Zemi
1.0.0
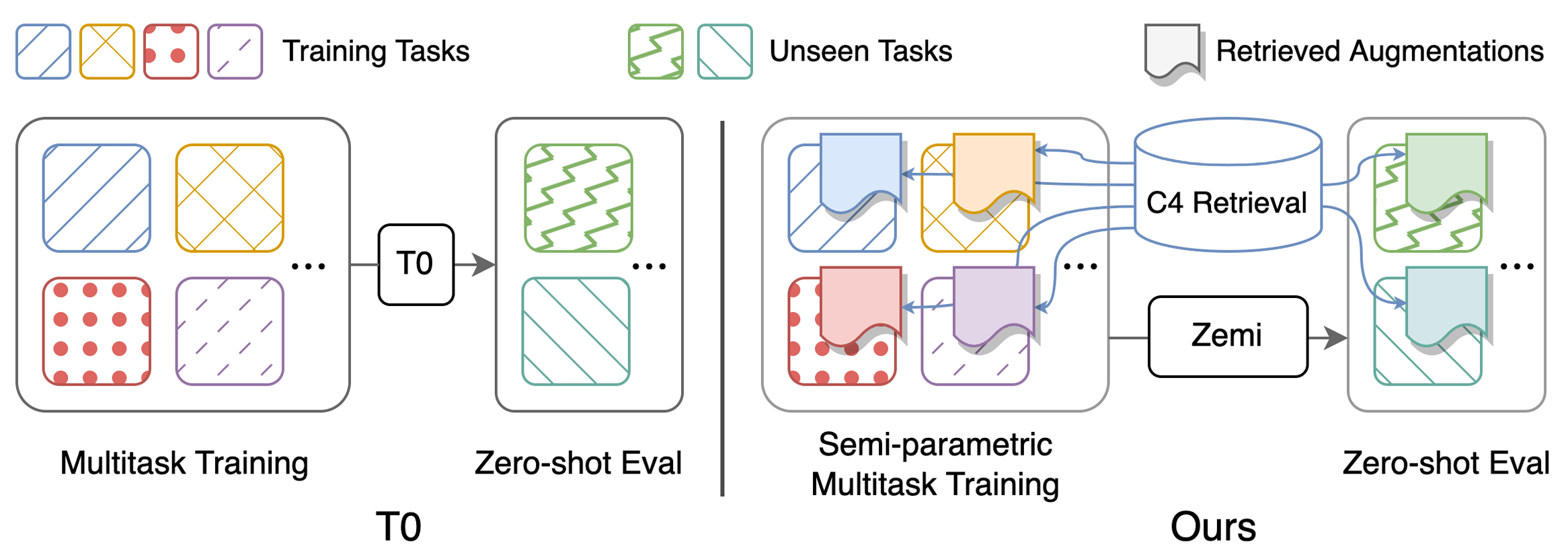
Инструкции по загрузке предварительно обработанных наборов данных и наборов данных о приготовлении костюмов можно найти здесь
Скачать checkpoints с: https://uofi.box.com/s/wnt6cv7icuir4q3wb2a6viuyklme5dga. Поместите каталоги контрольных точек в checkpoints под zemi/output/p3_finetuning
Установите среду Conda с conda env create -f environment.yml . Запустите accelerate config для конфигурации устройства.
Сценарии для воспроизведения основных результатов в таблице 1: Выполнение (полу-) параметрическое многозадачное обучение и оценка с нулевым выстрелом. Подробные инструкции по конфигурациям можно найти здесь. Все сценарии должны быть запускаются под zemi/ . SETUP_ENV.sh будет вызвана в следующих сценариях для настройки переменных ENV. Можно изменить переменные, если не использовать ту же самую и ту же структуру папок, что и настройка выше.
bash ./training/no_aug_base.shbash ./training/no_aug_large.shbash ./training/concat_base.shbash ./training/concat_large.shbash ./training/fid_base.shbash ./training/fid_large.shbash ./training/zemi_base.shbash ./training/zemi_large.sh zemi/modeling_t5.py из этой строки и zemi/modeling_xattn.pyzemi/multi_task_fine_tune_baseline.pyzemi/multi_task_fine_tune_xattn.pyzemi/eval_original_task_only.pyzemi/eval_original_task_only_xattn.py visualization/ содержит примеры полученных документов для каждой задачи. Мы включаем 50 лучших примеров с самыми высокими и самыми низкими показателями BM25 в visualization/top50_highest_score_retrieval_instances и visualization/top50_lowest_score_retrieval_instances . Мы также включаем первые 50 экземпляров для каждого набора данных без повторного порядка в visualization/first50_retrieval_instances .
@article{wang2022zemi,
title={Zemi: Learning Zero-Shot Semi-Parametric Language Models from Multiple Tasks},
author={Wang, Zhenhailong and Pan, Xiaoman and Yu, Dian and Yu, Dong and Chen, Jianshu and Ji, Heng},
journal={arXiv preprint arXiv:2210.00185},
year={2022}
}


