PyKoSpacing
1.0.0
Пакет Python для автоматического корейского расстояния.
R Verson можно найти здесь.
Расстояние между слонами является одной из важных частей предварительной обработки корейского анализа текста. Точное расстояние значительно влияет на точность последующего анализа текста. PyKoSpacing имеет довольно точную автоматическую производительность интернатного расстояния, особенно для онлайн -текста, возникающих в результате SNS или SMS.
Например.
"아버지가방에들어가신다." может быть расположено в ниже.
Здравый смысл, первый - правильный ответ.
PyKoSpacing основана на модели глубокого обучения, обученной крупному корпусу (более 100 миллионов новостных статей из парка Чан-Юба).
| Тестовый набор | Точность |
|---|---|
| Sejong (разговорный стиль) Корпус (1m) | 97,1% |
| Оооо (литературный стиль) корпус (3м) | 94,3% |
Предварительное условие:
proper installation of python3
proper installation of pip
pip install tensorflow
pip install keras
Windows-Ubuntu case: On following error.
On error: /usr/lib/x86_64-linux-gnu/libstdc++.so.6: version ` GLIBCXX_3.4.22 ' not found
sudo apt-get install libstdc++6
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get upgrade
sudo apt-get dist-upgrade (This takes long time.)Дарвин (M1) Случай: Вы должны установить TensorFlow по -другому. (Используйте Miniforge3)
# Install Miniforge3 for mac
curl -O https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
chmod +x Miniforge3-MacOSX-arm64.sh
sh Miniforge3-MacOSX-arm64.sh
# Activate Miniforge3 virtualenv
# You should use Python version 3.10 or less.
source ~ /miniforge3/bin/activate
# Install the Tensorflow dependencies
conda install -c apple tensorflow-deps
# Install base tensorflow
python -m pip install tensorflow-macos
# Install metal plugin
python -m pip install tensorflow-metalЧтобы установить из GitHub, используйте
pip install git+https://github.com/haven-jeon/PyKoSpacing.git
> >> from pykospacing import Spacing
> >> spacing = Spacing ()
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> # Apply a list of words that must be non-spacing
>> > spacing ( '귀밑에서턱까지잇따라난수염을구레나룻이라고한다.' )
'귀 밑에서 턱까지 잇따라 난 수염을 구레나 룻이라고 한다.'
> >> spacing = Spacing ( rules = [ '구레나룻' ])
> >> spacing ( '귀밑에서턱까지잇따라난수염을구레나룻이라고한다.' )
'귀 밑에서 턱까지 잇따라 난 수염을 구레나룻이라고 한다.' Установка правил с помощью файла CSV. (Вам нужно только использовать метод set_rules_by_csv() .)
$ cat test.csv
인덱스,단어
1,네이버영화
2,언급된단어 > >> from pykospacing import Spacing
> >> spacing = Spacing ( rules = [ '' ])
> >> spacing . set_rules_by_csv ( './test.csv' , '단어' )
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." )
"김형호 영화시장 분석가는 '1987'의 네이버영화 정보 네티즌 10점 평에서 언급된단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."Запустите командную строку (спасибо LQEZ).
$ cat test_in.txt
김형호영화시장분석가는 ' 1987 ' 의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다.
아버지가방에들어가신다.
$ python -m pykospacing.pykos test_in.txt
김형호 영화시장 분석가는 ' 1987 ' 의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다.
아버지가 방에 들어가신다. В некоторых случаях у текущей модели есть проблемы, когда ввод включает английские символы.
Pykospacing обеспечивает параметр ignore и ignore_pattern для решения этой проблемы.
