PyKoSpacing
1.0.0
Pacote Python para espaçamento automático de palavras coreanas.
R Verson pode ser encontrado aqui.
O espaçamento das palavras é uma das partes importantes do pré -processamento da análise de texto coreano. O espaçamento preciso afeta bastante a precisão da análise de texto subsequente. PyKoSpacing possui desempenho automático de espaçamento de palavras bastante preciso, especialmente bom para o texto on -line originado de SNS ou SMS.
Por exemplo.
"아버지가방에들어가신다." pode ser espaçado os dois abaixo.
Senso comum, o primeiro é a resposta certa.
PyKoSpacing é baseado no modelo de aprendizado profundo treinado em grandes corpus (mais de 100 milhões de artigos de notícias do Chan-Yub Park).
| Conjunto de testes | Precisão |
|---|---|
| Sejong (estilo coloquial) corpus (1m) | 97,1% |
| Oooo (estilo literário) corpus (3m) | 94,3% |
Pré-requisito:
proper installation of python3
proper installation of pip
pip install tensorflow
pip install keras
Windows-Ubuntu case: On following error.
On error: /usr/lib/x86_64-linux-gnu/libstdc++.so.6: version ` GLIBCXX_3.4.22 ' not found
sudo apt-get install libstdc++6
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get upgrade
sudo apt-get dist-upgrade (This takes long time.)Caso de Darwin (M1): você deve instalar o Tensorflow de uma maneira diferente. (Use Miniforge3)
# Install Miniforge3 for mac
curl -O https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
chmod +x Miniforge3-MacOSX-arm64.sh
sh Miniforge3-MacOSX-arm64.sh
# Activate Miniforge3 virtualenv
# You should use Python version 3.10 or less.
source ~ /miniforge3/bin/activate
# Install the Tensorflow dependencies
conda install -c apple tensorflow-deps
# Install base tensorflow
python -m pip install tensorflow-macos
# Install metal plugin
python -m pip install tensorflow-metalPara instalar no GitHub, use
pip install git+https://github.com/haven-jeon/PyKoSpacing.git
> >> from pykospacing import Spacing
> >> spacing = Spacing ()
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> # Apply a list of words that must be non-spacing
>> > spacing ( '귀밑에서턱까지잇따라난수염을구레나룻이라고한다.' )
'귀 밑에서 턱까지 잇따라 난 수염을 구레나 룻이라고 한다.'
> >> spacing = Spacing ( rules = [ '구레나룻' ])
> >> spacing ( '귀밑에서턱까지잇따라난수염을구레나룻이라고한다.' )
'귀 밑에서 턱까지 잇따라 난 수염을 구레나룻이라고 한다.' Definir regras com o arquivo CSV. (Você só precisa usar o método set_rules_by_csv() .)
$ cat test.csv
인덱스,단어
1,네이버영화
2,언급된단어 > >> from pykospacing import Spacing
> >> spacing = Spacing ( rules = [ '' ])
> >> spacing . set_rules_by_csv ( './test.csv' , '단어' )
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." )
"김형호 영화시장 분석가는 '1987'의 네이버영화 정보 네티즌 10점 평에서 언급된단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."Execute na linha de comando (obrigado lqez).
$ cat test_in.txt
김형호영화시장분석가는 ' 1987 ' 의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다.
아버지가방에들어가신다.
$ python -m pykospacing.pykos test_in.txt
김형호 영화시장 분석가는 ' 1987 ' 의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다.
아버지가 방에 들어가신다. O modelo atual tem problemas em alguns casos em que a entrada inclui caracteres em inglês.
O pykospacing fornece o parâmetro ignore e ignore_pattern para lidar com esse problema.
Sobre o parâmetro ignore (STR, opcional)
ignore='none' : nenhum pré/pós-processamento será aplicado. A saída será a mesma que a saída do modelo.ignore='pre' : aplique pré-processamento que exclui caracteres que correspondem ao ignore_pattern . Esses caracteres excluídos serão mesclados após a previsão do modelo. Essa opção tem o problema de que sempre coloca espaço após os caracteres excluídos, pois não sabe se o personagem excluído terá um espaço para a esquerda, direita ou ambos.ignore='post' : aplique pós-processamento que ignora as saídas do modelo em caracteres que correspondem ao ignore_pattern . Esta opção tem o problema de que os caracteres em inglês na entrada do modelo também podem afetar os caracteres quase ingleses.ignore='pre2' : aplique pré-processamento que exclua caracteres que correspondem ao ignore_pattern e prevê o texto pré-processado e o texto original . Isso permite que ele saiba onde colocar o espaço esquerdo, direita ou ambos os caracteres excluídos. No entanto, essa opção requer prever duas vezes , que dobra o tempo de computação.ignore='none' Sobre o parâmetro ignore_pattern (STR, opcional)
Você pode inserir seu próprio padrão regex para ignore_pattern . O padrão Regex deve ser o padrão dos caracteres que você deseja ignorar.
