Zemi
1.0.0
يمكن العثور على التعليمات حول تنزيل مجموعات البيانات المعالجة مسبقًا ومجموعات بيانات الأزياء المسبقة هنا
قم بتنزيل checkpoints من: ضع أدلة نقاط التفتيش في checkpoints تحت zemi/output/p3_finetuning
قم بإعداد بيئة كوندا مع conda env create -f environment.yml . تشغيل accelerate config لتكوين الجهاز.
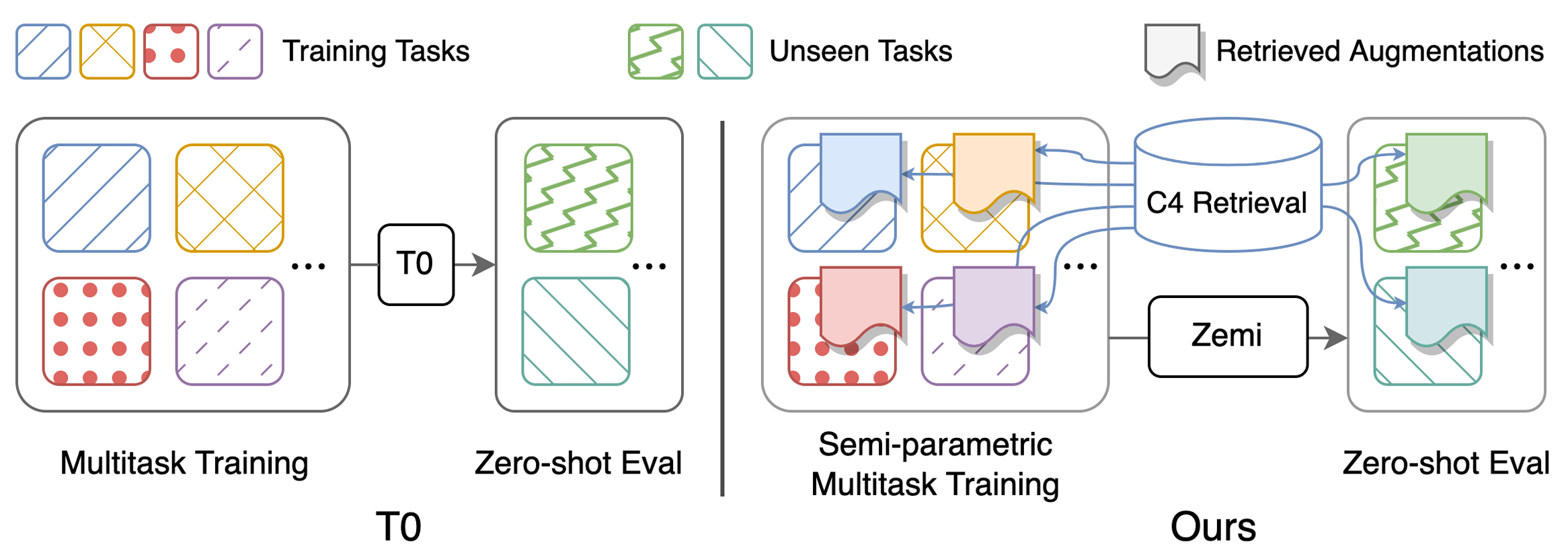
البرامج النصية لإعادة إنتاج النتائج الرئيسية في الجدول 1: أداء المهام المتعددة البارامترية (SAMI-) دفع التدريب وتقييم الصفر. يمكن العثور على تعليمات مفصلة حول التكوينات هنا. يجب تشغيل جميع البرامج النصية تحت zemi/ . سيتم استدعاء SETUP_ENV.sh في البرامج النصية التالية لإعداد متغيرات ENV. يمكن للمرء تعديل المتغيرات إن لم يكن باستخدام هيكل المجلد نفسه بالضبط كما هو الإعداد أعلاه.
bash ./training/no_aug_base.shbash ./training/no_aug_large.shbash ./training/concat_base.shbash ./training/concat_large.shbash ./training/fid_base.shbash ./training/fid_large.shbash ./training/zemi_base.shbash ./training/zemi_large.sh zemi/modeling_t5.py من هذا السطر و zemi/modeling_xattn.pyzemi/multi_task_fine_tune_baseline.pyzemi/multi_task_fine_tune_xattn.pyzemi/eval_original_task_only.pyzemi/eval_original_task_only_xattn.py visualization/ يحتوي على أمثلة على المستندات المستردة لكل مهمة. نقوم بتضمين أفضل 50 أمثلة مع أعلى وأدنى درجات BM25 في visualization/top50_highest_score_retrieval_instances و visualization/top50_lowest_score_retrieval_instances . نقوم أيضًا بتضمين أول 50 حالة لكل مجموعة بيانات دون إعادة ترتيب visualization/first50_retrieval_instances .
@article{wang2022zemi,
title={Zemi: Learning Zero-Shot Semi-Parametric Language Models from Multiple Tasks},
author={Wang, Zhenhailong and Pan, Xiaoman and Yu, Dian and Yu, Dong and Chen, Jianshu and Ji, Heng},
journal={arXiv preprint arXiv:2210.00185},
year={2022}
}


