PyKoSpacing
1.0.0
자동 한국어 간격을위한 파이썬 패키지.
R Verson은 여기에서 찾을 수 있습니다.
단어 간격은 한국어 텍스트 분석 전처리의 중요한 부분 중 하나입니다. 정확한 간격은 후속 텍스트 분석의 정확도에 큰 영향을 미칩니다. PyKoSpacing 상당히 정확한 자동 워드 간격 성능을 가지고 있으며, 특히 SNS 또는 SMS에서 유래 한 온라인 텍스트에 적합합니다.
예를 들어.
"아버지가방에들어가신다." 아래 모두에서 간격을 가질 수 있습니다.
상식, 첫 번째는 정답입니다.
PyKoSpacing 큰 코퍼스 (Chan-Yub Park의 1 억 개 이상의 뉴스 기사)에서 훈련 된 딥 러닝 모델을 기반으로합니다.
| 테스트 세트 | 정확성 |
|---|---|
| 세종 (구어체 스타일) 코퍼스 (1m) | 97.1% |
| OOOO (문학적 스타일) 코퍼스 (3m) | 94.3% |
전제 조건 :
proper installation of python3
proper installation of pip
pip install tensorflow
pip install keras
Windows-Ubuntu case: On following error.
On error: /usr/lib/x86_64-linux-gnu/libstdc++.so.6: version ` GLIBCXX_3.4.22 ' not found
sudo apt-get install libstdc++6
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get upgrade
sudo apt-get dist-upgrade (This takes long time.)다윈 (M1) 케이스 : 다른 방식으로 텐서 플로를 설치해야합니다. (Miniforge3 사용)
# Install Miniforge3 for mac
curl -O https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
chmod +x Miniforge3-MacOSX-arm64.sh
sh Miniforge3-MacOSX-arm64.sh
# Activate Miniforge3 virtualenv
# You should use Python version 3.10 or less.
source ~ /miniforge3/bin/activate
# Install the Tensorflow dependencies
conda install -c apple tensorflow-deps
# Install base tensorflow
python -m pip install tensorflow-macos
# Install metal plugin
python -m pip install tensorflow-metalGithub에서 설치하려면 사용하십시오
pip install git+https://github.com/haven-jeon/PyKoSpacing.git
> >> from pykospacing import Spacing
> >> spacing = Spacing ()
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> # Apply a list of words that must be non-spacing
>> > spacing ( '귀밑에서턱까지잇따라난수염을구레나룻이라고한다.' )
'귀 밑에서 턱까지 잇따라 난 수염을 구레나 룻이라고 한다.'
> >> spacing = Spacing ( rules = [ '구레나룻' ])
> >> spacing ( '귀밑에서턱까지잇따라난수염을구레나룻이라고한다.' )
'귀 밑에서 턱까지 잇따라 난 수염을 구레나룻이라고 한다.' CSV 파일로 규칙을 설정합니다. ( set_rules_by_csv() 메소드 만 사용하면됩니다.)
$ cat test.csv
인덱스,단어
1,네이버영화
2,언급된단어 > >> from pykospacing import Spacing
> >> spacing = Spacing ( rules = [ '' ])
> >> spacing . set_rules_by_csv ( './test.csv' , '단어' )
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." )
"김형호 영화시장 분석가는 '1987'의 네이버영화 정보 네티즌 10점 평에서 언급된단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."명령 줄에서 실행됩니다 (감사합니다 LQEZ).
$ cat test_in.txt
김형호영화시장분석가는 ' 1987 ' 의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다.
아버지가방에들어가신다.
$ python -m pykospacing.pykos test_in.txt
김형호 영화시장 분석가는 ' 1987 ' 의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다.
아버지가 방에 들어가신다. 현재 모델에는 입력에 영어 문자가 포함 된 경우 경우에도 문제가 있습니다.
Pykospacing은 매개 변수를 ignore 하고이 문제를 처리하기 위해 ignore_pattern 제공합니다.
