El objetivo de este proyecto es crear traducciones de calidad ML Hokkien.
Este proyecto contiene herramientas para ayudar a traducir y evaluar inglés, Hokkien (guión POJ), Hokkien (script de Tai-Lo) y Hokkien (漢字 漢字 script).
Este proyecto se centra en las traducciones de texto a texto.
(Hokkien también es conocido como Minnan, Taiwanese, Hoklo, Southern Min e ISO 639-3: Nan.)
Manifestación
Pruebe la demostración en línea del último modelo de traducción de Hokkien
Actualizaciones
2023-11-07
Modelos agregados, traducciones y evaluaciones de Hokkien (script latino ) -> hokkien (漢字 漢字 script) *
Hokkien (script latino) = una mezcla de traducciones/transliteraciones manuales y automatizadas. Los automatizados son una mezcla de dialectos del sur de Southern + Northern Hokkien, y también una mezcla de guiones Tai-LO y POJ.
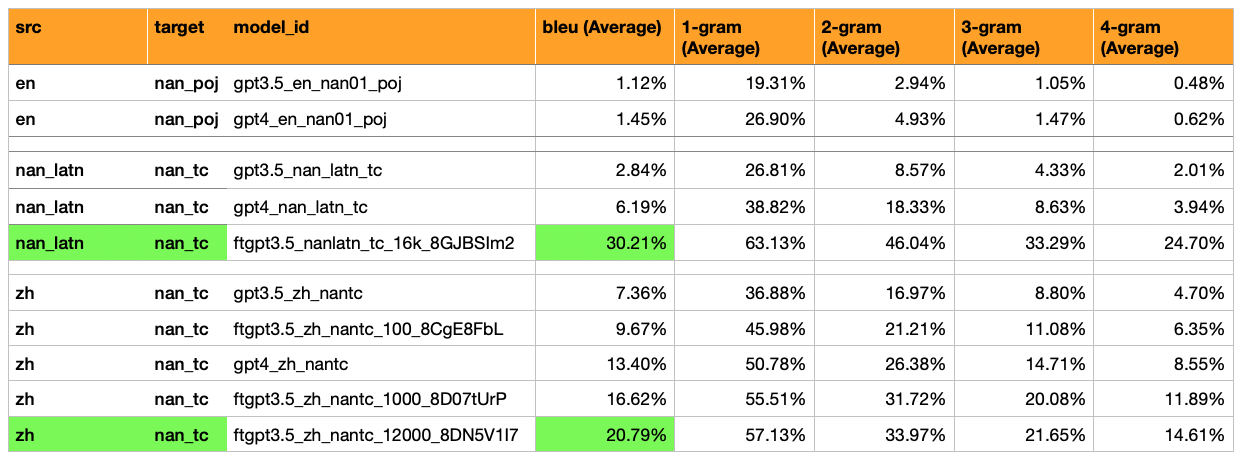
Resultados: GPT3.5 fino logró un 30% de bleu (5x más que GPT4-Zero-shot que obtuvo 6%).
Resultados: este modelo sería útil para procesar Hokkien Wikipedia, ya que es la fuente más grande de textos de Hokkien de fácil acceso.
2023-10-31
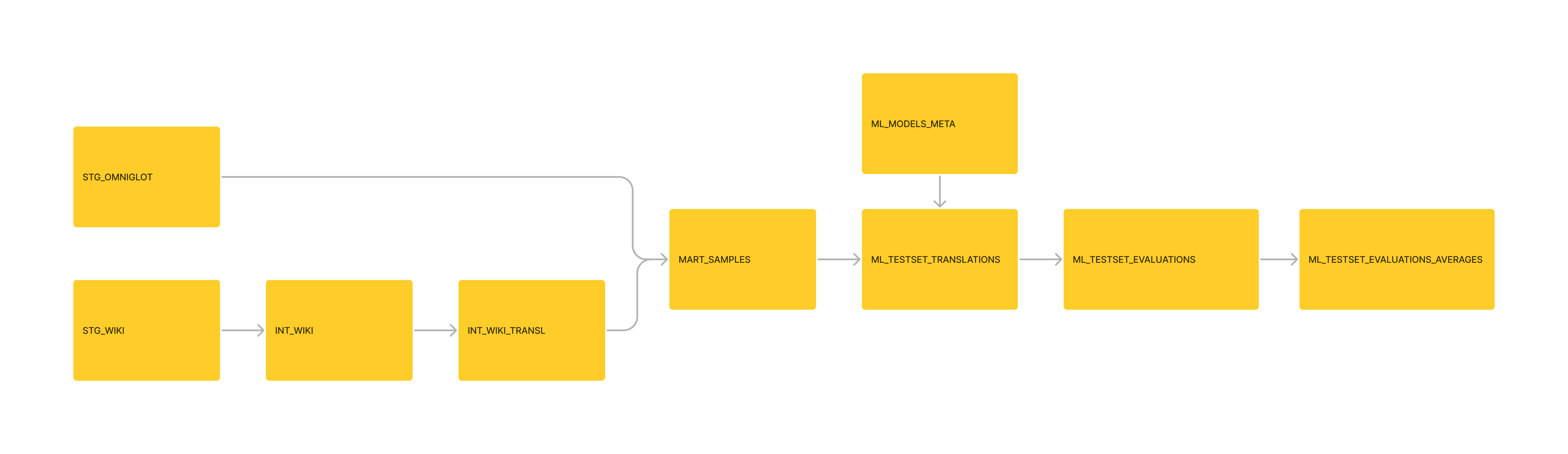
Gestión de datos; Movió las transformaciones básicas de Moedict a la tubería DBT. Los datos de Moedict agregados para Mart_Sample Usecases también.
