Pykospacing ให้พารามิเตอร์ ignore และ ignore_pattern เพื่อจัดการกับปัญหานั้น
เกี่ยวกับ ignore พารามิเตอร์ (STR, ตัวเลือก)
ignore='none' : จะไม่มีการใช้ก่อน/หลังการประมวลผล เอาต์พุตจะเหมือนกับเอาต์พุตโมเดลignore='pre' : ใช้การประมวลผลล่วงหน้าซึ่งจะลบอักขระที่ตรงกับ ignore_pattern อักขระที่ถูกลบเหล่านี้จะถูกรวมเข้าด้วยกันหลังจากการทำนายแบบจำลอง ตัวเลือกนี้มีปัญหาที่จะทำให้มีพื้นที่ หลังจาก ตัวละครที่ถูกลบอยู่เสมอเนื่องจากไม่ทราบว่าตัวละครที่ถูกลบจะมีพื้นที่ไปทางซ้ายขวาหรือทั้งสองอย่างหรือไม่ignore='post' : ใช้การโพสต์การประมวลผลซึ่งละเว้นการส่งออกโมเดลบนอักขระที่ตรงกับ ignore_pattern ตัวเลือกนี้มีปัญหาที่อักขระภาษาอังกฤษในการป้อนข้อมูลแบบจำลองอาจส่งผลกระทบต่อตัวละครที่ไม่ใช่ภาษาอังกฤษignore='pre2' : ใช้การประมวลผลล่วงหน้าซึ่งลบอักขระที่ตรงกับกับ ignore_pattern และทำนาย ทั้งข้อความที่ประมวลผลล่วงหน้าและข้อความต้นฉบับ สิ่งนี้จะช่วยให้รู้ว่าจะวางพื้นที่ทางซ้ายขวาหรือตัวละครทั้งสองตัวที่ถูกลบ อย่างไรก็ตามตัวเลือกนี้ต้องทำนาย สองครั้ง ซึ่งเพิ่มเวลาในการคำนวณเป็นสองเท่าignore='none' เกี่ยวกับพารามิเตอร์ Abuse ignore_pattern (STR, ตัวเลือก)
คุณสามารถป้อนรูปแบบ regex ของคุณเองเพื่อ ignore_pattern รูปแบบ regex ควรเป็นรูปแบบของตัวละครที่คุณต้องการเพิกเฉย
ignore_pattern=r'[^가-힣ㄱ-ㅣ!-@[-`{-~s]+,*( [^가-힣ㄱ-ㅣ!-@[-`{-~s]+,*)*[.,!?]* *' ตัวอย่างของพารามิเตอร์ ignore
> >> from pykospacing import Spacing
> >> spacing = Spacing ()
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'none' )
"친구와 함께 bm w 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'pre' )
"친구와 함께bmw 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'post' )
"친구와 함께 bm w 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'pre2' )
"친구와 함께 bmw 썬바이저를 썼다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'none' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한튀김 옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'pre' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다.crispy 한 튀김옷 덕에 내 입 주변은glossy 해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'post' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한튀김 옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'pre2' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한 튀김옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'none' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'pre' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램R과KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'post' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'pre2' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다." 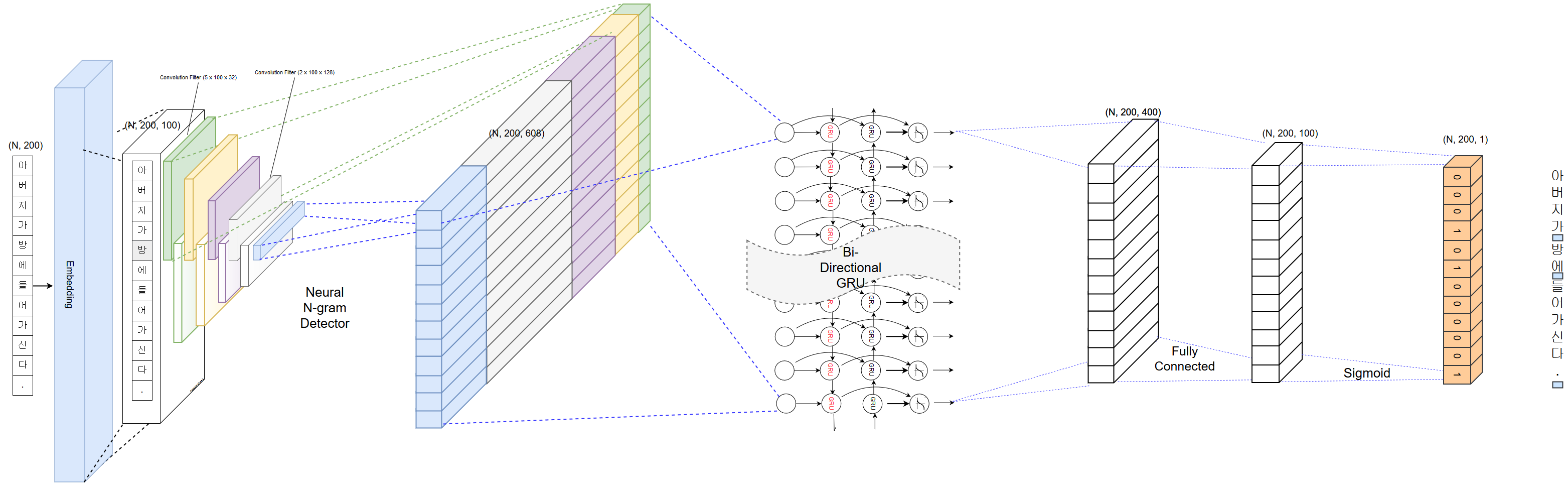
@misc{heewon2018,
author = {Heewon Jeon},
title = {KoSpacing: Automatic Korean word spacing},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/haven-jeon/KoSpacing}}


