The goal of this project is to create quality ML Hokkien Translations.
This project contains tools to help translate and evaluate English, Hokkien (POJ script), Hokkien (Tai-Lo script), and Hokkien (漢字 script).
This project focuses on Text-to-Text translations.
(Hokkien is also known as Minnan, Taiwanese, Hoklo, Southern Min, and iso 639-3: NAN.)
Demo
Try out the Online Demo of the latest Hokkien Translation Model
Updates
2023-11-07
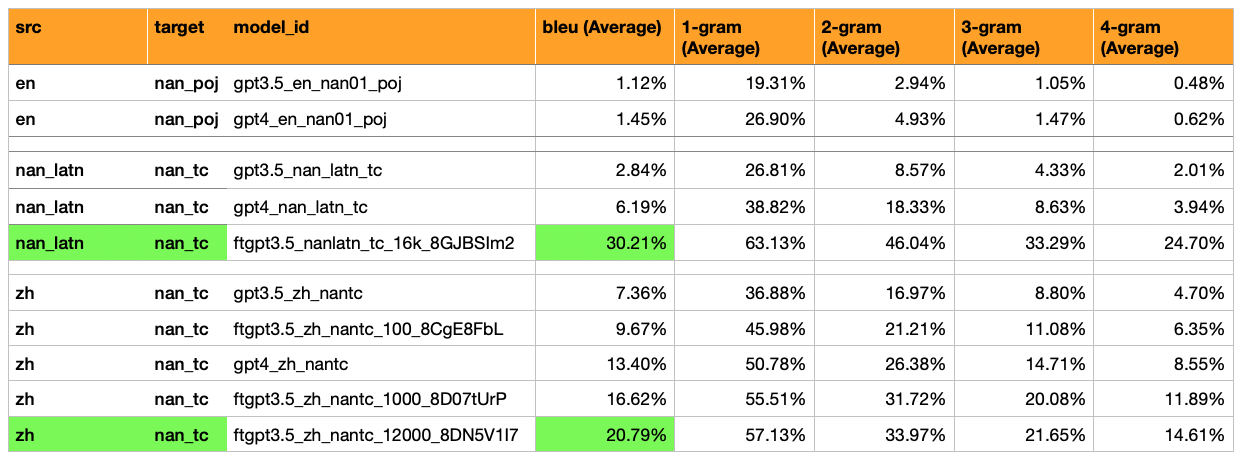
Added Models, Translations, and Evaluations of Hokkien (Latin script) -> Hokkien (漢字 script)*
Hokkien (Latin Script) = A mix of Manual and Automated Translations/Transliterations. Automated ones are a mix of Southern + Northern Hokkien Dialects, and also a mix of Tai-Lo and POJ scripts.
Results: Fine Tuned GPT3.5 achieved 30% BLEU (5x more than GPT4-Zero-Shot which got 6%).
Outcomes: This model would be useful for processing Hokkien Wikipedia, as it is the largest source of easily accessible Hokkien Texts.
2023-10-31
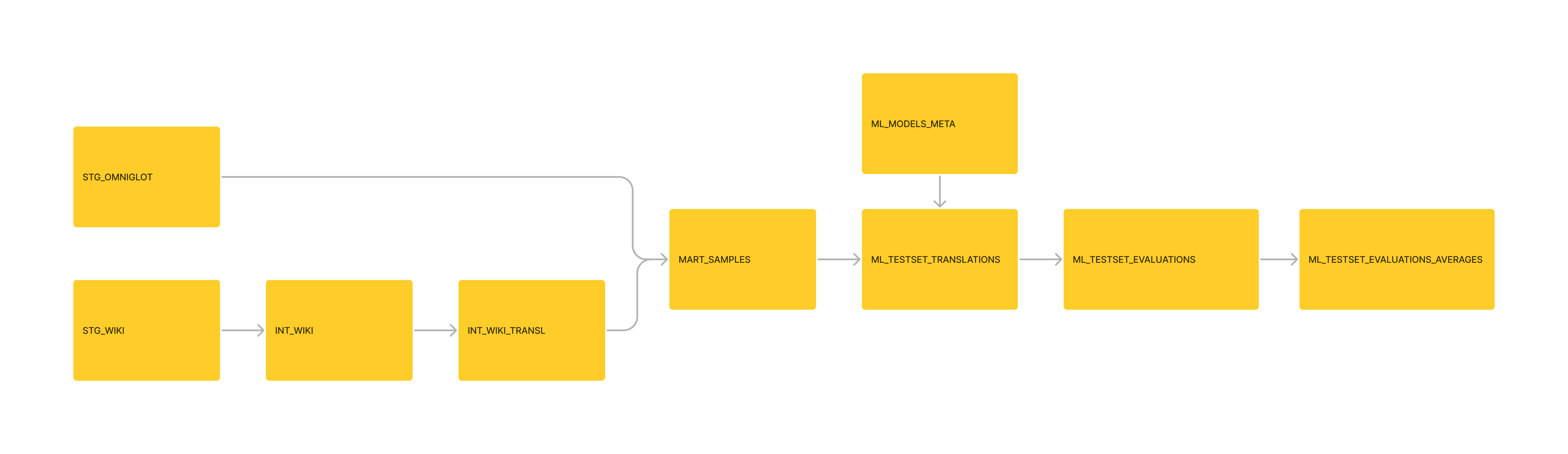
Data Management; Moved basic MoeDict transformations to dbt Pipeline. Appended MoeDict data for Mart_sample usecases as well.