매개 변수 ignore 에 대해 (str, 선택 사항)
ignore='none' : 사전/사후 처리는 적용되지 않습니다. 출력은 모델 출력과 동일합니다.ignore='pre' : ignore_pattern 과 일치하는 문자를 삭제하는 사전 처리를 적용하십시오. 이 삭제 된 문자는 모델 예측 후에 병합됩니다. 이 옵션은 삭제 된 문자가 왼쪽, 오른쪽 또는 둘 다에 공간이 있는지 알 수 없기 때문에 삭제 된 문자 이후에 항상 공간을 두는 문제가 있습니다.ignore='post' : ignore_pattern 과 일치하는 문자에 대한 모델 출력을 무시하는 사후 처리를 적용하십시오. 이 옵션은 모델 입력의 영어 문자가 영어가 아닌 문자에 영향을 줄 수 있다는 문제가 있습니다.ignore='pre2' : ignore_pattern 과 일치하는 문자를 삭제하는 사전 프로세싱을 적용하고 전처리 텍스트와 원본 텍스트를 모두 예측하십시오. 이를 통해 공간을 왼쪽, 오른쪽 또는 삭제 된 문자를 모두 알 수 있습니다. 그러나이 옵션은 두 번 예측해야하므로 계산 시간을 두 배로 늘립니다.ignore='none' ignore_pattern 매개 변수 소개 (str, 선택 사항)
자신의 정규 패턴을 입력하여 ignore_pattern 입력 할 수 있습니다. Regex 패턴은 무시하고자하는 캐릭터의 패턴이어야합니다.
ignore_pattern=r'[^가-힣ㄱ-ㅣ!-@[-`{-~s]+,*( [^가-힣ㄱ-ㅣ!-@[-`{-~s]+,*)*[.,!?]* *' . ignore 매개 변수의 예
> >> from pykospacing import Spacing
> >> spacing = Spacing ()
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'none' )
"친구와 함께 bm w 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'pre' )
"친구와 함께bmw 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'post' )
"친구와 함께 bm w 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'pre2' )
"친구와 함께 bmw 썬바이저를 썼다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'none' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한튀김 옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'pre' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다.crispy 한 튀김옷 덕에 내 입 주변은glossy 해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'post' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한튀김 옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'pre2' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한 튀김옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'none' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'pre' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램R과KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'post' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'pre2' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다." 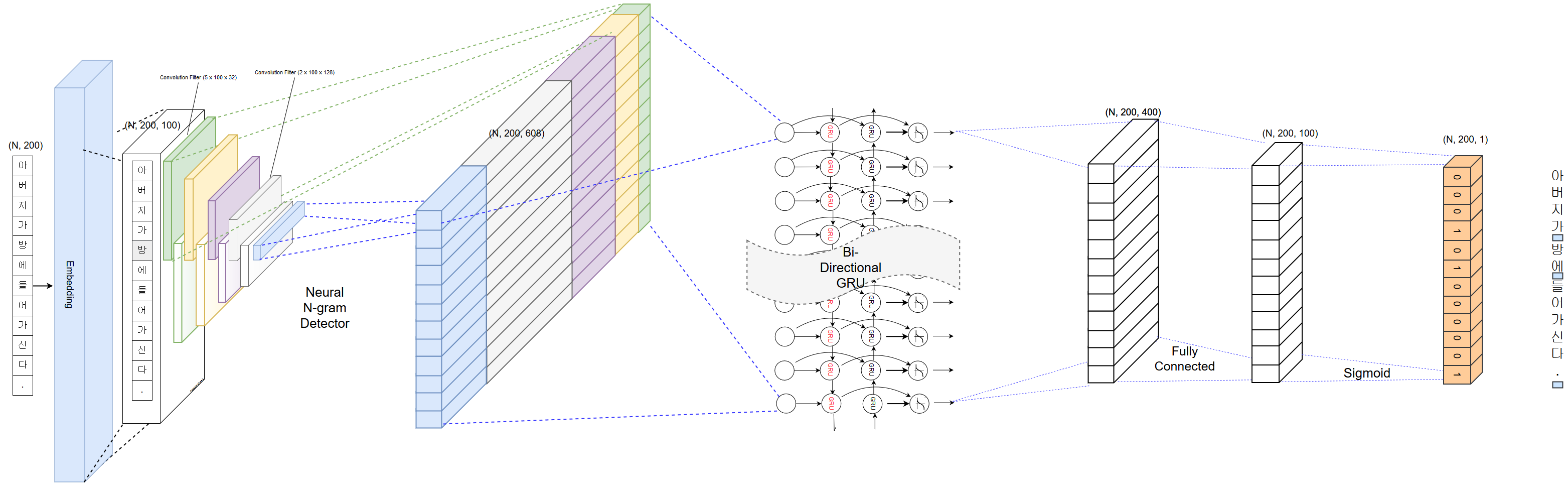
@misc{heewon2018,
author = {Heewon Jeon},
title = {KoSpacing: Automatic Korean word spacing},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/haven-jeon/KoSpacing}}


