Hokkien (البرنامج النصي اللاتيني) = مزيج من الترجمات/الترجمة اليدوية والآلية. تلك الآلية هي مزيج من لهجات Hokkien الجنوبية + الشمالية ، وكذلك مزيج من البرامج النصية Tai-Lo و POJ.
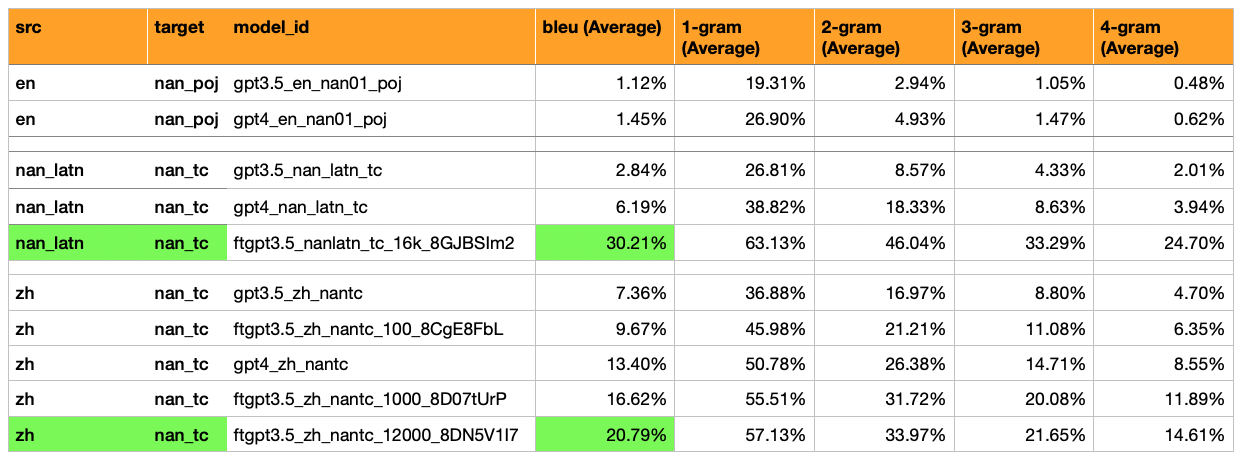
النتائج: حققت GPT3.5 المضبوطة بنسبة 30 ٪ (5x أكثر من GPT4-Zero-Shot التي حصلت على 6 ٪).
النتائج: سيكون هذا النموذج مفيدًا لمعالجة Hokkien Wikipedia ، لأنه أكبر مصدر لنصوص Hokkien التي يمكن الوصول إليها بسهولة.
2023-10-31
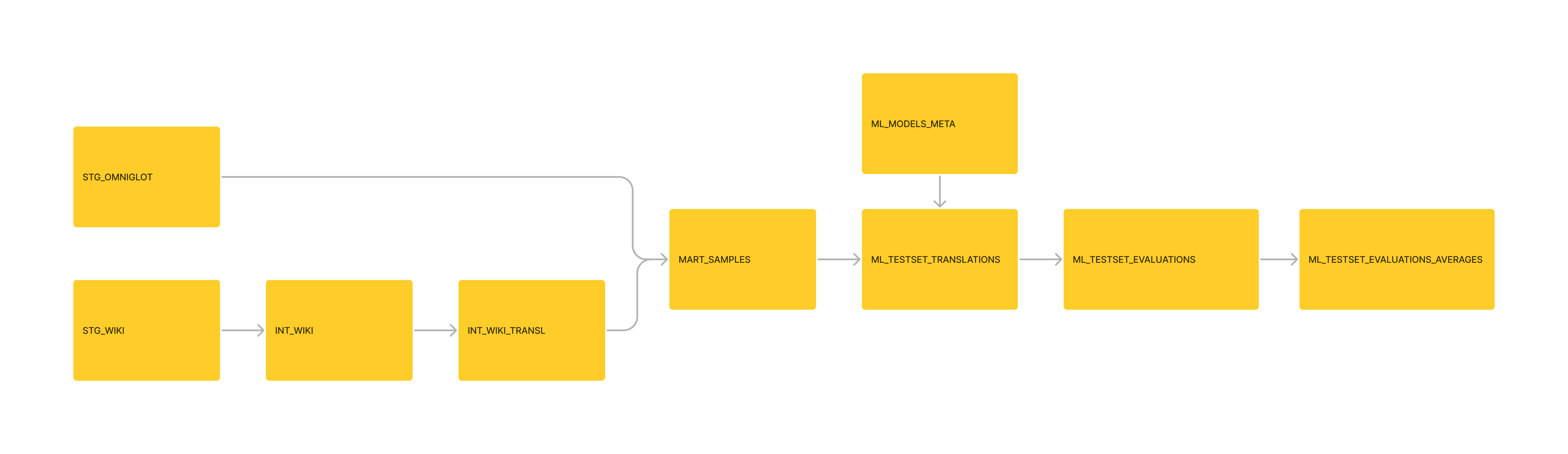
إدارة البيانات ؛ نقلت تحولات Moedict الأساسية إلى خط أنابيب DBT. إلحاق بيانات MoEdict لـ Mart_sample usecases أيضًا.