2023-10-26
Added Translations and Evaluations of: GPT-3.5 Fine Tuned on 12,000 Examples (Almost all of MoeDict samples), for Mandarin -> Hokkien (漢字 script).
Result: BLEU score of 21
Conclusions:
A Finetuned GPT3.5 Model definitely performs better than a GPT4 Zero-Shot Model when there is 1000+ sentence-pairs.
A Finetuned GPT3.5 Model with ~10,000 sentence pairs performs ~ ↑ 55% better than GPT4 Zero-Shot, and ~ ↑ 282% better than GPT3.5 Zero-Shot.
2023-10-24
Added MoeDict Dataset. It along with an "English" column (translated from Mandarin via GPT4).
Calculated BLEU Scores with new data.
️ Discovered previous BLEU Score calculations were off. Update with Corrected BLEU Scores!
(Data Structures: Refactored so they're easier to deal with.)
Findings:
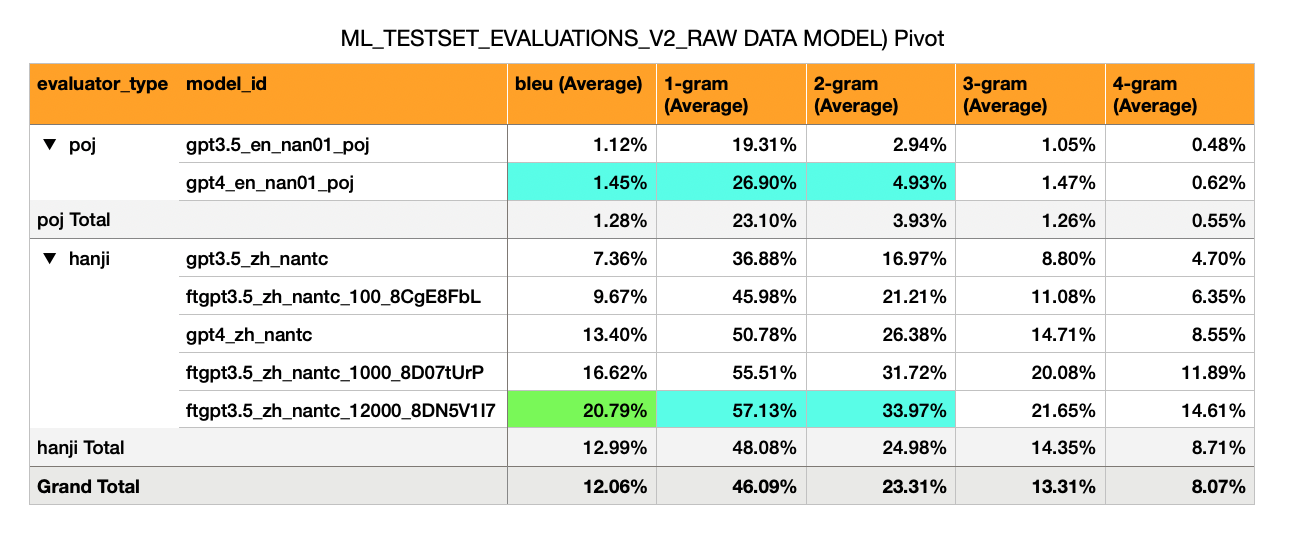
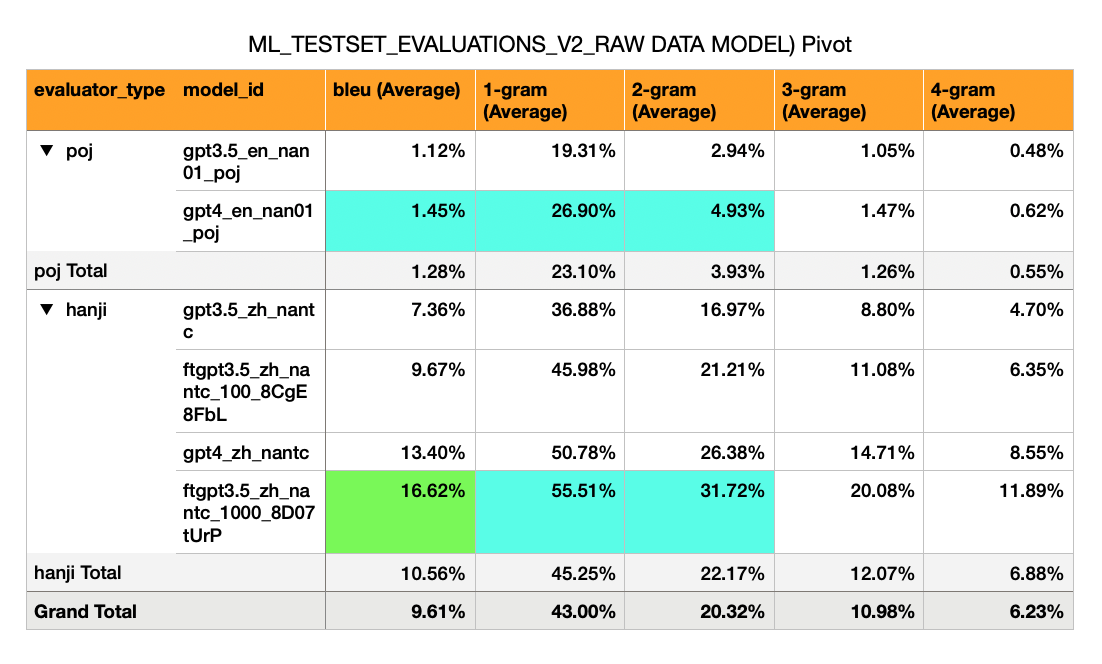
English -> Hokkien (POJ script) - Initial naieve models have very low BLEU scores (1%)
Mandarin -> Hokkien (漢字 script) - Has a much higher BLEU (7% to 17%). This is about half of what one would expect of a passable BLEU score (30%).
GPT-3.5 Zero Shot: BLEU 7%
GPT-3.5 Fine Tuned on 100 Examples: 10%
GPT-4 Zero Shot: BLEU 13%
GPT-3.5 Fine Tuned on 1,000 Examples: 16%
(Yup, a Fine-Tuned GPT3.5 Model surpases GPT-4 Zero Shot)
Hypotheses:
For ZH->NAN(TC): given the change in Magnitude with Finetuning (0->100->1,000 Examples = 7%->10%->16% BLEU), it is foreseeable that if most of the MOEDICT dataset is used (~13,201 sentence pairs), then there's a chance the BLEU score could reach a passable level (30%).
2023-10-19
Management: Continuing to replace more data models, with dbt models.
2023-10-12
