PyKoSpacing
1.0.0
Paquete de Python para espaciado automático de palabras coreanas.
R Verson se puede encontrar aquí.
El espaciado de palabras es una de las partes importantes del preprocesamiento del análisis de texto coreano. El espacio preciso afecta en gran medida la precisión del análisis de texto posterior. PyKoSpacing tiene un rendimiento de separación de palabras automático bastante preciso, especialmente bueno para el texto en línea originado por SNS o SMS.
Por ejemplo.
"아버지가방에들어가신다". se pueden espaciar a continuación.
Sentido común, el primero es la respuesta correcta.
PyKoSpacing se basa en un modelo de aprendizaje profundo capacitado de gran cuerpo (más de 100 millones de artículos de noticias del Parque Chan-Yub).
| Set de prueba | Exactitud |
|---|---|
| Sejong (estilo coloquial) Corpus (1m) | 97.1% |
| OOOO (estilo literario) Corpus (3m) | 94.3% |
Requisito previo:
proper installation of python3
proper installation of pip
pip install tensorflow
pip install keras
Windows-Ubuntu case: On following error.
On error: /usr/lib/x86_64-linux-gnu/libstdc++.so.6: version ` GLIBCXX_3.4.22 ' not found
sudo apt-get install libstdc++6
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get upgrade
sudo apt-get dist-upgrade (This takes long time.)Caso Darwin (M1): debe instalar TensorFlow de una manera diferente. (Use Miniforge3)
# Install Miniforge3 for mac
curl -O https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge3-MacOSX-arm64.sh
chmod +x Miniforge3-MacOSX-arm64.sh
sh Miniforge3-MacOSX-arm64.sh
# Activate Miniforge3 virtualenv
# You should use Python version 3.10 or less.
source ~ /miniforge3/bin/activate
# Install the Tensorflow dependencies
conda install -c apple tensorflow-deps
# Install base tensorflow
python -m pip install tensorflow-macos
# Install metal plugin
python -m pip install tensorflow-metalPara instalar desde Github, use
pip install git+https://github.com/haven-jeon/PyKoSpacing.git
> >> from pykospacing import Spacing
> >> spacing = Spacing ()
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> # Apply a list of words that must be non-spacing
>> > spacing ( '귀밑에서턱까지잇따라난수염을구레나룻이라고한다.' )
'귀 밑에서 턱까지 잇따라 난 수염을 구레나 룻이라고 한다.'
> >> spacing = Spacing ( rules = [ '구레나룻' ])
> >> spacing ( '귀밑에서턱까지잇따라난수염을구레나룻이라고한다.' )
'귀 밑에서 턱까지 잇따라 난 수염을 구레나룻이라고 한다.' Configuración de reglas con archivo CSV. (Solo necesita usar el método set_rules_by_csv() .)
$ cat test.csv
인덱스,단어
1,네이버영화
2,언급된단어 > >> from pykospacing import Spacing
> >> spacing = Spacing ( rules = [ '' ])
> >> spacing . set_rules_by_csv ( './test.csv' , '단어' )
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." )
"김형호 영화시장 분석가는 '1987'의 네이버영화 정보 네티즌 10점 평에서 언급된단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."Ejecute en la línea de comandos (gracias LQEZ).
$ cat test_in.txt
김형호영화시장분석가는 ' 1987 ' 의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다.
아버지가방에들어가신다.
$ python -m pykospacing.pykos test_in.txt
김형호 영화시장 분석가는 ' 1987 ' 의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다.
아버지가 방에 들어가신다. El modelo actual tiene problemas en algunos casos cuando la entrada incluye caracteres ingleses.
Pykospacing proporciona el parámetro ignore e ignore_pattern para lidiar con ese problema.
Acerca de ignore el parámetro (STR, opcional)
ignore='none' : no se aplicará pre/postprocesamiento. La salida será la misma que la salida del modelo.ignore='pre' : aplique el preprocesamiento que elimina los caracteres que coinciden con ignore_pattern . Estos personajes eliminados se fusionarán después de la predicción del modelo. Esta opción tiene el problema de que siempre pone espacio después de los caracteres eliminados, ya que no sabe si el personaje eliminado tendrá un espacio a la izquierda, a la derecha o a los dos.ignore='post' : aplique el procesamiento posterior que ignora las salidas del modelo en caracteres que coinciden con ignore_pattern . Esta opción tiene el problema que los caracteres ingleses en la entrada del modelo también pueden afectar los caracteres casi no ingleses.ignore='pre2' : aplique el preprocesamiento que elimine los caracteres que coinciden con ignore_pattern , y predicen tanto en texto preprocesado como en texto original . Esto le permite saber dónde poner espacio a la izquierda, a la derecha o ambos personajes eliminados. Sin embargo, esta opción requiere predecir dos veces , lo que duplica el tiempo de cálculo.ignore='none' Acerca del parámetro ignore_pattern (STR, Opcional)
Puede ingresar su propio patrón regex para ignore_pattern . El patrón regex debe ser el patrón de los caracteres que desea ignorar.