2023-10-26
الإضافة ترجمات وتقييمات: GPT -3.5 تم ضبطها على 12000 مثال (جميع عينات MoEdict تقريبًا) ، لـ Mandarin -> Hokkien (漢字 script).
النتيجة: درجة بلو 21
الاستنتاجات:
من المؤكد أن طراز GPT3.5 الذي تم تحريكه أفضل من نموذج GPT4 Zero-Shot عندما يكون هناك 1000+ جملة.
يعمل نموذج GPT3.5 الذي تم تحريكه مع حوالي 10،000 أزواج من الجملة ~ 55 ٪ أفضل من GPT4 Zero-Shot ، و ~ 282 ٪ أفضل من GPT3.5 Zero-Shot.
2023-10-24
تمت إضافة مجموعة بيانات MoEdict. جنبا إلى جنب مع عمود "إنجليزي" (ترجم من الماندرين عبر GPT4).
درجات bleu المحسوبة مع بيانات جديدة.
️ اكتشفت حسابات النتيجة السابقة بليو كانت متوقفة. تحديث مع نتائج بليو المصححة!
(هياكل البيانات: تم إعادة تماستها بحيث تكون أسهل في التعامل معها.)
النتائج:
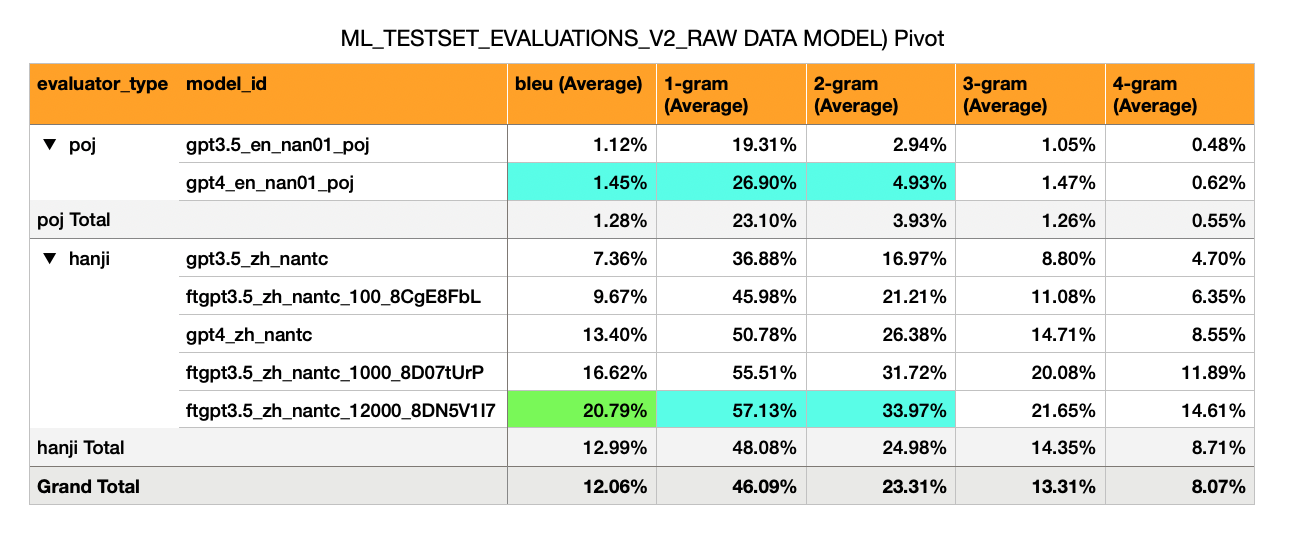
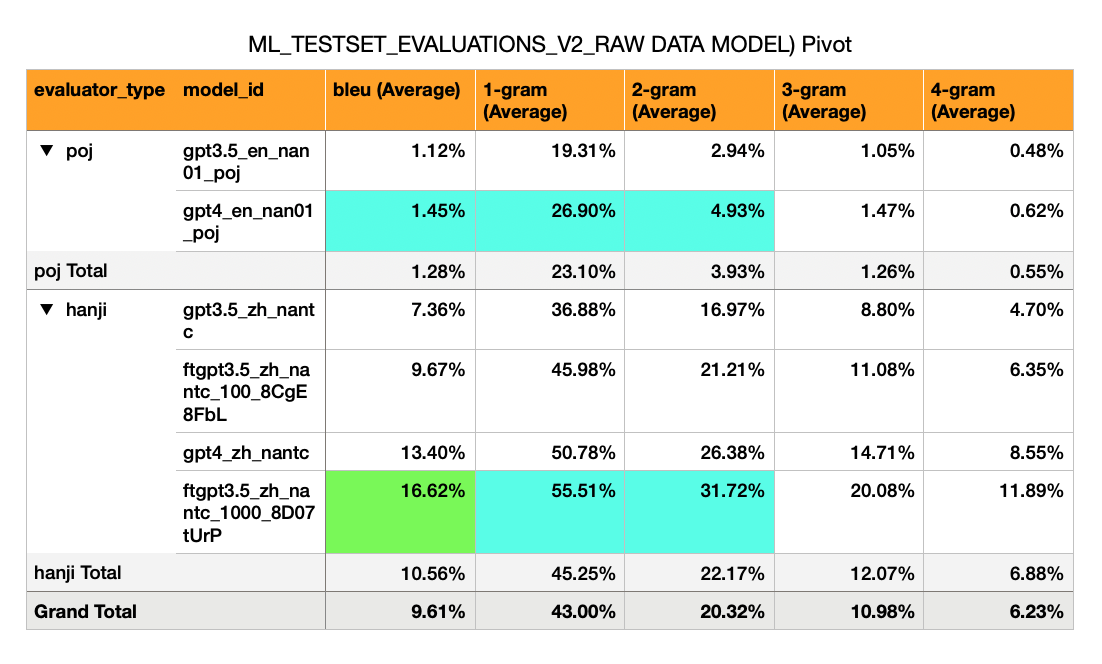
اللغة الإنجليزية -> Hokkien (POJ Script) - نماذج الساحات الأولية لها درجات منخفضة للغاية (1 ٪)
الماندرين -> Hokkien (script) - لديه Bleu أعلى بكثير (7 ٪ إلى 17 ٪). هذا هو حوالي نصف ما يتوقعه المرء من درجة بليو قابلة للمرور (30 ٪).
