Цель этого проекта - создать качественные переводы ML Hokkien.
Этот проект содержит инструменты, которые помогают перевести и оценить английский, Хоккиен (сценарий POJ), Хоккиен (сценарий Тай-Ло) и Хоккиен (漢字 Script).
Этот проект фокусируется на переводах текста в текст.
(Хоккиен также известен как Миннан, Тайваньский, Хокла, Южный Мин и ISO 639-3: НАН.)
Демо
Попробуйте онлайн -демонстрацию последней модели перевода Хоккиена
Обновления
2023-11-07
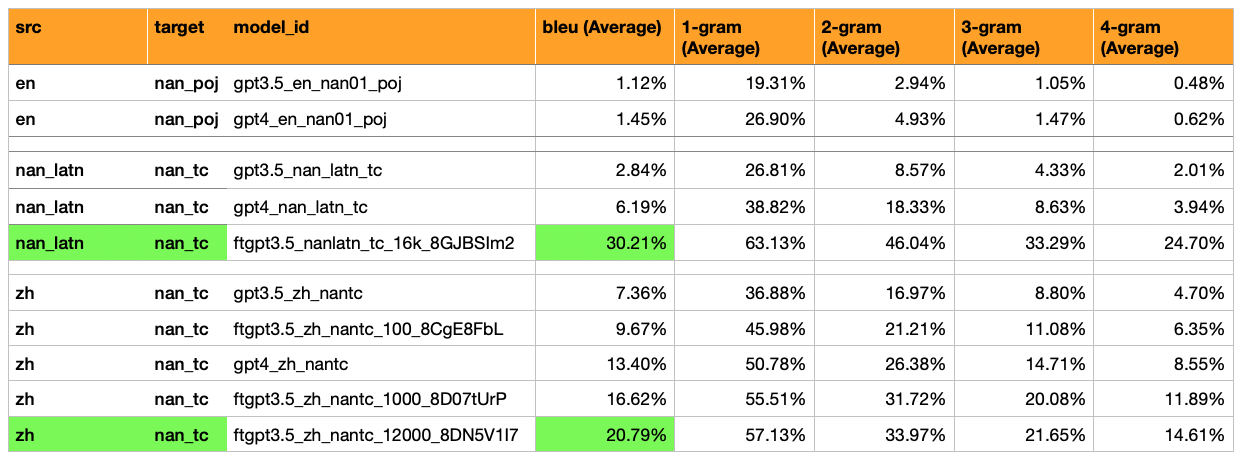
Добавлены модели, переводы и оценки Хоккиена (латинский скрипт ) -> Хоккиен (漢字 Скрипт) *
Hokkien (латинский скрипт) = смесь ручных и автоматизированных переводов/трансляции. Автоматизированные представляют собой смесь южных + северных диалектов Хоккиена, а также смесь сценариев Тай-Ло и POJ.
Результаты: тонкий настроенный GPT3,5 достиг 30% Bleu (в 5 раз больше, чем GPT4-Shot, который получил 6%).
Результаты: эта модель была бы полезна для обработки Hokkien Wikipedia, поскольку она является крупнейшим источником легкодоступных текстов Hokkien.
2023-10-31
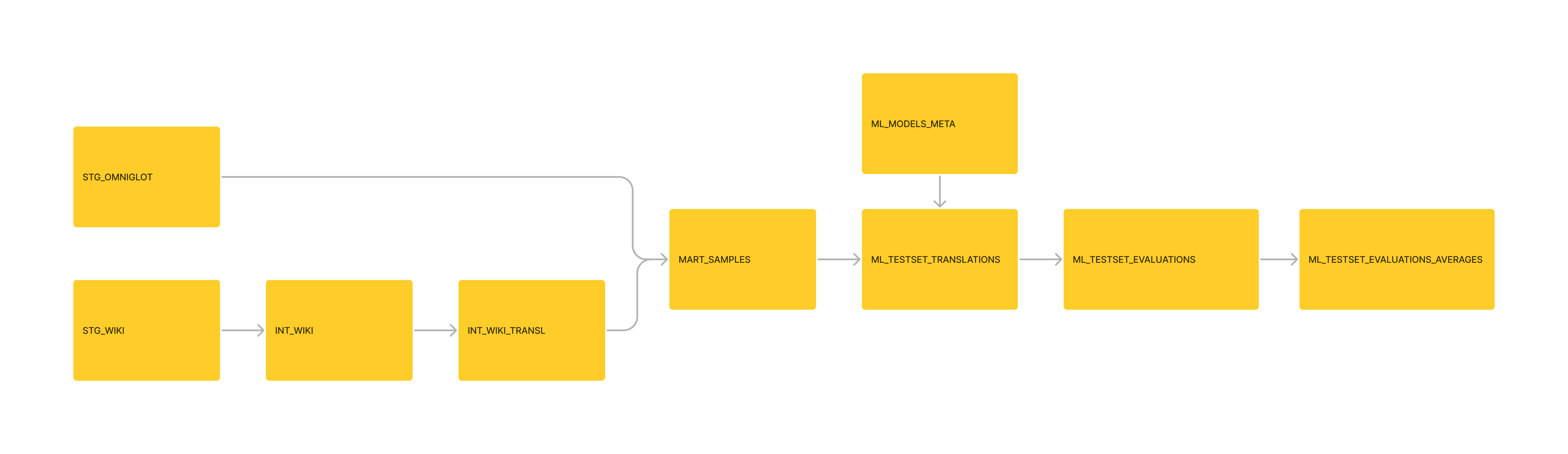
Управление данными; Переносили основные преобразования MOEDICT в трубопровод DBT. Докладывали данные MOEDICT и для MART_SAMEMER USECASES.