О параметре ignore (STR, необязательно)
ignore='none' : предварительная/пост-обработка не будет применяться. Вывод будет таким же, как и выходной сигнал.ignore='pre' : применить предварительную обработку, которая удаляет символы, которые совпадают с ignore_pattern . Эти удаленные символы будут объединены после прогнозирования модели. У этого варианта есть проблема, что он всегда помещает место после удаленных символов, поскольку он не знает, будет ли у удаленного персонажа место слева, справа или оба из них.ignore='post' : применить пост-обработку, которая игнорирует выходы модели на символах, которые совпадают с ignore_pattern . У этой опции есть проблема с тем, что английские символы при вводе модели также могут повлиять на близких неанглийских персонажей.ignore='pre2' : применить предварительную обработку, которые удаляют символы, которые соответствуют ignore_pattern , и прогнозируйте как на предварительно обработанный текст, так и на исходном тексту . Это позволяет ему знать, куда поместить пространство влево, справа или обоих удаленных символов. Тем не менее, этот вариант требует дважды предсказать, что удваивает время вычисления.ignore='none' О параметре ignore_pattern (STR, необязательно)
Вы можете ввести свой собственный шаблон регуляции, чтобы ignore_pattern . Паттерн режима должна быть шаблоном символов, которые вы хотите игнорировать.
ignore_pattern=r'[^가-힣ㄱ-ㅣ!-@[-`{-~s]+,*( [^가-힣ㄱ-ㅣ!-@[-`{-~s]+,*)*[.,!?]* *' Примеры параметра ignore
> >> from pykospacing import Spacing
> >> spacing = Spacing ()
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'none' )
"친구와 함께 bm w 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'pre' )
"친구와 함께bmw 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'post' )
"친구와 함께 bm w 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'pre2' )
"친구와 함께 bmw 썬바이저를 썼다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'none' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한튀김 옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'pre' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다.crispy 한 튀김옷 덕에 내 입 주변은glossy 해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'post' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한튀김 옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'pre2' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한 튀김옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'none' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'pre' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램R과KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'post' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'pre2' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다." 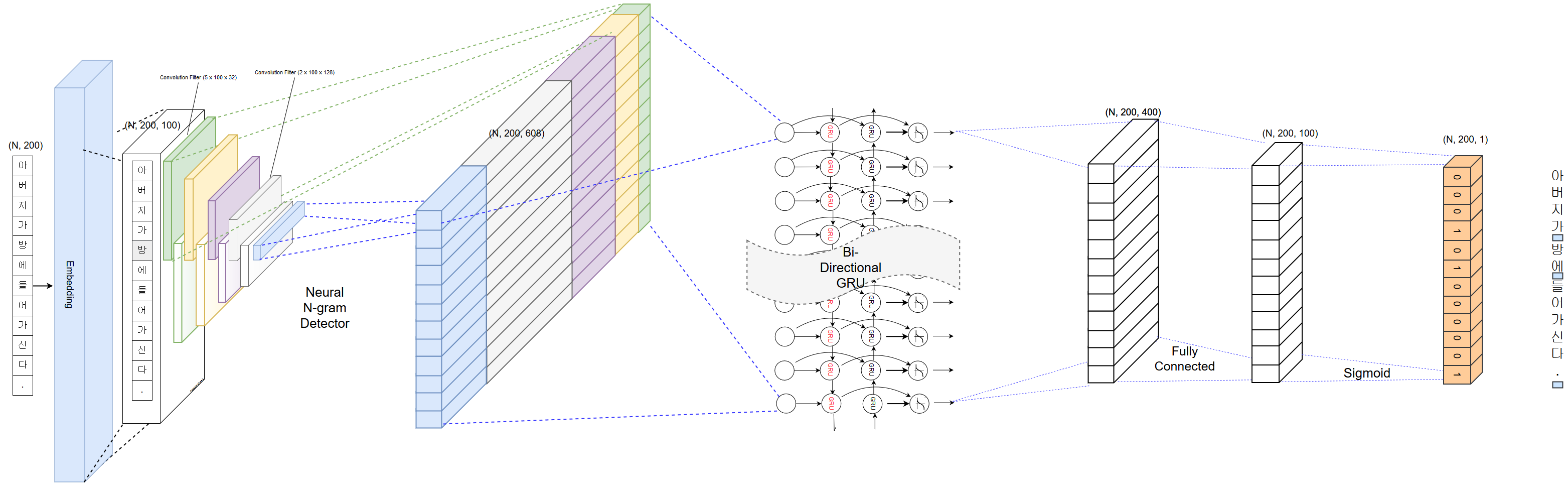
@misc{heewon2018,
author = {Heewon Jeon},
title = {KoSpacing: Automatic Korean word spacing},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/haven-jeon/KoSpacing}}