GPT-3.5 صفر لقطة: Bleu 7 ٪
GPT-3.5 تم ضبطه بشكل دقيق على 100 مثال: 10 ٪
GPT-4 Zero Shot: Bleu 13 ٪
GPT-3.5 تم ضبطه بشكل دقيق على 1000 مثال: 16 ٪
(نعم ، طراز GPT3.5 الذي تم ضبطه بشكل جيد GPT-4 صفر لقطة)
الفرضيات:
بالنسبة إلى ZH-> NAN (TC): بالنظر إلى التغير في الحجم مع التغذية المحلية (0-> 100-> 1000 أمثلة = 7 ٪-> 10 ٪-> 16 ٪ Bleu) ، فمن المتوقع أن يتم استخدام معظم مجموعة بيانات MoEdict (~ 13،201 زوجًا من الجملة) ، فهناك فرصة يمكن أن تصل درجة Bleu (30 ٪).
2023-10-19
الإدارة: الاستمرار في استبدال المزيد من نماذج البيانات ، بنماذج DBT.
2023-10-12
الإدارة: تم تنسيق جدول "ML_TESTSET_EVALUATIONS_AVERAGE" المصب كطراز DBT ، كجزء من خط الأنابيب.
2023-10-11
الإدارة: إعادة تنسيق البيانات كـ SQLite3 ، وتهيئة مشروع DBT منه.
2023-10-10
النصوص المرجعية
جمعت بعض النص المرجعي من Wikipedia (ترخيص GFDL) و Omniglot (ترخيص غير تجاري)
تنظيف النصوص المرجعية
ولدت بعض الترجمات الإنجليزية المرجعية من Minnan Wikipedia (POJ). تم إنشاؤه عن طريق أخذ "النص المتوسط" من ترجمات GPT4. هذا ليس دقيقًا بالضرورة ، ولكنه بمثابة أساس.
نصوص المرشح
ولدت بعض ترجمات EN → NAN (عبر GPT4 و GPT3.5)
التقييمات
ولدت العديد من التقييمات على أساس بليو
الاستنتاجات والخطوات التالية
النتائج: تعتبر درجات Bleu لهذه التقييمات سيئة للغاية ، حيث تُظهر درجات Unigram فقط أي نتائج غير صفرية. أشياء لمحاولة تحسين هذا:
رمز الرمز المميز الأكثر تساهلاً الذي يميزه مقطع لفظي بدلاً من كلمة. هذا لأن فصل الكلمات ليس متسقًا دائمًا.
Tokenizer POJ أكثر تساهلاً يتجاهل العلم. وذلك لأن مصادر POJ الحالية يمكن أن تكون غير متسقة.
باستخدام Hanzi كنص أساسي قبل أي تحويلات POJ ، لنماذج الترجمة المبكرة.
باستخدام الماندرين الصينية كوسيط.
النظر في استخدام Tâi-lô (كمحول Hanzi → Tâi-Lô موجود حاليًا ، ولكن ليس Hanzi → Poj One). وكيف يؤثر tâi-lô بعض بيانات المصدر.
ارجع إلى الكلمات الرومانية ، مثل "Hanzi" ، باسم "Hàn-Jī / Hàn-Lī" في أي مطالبات LLM. قد يؤدي استخدام البرامج النصية Hokkien إلى تحيز LLM قليلاً نحو مفردات Hokkien الأكثر دقة ، والقواعد ، وكتابة النصوص.
خط الأنابيب: تم إنشاؤها جميعها في جداول البيانات. في المستقبل ، يجب أن تكون أفضل تلقائيًا كجزء من خط أنابيب البيانات.