2023-10-26
Добавлены переводы и оценки: GPT -3.5 тонко настроенные на 12 000 примеров (почти все образцы MOEDICT), для мандарина -> Хоккиен (漢字 Script).
Результат: бал Bleu 21
Выводы:
Manetuned Model GPT3.5 определенно работает лучше, чем модель с нулевым выстрелом GPT4, когда есть 1000+ PAIRSE.
Созданная модель GPT3,5 с ~ 10000 парами предложений выполняет ~ ↑ 55% лучше, чем gpt4, и ~ ↑ 282% лучше, чем gpt3,5.
2023-10-24
Добавлен набор данных MOEDICT. Это вместе с колонкой «английский» (перевод с мандарина через GPT4).
Рассчитанные оценки BLEU с новыми данными.
️ Обнаруженные предыдущие расчеты баллов были отключены. Обновление с исправленными результатами Bleu!
(Структуры данных: рефактован, поэтому с ними легче иметь дело.)
Выводы:
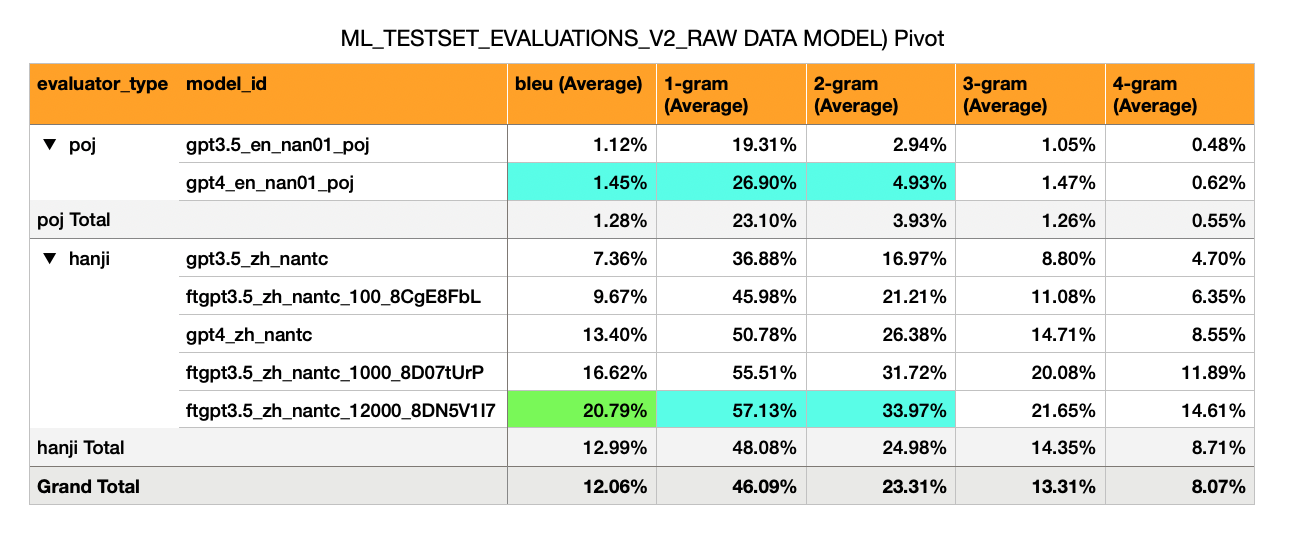
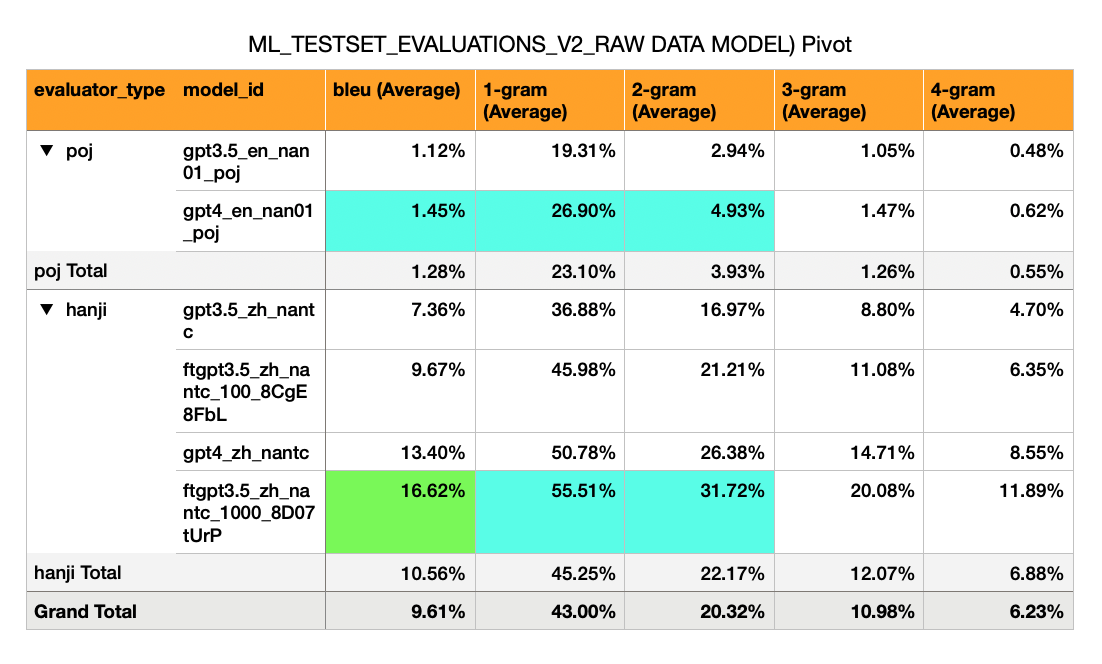
Английский -> Хоккиен (сценарий POJ) - Начальные модели Naive имеют очень низкие оценки BLEU (1%)
Mandarin -> Hokkien (漢字 Script) - имеет гораздо более высокий Bleu (от 7% до 17%). Это примерно половина того, что можно было бы ожидать от сносного балла Bleu (30%).
GPT-3,5 Zero Shot: Bleu 7%
GPT-3,5 тонко настроенные на 100 примеров: 10%
GPT-4 Zero Shot: Bleu 13%
GPT-3,5 тонко настроились на 1000 примеров: 16%
(Да, тонкая модель GPT3.5 Surpases GPT-4 Zero Shot)
Гипотезы:
Для ZH-> NAN (TC): Учитывая изменение величины с точкой между финалением (0-> 100-> 1000 примеров = 7%-> 10%-> 16%Bleu), предвидится, что если большая часть набора набора данных MEEDICT используется (~ 13 201 пары предложений), то есть шанс, что оценка BLEU может достичь прохожного уровня (30%).
2023-10-19
Управление: Продолжение замены больше моделей данных, на модели DBT.
2023-10-12
Управление: отформатировал нисходящую таблицу 'ML_TESTSET_EVALUATIONS_AVERAVER' 'в качестве модели DBT, как часть трубопровода.
