PyKoSpacing
1.0.0
Python -Paket für den automatischen koreanischen Wortabstand.
R Verson finden Sie hier.
Der Wortabstand ist einer der wichtigsten Teile der Vorverarbeitung der koreanischen Textanalyse. Genauer Abstand wirkt sich stark auf die Genauigkeit der nachfolgenden Textanalyse aus. PyKoSpacing hat eine ziemlich genaue automatische Wortabstandsleistung, insbesondere gut für Online -Text, der aus SNS oder SMS stammt.
Zum Beispiel.
"아버지가방에들어가신다." kann beides unten beabstandet sein.
Der gesunde Menschenverstand ist die erste Antwort.
PyKoSpacing basiert auf Deep Learning-Modell, das aus dem großen Korpus ausgebildet ist (mehr als 100 Millionen Nachrichtenartikel aus dem Chan-Yub Park).
| Testset | Genauigkeit |
|---|---|
| Sejong (umgangssprachlicher Stil) Corpus (1M) | 97,1% |
| Oooo (literarischer Stil) Corpus (3M) | 94,3% |
Voraussetzung:
proper installation of python3
proper installation of pip
pip install tensorflow
pip install keras
Windows-Ubuntu case: On following error.
On error: /usr/lib/x86_64-linux-gnu/libstdc++.so.6: version ` GLIBCXX_3.4.22 ' not found
sudo apt-get install libstdc++6
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get upgrade
sudo apt-get dist-upgrade (This takes long time.)DARWIN (M1) Fall: Sie sollten TensorFlow auf andere Weise installieren. (Verwenden Sie Miniforge3)
# Install Miniforge3 for mac
curl -O https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
chmod +x Miniforge3-MacOSX-arm64.sh
sh Miniforge3-MacOSX-arm64.sh
# Activate Miniforge3 virtualenv
# You should use Python version 3.10 or less.
source ~ /miniforge3/bin/activate
# Install the Tensorflow dependencies
conda install -c apple tensorflow-deps
# Install base tensorflow
python -m pip install tensorflow-macos
# Install metal plugin
python -m pip install tensorflow-metalVerwenden Sie zur Installation von GitHub
pip install git+https://github.com/haven-jeon/PyKoSpacing.git
> >> from pykospacing import Spacing
> >> spacing = Spacing ()
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> # Apply a list of words that must be non-spacing
>> > spacing ( '귀밑에서턱까지잇따라난수염을구레나룻이라고한다.' )
'귀 밑에서 턱까지 잇따라 난 수염을 구레나 룻이라고 한다.'
> >> spacing = Spacing ( rules = [ '구레나룻' ])
> >> spacing ( '귀밑에서턱까지잇따라난수염을구레나룻이라고한다.' )
'귀 밑에서 턱까지 잇따라 난 수염을 구레나룻이라고 한다.' Festlegen von Regeln mit CSV -Datei. (Sie müssen nur set_rules_by_csv() Methode verwenden.)
$ cat test.csv
인덱스,단어
1,네이버영화
2,언급된단어 > >> from pykospacing import Spacing
> >> spacing = Spacing ( rules = [ '' ])
> >> spacing . set_rules_by_csv ( './test.csv' , '단어' )
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." )
"김형호 영화시장 분석가는 '1987'의 네이버영화 정보 네티즌 10점 평에서 언급된단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."Ausführen in Befehlszeile (danke lqez).
$ cat test_in.txt
김형호영화시장분석가는 ' 1987 ' 의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다.
아버지가방에들어가신다.
$ python -m pykospacing.pykos test_in.txt
김형호 영화시장 분석가는 ' 1987 ' 의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다.
아버지가 방에 들어가신다. Das aktuelle Modell hat in einigen Fällen Probleme, wenn die Eingabe englische Zeichen enthält.
Pykospacing liefert den Parameter ignore und ignore_pattern um dieses Problem zu lösen.