Management: Formatted the downstream 'ML_TESTSET_EVALUATIONS_AVERAGE' table as a dbt Model, as part of the pipeline.
2023-10-11
Management: Reformatted the data as SQLITE3, and initialized a DBT Project from it.
2023-10-10
Reference Texts
Gathered some reference text from Wikipedia (GFDL license) and Omniglot (Non-Commercial license)
Cleaned up reference texts
Generated some reference English translations from Minnan Wikipedia (POJ). Generated by taking the "median text" from GPT4 translations. This is not necessarily accurate, but serves as a basis.
Candidate Texts
Generated some EN→NAN translations (via GPT4 and GPT3.5)
Evaluations
Generated several evaluations based on BLEU
Conclusions and Next Steps
Results: The BLEU scores for these evaluations are quite bad, with only unigram scores showing any non-zero results. Things to try to improve this:
A more lenient POJ Tokenizer that tokenizes by Syllable rather than Word. This is because word-separation isn't always consistent.
A more lenient POJ Tokenizer that ignores diacritics. This is because current POJ sources can be inconsistent.
Using Hanzi as a base script before any POJ conversions, for early translation models.
Using Mandarin Chinese as an intermediary.
Consider the use of Tâi-lô (as a Hanzi→Tâi-lô converter currently exists, but not a Hanzi→POJ one). And how Tâi-lô effects some of the source data.
Refer to romanized words, like "Hanzi", as "Hàn-jī / Hàn-lī" in any LLM prompts. Using Hokkien scripts may slightly bias the LLM towards more accurate Hokkien vocabulary, grammar, and script writing.
Pipeline: These were all generated in spreadsheets. In future, they should be better automated as part of a data pipeline.