2023-10-11
Управление: переформатировал данные как SQLITE3 и инициализировал из них проект DBT.
2023-10-10
Справочные тексты
Собрал некоторый справочный текст из Википедии (лицензия GFDL) и Omniglot (некоммерческая лицензия)
Очищенные эталонные тексты
Сгенерировал некоторые эталонные переводы английского языка от Миннана Википедии (POJ). Сгенерировано путем взятия «среднего текста» из переводов GPT4. Это не обязательно точно, но служит основой.
Тексты кандидатов
Сгенерировал некоторые переводы en → NAN (через GPT4 и GPT3.5)
Оценки
Сгенерировал несколько оценок на основе Bleu
Выводы и следующие шаги
Результаты: оценки BLEU для этих оценок довольно плохие, причем только баллы Unigram показывают какие-либо ненулевые результаты. Вещи, чтобы попытаться улучшить это:
Более мягкий токенизатор POJ, который токенизирует слогом, а не словом. Это потому, что серия слов не всегда согласованна.
Более снисходительный токенизатор POJ, который игнорирует диакритику. Это связано с тем, что нынешние источники POJ могут быть непоследовательными.
Используя Hanzi в качестве базового сценария перед любыми преобразованием POJ, для ранних моделей перевода.
Использование мандаринского китайца в качестве посредника.
Рассмотрим использование Tâi-Lô (в качестве конвертера Hanzi → Tâi-Lô в настоящее время, но не Hanzi → Poj One). И как tâi-lô влияет на некоторые исходные данные.
Обратитесь к романизированным словам, как «Ханзи», как «hàn-jī / hàn-lī» в любых подсказках LLM. Использование сценариев Хоккиена может слегка сметить LLM в сторону более точного словаря Хоккиена, грамматики и написания сценариев.
Трубопровод: все они были созданы в электронных таблицах. В будущем они должны быть лучше автоматизированы как часть конвейера данных.