2023-10-26
Traducciones y evaluaciones agregadas de: GPT -3.5 fina en 12,000 ejemplos (casi todas las muestras de Moedict), para mandarina -> hokkien (漢字 script).
Resultado: puntaje de Bleu de 21
Conclusiones:
Un modelo GPT3.5 FINETADO definitivamente funciona mejor que un modelo GPT4 de disparo cero cuando hay más de 1000 pares de oraciones.
Un modelo GPT3.5 Finetened con ~ 10,000 pares de oraciones funciona ~ ↑ 55% mejor que GPT4 cero-shot, y ~ ↑ 282% mejor que GPT3.5-shot cero.
2023-10-24
Se agregó el conjunto de datos de Moedict. Junto con una columna de "inglés" (traducida de mandarina a través de GPT4).
Puntajes BLU calculados con nuevos datos.
️ Descubridos los cálculos de puntuación de BLU anteriores estaban apagados. ¡Actualización con puntajes BLEU corregidos!
(Estructuras de datos: refactorizados para que sean más fáciles de tratar).
Recomendaciones:
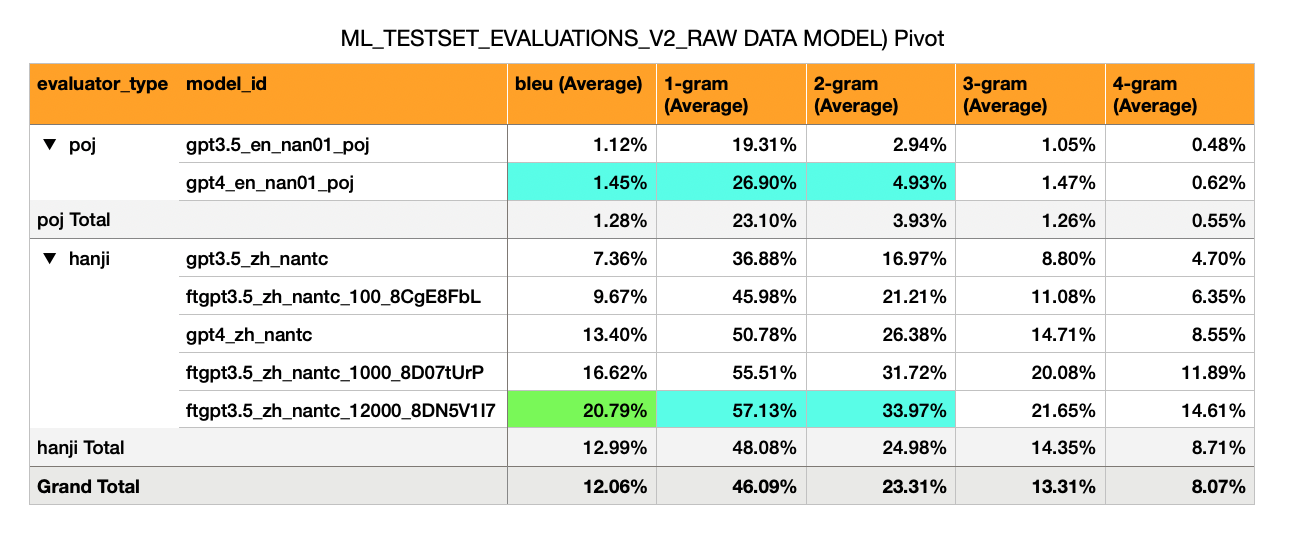
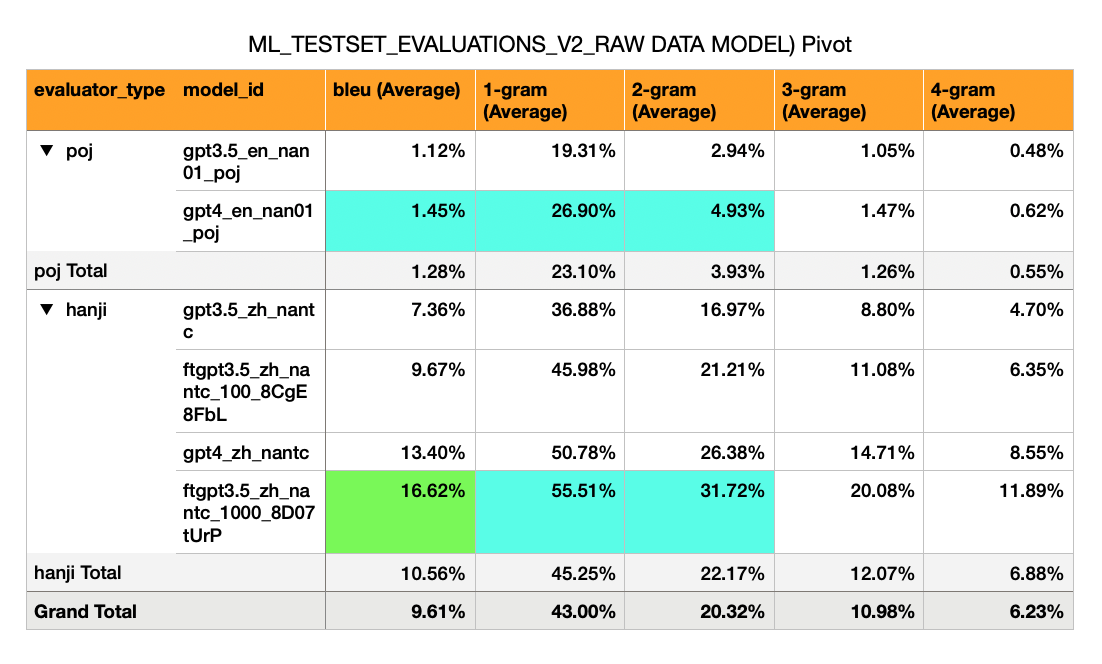
Inglés -> Hokkien (Script POJ) - Los modelos de cáculos iniciales tienen puntajes de BLU muy bajos (1%)
Mandarin -> Hokkien (漢字 漢字 漢字 script) - tiene un bleu mucho más alto (7% a 17%). Esto es aproximadamente la mitad de lo que uno esperaría de una puntuación de BLU pasable (30%).
GPT-3.5 Cero Shot: Bleu 7%
GPT-3.5 fino en 100 ejemplos: 10%
GPT-4 Cero Shot: Bleu 13%
GPT-3.5 fino en 1,000 ejemplos: 16%
(Sí, un modelo GPT3.5 de fino Traspasas GPT-4 CERO SOT)
Hipótesis:
Para zh-> nan (tc): dado el cambio de magnitud con finetuning (0-> 100-> 1,000 ejemplos = 7%-> 10%-> 16%bleu), es previsible que se haya usado la mayoría del conjunto de datos Moedict (~ 13,201 pares de oraciones), entonces existe una posibilidad de que la puntuación Bleu pueda alcanzar un nivel factible (30%).
2023-10-19
Gestión: continuar reemplazando más modelos de datos, con modelos DBT.
2023-10-12