ignore_pattern=r'[^가-힣ㄱ-ㅣ!-@[-`{-~s]+,*( [^가-힣ㄱ-ㅣ!-@[-`{-~s]+,*)*[.,!?]* *' Ejemplos de parámetro ignore
> >> from pykospacing import Spacing
> >> spacing = Spacing ()
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'none' )
"친구와 함께 bm w 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'pre' )
"친구와 함께bmw 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'post' )
"친구와 함께 bm w 썬바이저를 썼다."
> >> spacing ( "친구와함께bmw썬바이저를썼다." , ignore = 'pre2' )
"친구와 함께 bmw 썬바이저를 썼다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'none' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한튀김 옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'pre' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다.crispy 한 튀김옷 덕에 내 입 주변은glossy 해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'post' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한튀김 옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "chicken박스를열고닭다리를꺼내입에문다.crispy한튀김옷덕에내입주변은glossy해진다." , ignore = 'pre2' )
"chicken박스를 열고 닭다리를 꺼내 입에 문다. crispy 한 튀김옷 덕에 내 입 주변은 glossy해진다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'none' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'pre' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램R과KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'post' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다."
> >> spacing ( "김형호영화시장분석가는'1987'의네이버영화정보네티즌10점평에서언급된단어들을지난해12월27일부터올해1월10일까지통계프로그램R과KoNLP패키지로텍스트마이닝하여분석했다." , ignore = 'pre2' )
"김형호 영화시장 분석가는 '1987'의 네이버 영화 정보 네티즌 10점 평에서 언급된 단어들을 지난해 12월 27일부터 올해 1월 10일까지 통계 프로그램 R과 KoNLP 패키지로 텍스트마이닝하여 분석했다." 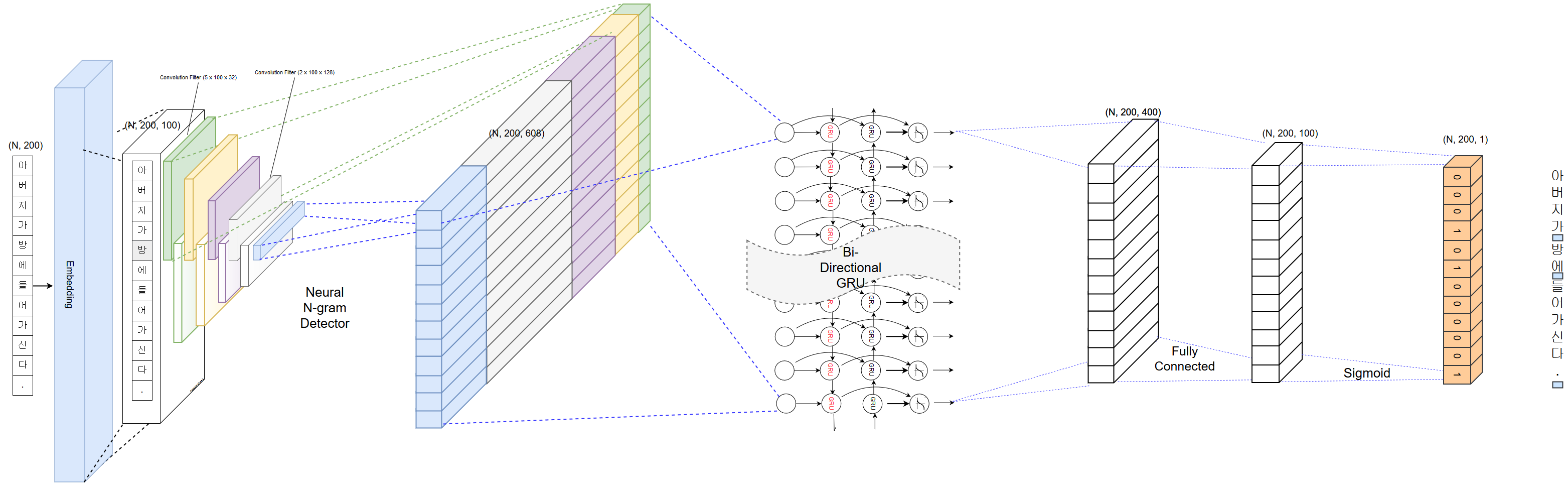
@misc{heewon2018,
author = {Heewon Jeon},
title = {KoSpacing: Automatic Korean word spacing},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/haven-jeon/KoSpacing}}


