Zemi
1.0.0
事前に処理されたデータセットのダウンロードと事前にコスチュームデータセットをこちらにご覧いただけます。
checkpointsをダウンロード:https://uofi.box.com/s/wnt6cv7icuir4q3wb2a6viuyklme5dga。チェックポイントディレクトリをzemi/output/p3_finetuningの下にcheckpointsに置きます
conda env create -f environment.ymlを使用してConda環境をセットアップします。 accelerate configを実行して、デバイスを構成します。
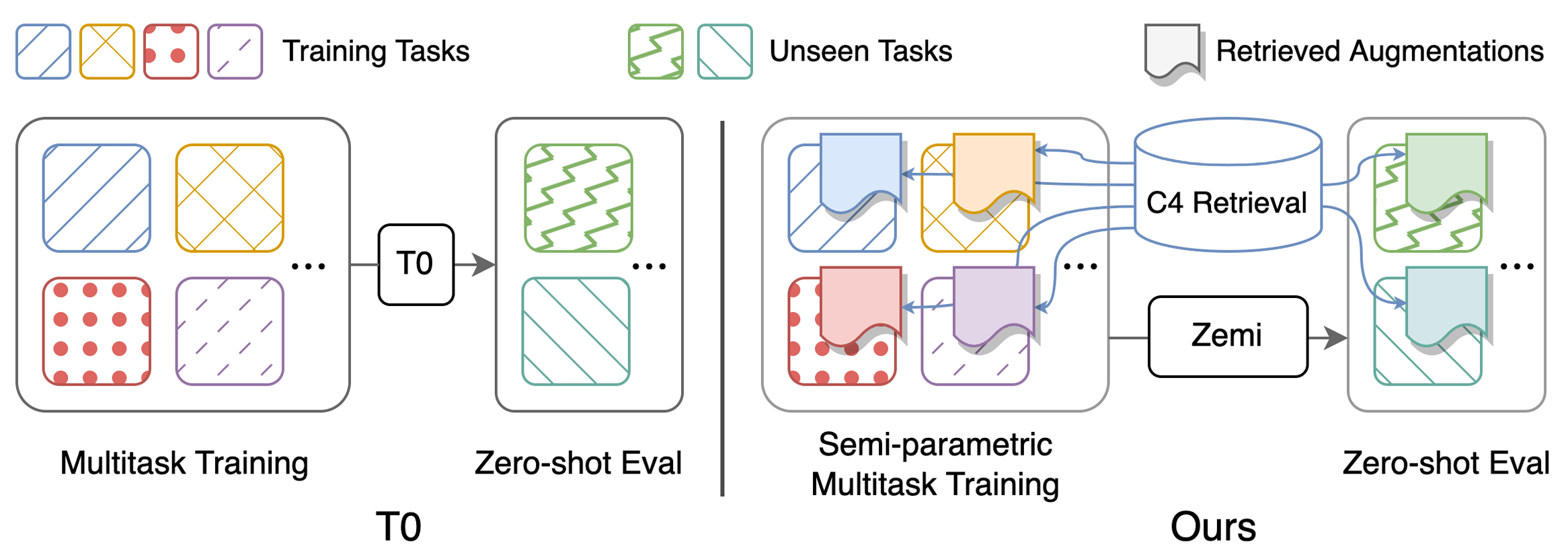
表1の主な結果を再現するためのスクリプト:パフォーマンス(セミ)パラメトリックマルチタスクは、トレーニングとゼロショット評価を促しました。構成に関する詳細な指示は、こちらをご覧ください。すべてのスクリプトはzemi/で実行する必要があります。 SETUP_ENV.sh 、env変数を設定するために次のスクリプトで呼び出されます。上記のセットアップとまったく同じフォルダー構造を使用しない場合、変数を変更できます。
bash ./training/no_aug_base.shbash ./training/no_aug_large.shbash ./training/concat_base.shbash ./training/concat_large.shbash ./training/fid_base.shbash ./training/fid_large.shbash ./training/zemi_base.shbash ./training/zemi_large.sh zemi/modeling_t5.pyこのラインとzemi/modeling_xattn.pyzemi/multi_task_fine_tune_baseline.pyzemi/multi_task_fine_tune_xattn.pyzemi/eval_original_task_only.pyzemi/eval_original_task_only_xattn.py visualization/各タスクの取得ドキュメントの例を含む。 visualization/top50_highest_score_retrieval_instancesとvisualization/top50_lowest_score_retrieval_instancesの最高および最低のBM25スコアを持つ上位50の例を含めます。また、 visualization/first50_retrieval_instancesで並べ替えることなく、各データセットの最初の50インスタンスも含めます。
@article{wang2022zemi,
title={Zemi: Learning Zero-Shot Semi-Parametric Language Models from Multiple Tasks},
author={Wang, Zhenhailong and Pan, Xiaoman and Yu, Dian and Yu, Dong and Chen, Jianshu and Ji, Heng},
journal={arXiv preprint arXiv:2210.00185},
year={2022}
}