ignore_pattern=r'[^가-힣ㄱ-ㅣ!-@[-`{-~s]+,*( [^가-힣ㄱ-ㅣ!-@[-`{-~s]+,*)*[.,!?]* *' , Que combina caracteres, palavras, ou uma sessão não, não-kn e não-kn e não, que não é um dos caracteres, ou não, ou não, ou não, que não se sente, e não, que não. Exemplos de parâmetro ignore
> >> from pykospacing import Spacing
> >> spacing = Spacing ()
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'none' )
"친구와 함께 bm w 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'pre' )
"친구와 함께bmw 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'post' )
"친구와 함께 bm w 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'pre2' )
"친구와 함께 bmw 썬바이저를 썼다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'none' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한튀김 옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'pre' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다.crispy 한 튀김옷 덕에 내 입 주변은glossy 해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'post' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한튀김 옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'pre2' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한 튀김옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'none' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'pre' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램R과KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'post' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'pre2' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다." 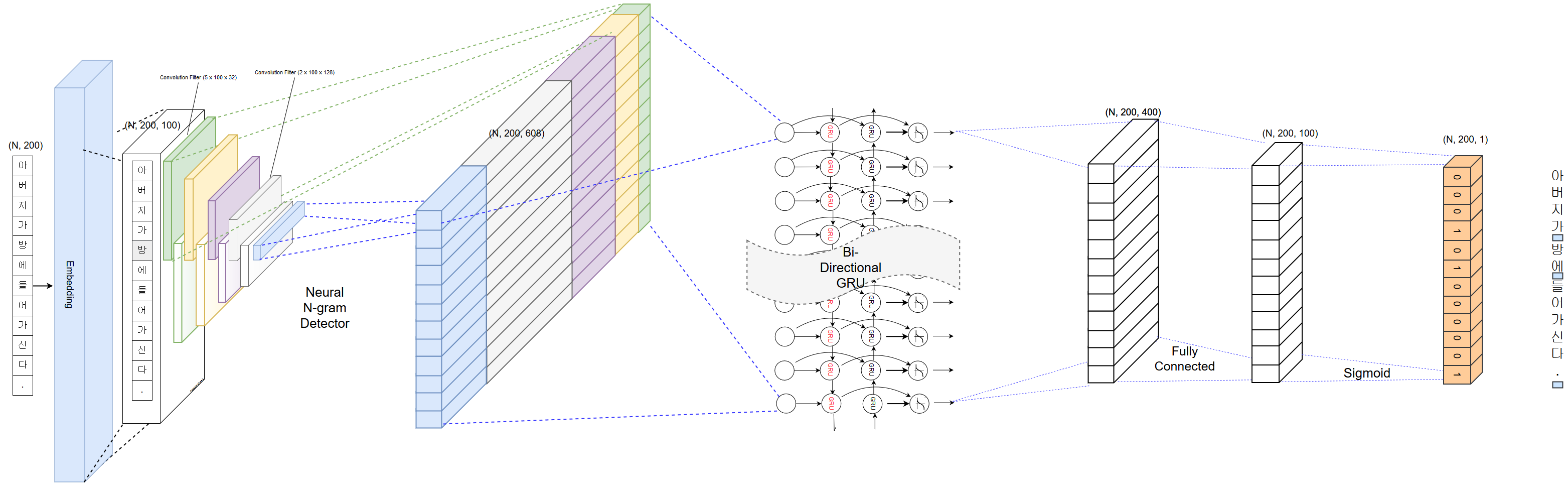
@misc{heewon2018,
author = {Heewon Jeon},
title = {KoSpacing: Automatic Korean word spacing},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/haven-jeon/KoSpacing}}