Über den Parameter ignore (STR, optional)
ignore='none' : Es wird keine Vor-/Nachbearbeitung angewendet. Die Ausgabe entspricht der Modellausgabe.ignore='pre' : Vorverarbeitung anwenden, die Zeichen löscht, die mit ignore_pattern übereinstimmen. Diese gelöschten Zeichen werden nach der Modellvorhersage zusammengeführt. Diese Option hat das Problem, dass sie nach den gelöschten Zeichen immer Platz legt, da sie nicht weiß, ob der gelöschte Charakter einen Platz links, rechts oder beide hat.ignore='post' : Anwenden Sie Nachbearbeitung an, die Modellausgaben für Zeichen ignoriert, die mit ignore_pattern übereinstimmen. Diese Option hat das Problem, dass englische Charaktere in der Modelleingabe auch nahezu nicht englische Charaktere beeinflussen können.ignore='pre2' : Anwenden Sie das Vorverarbeitung an, das Zeichen löscht, die mit ignore_pattern übereinstimmen, und sowohl auf dem vorverarbeiteten Text als auch auf dem ursprünglichen Text vorhersagen. Auf diese Weise kann es wissen, wo sich der Platz links, rechts oder beide der gelöschten Zeichen platzieren kann. Diese Option erfordert jedoch, dass sie zweimal vorhergesagt werden, was die Berechnungszeit verdoppelt.ignore='none' Über den Parameter ignore_pattern (STR, optional)
Sie können Ihr eigenes Regex -Muster in ignore_pattern eingeben. Das Regex -Muster sollte das Muster der Zeichen sein, das Sie ignorieren möchten.
ignore_pattern=r'[^가-힣ㄱ-ㅣ!-@[-`{-~s]+,*( [^가-힣ㄱ-ㅣ!-@[-`{-~s]+,*)*[.,!?]* *' Beispiele für den Parameter ignore
> >> from pykospacing import Spacing
> >> spacing = Spacing ()
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'none' )
"친구와 함께 bm w 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'pre' )
"친구와 함께bmw 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'post' )
"친구와 함께 bm w 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'pre2' )
"친구와 함께 bmw 썬바이저를 썼다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'none' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한튀김 옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'pre' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다.crispy 한 튀김옷 덕에 내 입 주변은glossy 해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'post' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한튀김 옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'pre2' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한 튀김옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'none' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'pre' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램R과KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'post' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'pre2' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다." 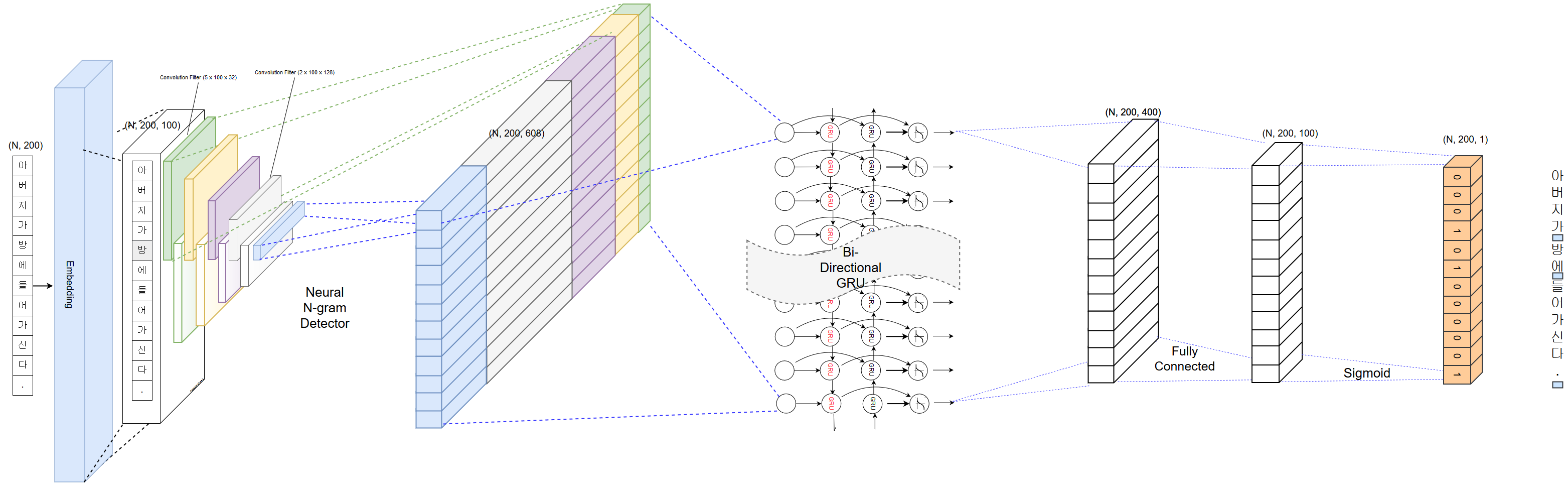
@misc{heewon2018,
author = {Heewon Jeon},
title = {KoSpacing: Automatic Korean word spacing},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/haven-jeon/KoSpacing}}