Gestión: formateó la tabla 'ml_testset_evaluations_average' aguas abajo como modelo DBT, como parte de la tubería.
2023-10-11
Gestión: Reformateó los datos como SQLITE3 e inicializó un proyecto DBT de él.
2023-10-10
Textos de referencia
Reunió algún texto de referencia de Wikipedia (licencia GFDL) y Omniglot (licencia no comercial)
Textos de referencia limpios
Generó algunas traducciones al inglés de referencia de Minnan Wikipedia (POJ). Generado tomando el "texto mediano" de las traducciones GPT4. Esto no es necesariamente preciso, pero sirve como base.
Textos candidatos
Generó algunas traducciones EN → NAN (a través de GPT4 y GPT3.5)
Evaluaciones
Generó varias evaluaciones basadas en Bleu
Conclusiones y los siguientes pasos
Resultados: Las puntuaciones de BLU para estas evaluaciones son bastante malas, con solo puntajes unigram que muestran resultados distintos de cero. Cosas para tratar de mejorar esto:
Un tokenizador POJ más indulgente que tokeniza por sílaba en lugar de palabra. Esto se debe a que la separación de palabras no siempre es consistente.
Un tokenizador POJ más indulgente que ignora los diacríticos. Esto se debe a que las fuentes actuales de POJ pueden ser inconsistentes.
Uso de Hanzi como un script base antes de cualquier conversión de POJ, para los primeros modelos de traducción.
Uso de chino mandarín como intermediario.
Considere el uso de Tâi-lô (como un convertidor Hanzi → Tâi-Lô actualmente existe, pero no un Hanzi → Poj). Y cómo Tâi-lô afecta algunos de los datos de origen.
Consulte las palabras romanizadas, como "Hanzi", como "Hàn-Jī / Hàn-Lī" a cualquier información LLM. El uso de guiones Hokkien puede sesgar ligeramente el LLM hacia el vocabulario de Hokkien más preciso, la gramática y la escritura de guiones.
Tubería: todos se generaron en hojas de cálculo. En el futuro, deberían estar mejor automatizados como parte de una tubería de datos.