Zemi
1.0.0
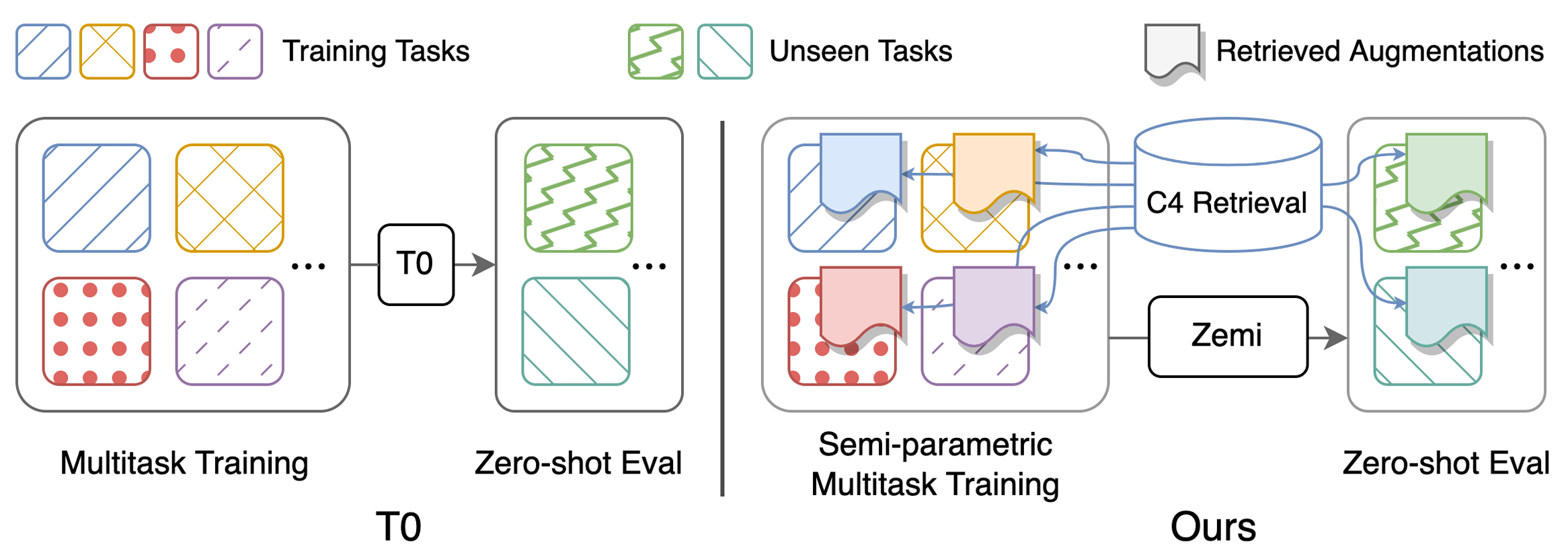
Anweisungen zum Herunterladen vorbereiteter Datensätze und zum Vorab -Kostüm -Datensätzen finden Sie hier
Laden Sie checkpoints von: https://uofi.box.box/s/wnt6cv7icuir4q3wb2a6viuyklme5dga herunter. Legen Sie die Kontrollpunkte in checkpoints unter zemi/output/p3_finetuning
Richten Sie Conda Environment mit conda env create -f environment.yml . Führen Sie accelerate config aus, um das Gerät zu konfigurieren.
Skripte zur Reproduktion der Hauptergebnisse in Tabelle 1: Durchführung (semi-) parametrische Multitasking führte zum Training und der Null-Shot-Bewertung auf. Detaillierte Anweisungen zu den Konfigurationen finden Sie hier. Alle Skripte sollten unter zemi/ ausgeführt werden. SETUP_ENV.sh wird in den folgenden Skripten aufgerufen, um Env -Variablen einzurichten. Man kann die Variablen ändern, wenn nicht die exakt gleiche Ordnerstruktur wie oben eingerichtet wird.
bash ./training/no_aug_base.shbash ./training/no_aug_large.shbash ./training/concat_base.shbash ./training/concat_large.shbash ./training/fid_base.shbash ./training/fid_large.shbash ./training/zemi_base.shbash ./training/zemi_large.sh zemi/modeling_t5.py aus dieser Zeile und zemi/modeling_xattn.pyzemi/multi_task_fine_tune_baseline.pyzemi/multi_task_fine_tune_xattn.pyzemi/eval_original_task_only.pyzemi/eval_original_task_only_xattn.py visualization/ Enthält Beispiele für die abgerufenen Dokumente für jede Aufgabe. Wir enthalten die Top 50 Beispiele mit den höchsten und niedrigsten BM25 -Ergebnissen in visualization/top50_highest_score_retrieval_instances und visualization/top50_lowest_score_retrieval_instances . Wir fügen auch die ersten 50 Instanzen für jeden Datensatz ein, ohne in visualization/first50_retrieval_instances neu zu ordnen.
@article{wang2022zemi,
title={Zemi: Learning Zero-Shot Semi-Parametric Language Models from Multiple Tasks},
author={Wang, Zhenhailong and Pan, Xiaoman and Yu, Dian and Yu, Dong and Chen, Jianshu and Ji, Heng},
journal={arXiv preprint arXiv:2210.00185},
year={2022}
}


