Zemi
1.0.0
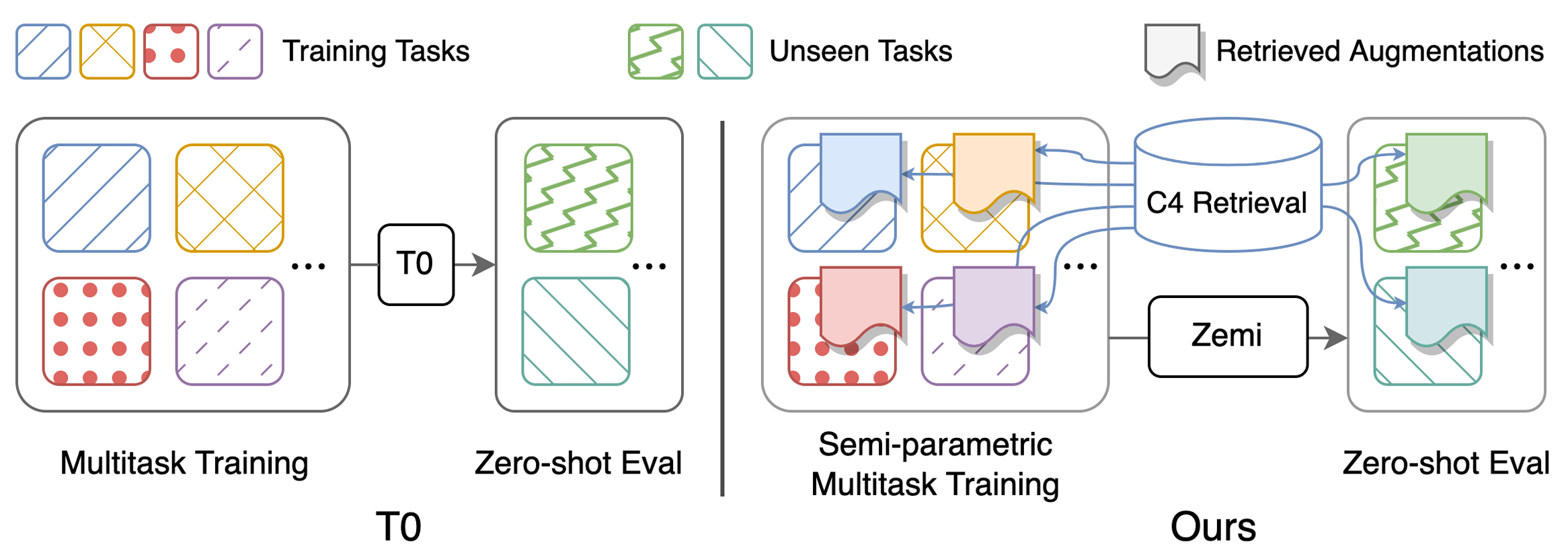
Instruções sobre o download de conjuntos de dados pré -processados e conjuntos de dados de fantasia pré -prática podem ser encontrados aqui
Faça o download checkpoints de: https://uofi.box.com/s/wnt6cv7icuir4q3wb2a6viuyklme5dga. Coloque os diretórios dos pontos de verificação em checkpoints em zemi/output/p3_finetuning
Configure o ambiente do CONDA com conda env create -f environment.yml . Execute accelerate config para configurar o dispositivo.
Scripts para reproduzir os principais resultados na Tabela 1: executando (semi-) multitarefa paramétrica solicitou treinamento e avaliação de tiro zero. Instruções detalhadas sobre as configurações podem ser encontradas aqui. Todos os scripts devem ser executados em zemi/ . SETUP_ENV.sh será chamado nos seguintes scripts para configurar variáveis ENV. Pode -se modificar as variáveis se não estiver usando exatamente a mesma estrutura de pasta da configuração acima.
bash ./training/no_aug_base.shbash ./training/no_aug_large.shbash ./training/concat_base.shbash ./training/concat_large.shbash ./training/fid_base.shbash ./training/fid_large.shbash ./training/zemi_base.shbash ./training/zemi_large.sh zemi/modeling_t5.py desta linha e zemi/modeling_xattn.pyzemi/multi_task_fine_tune_baseline.pyzemi/multi_task_fine_tune_xattn.pyzemi/eval_original_task_only.pyzemi/eval_original_task_only_xattn.py visualization/ contém exemplos dos documentos recuperados para cada tarefa. Incluímos os 50 principais exemplos com as pontuações BM25 mais altas e mais baixas em visualization/top50_highest_score_retrieval_instances e visualization/top50_lowest_score_retrieval_instances . Também incluímos as primeiras 50 instâncias para cada conjunto de dados sem reordenar em visualization/first50_retrieval_instances .
@article{wang2022zemi,
title={Zemi: Learning Zero-Shot Semi-Parametric Language Models from Multiple Tasks},
author={Wang, Zhenhailong and Pan, Xiaoman and Yu, Dian and Yu, Dong and Chen, Jianshu and Ji, Heng},
journal={arXiv preprint arXiv:2210.00185},
year={2022}
}


