Ziel dieses Projekts ist es, qualitativ hochwertige ML Hokkien -Übersetzungen zu erstellen.
Dieses Projekt enthält Tools zur Übersetzung und Bewertung von Englisch, Hokkien (POJ-Skript), Hokkien (Tai-Lo-Skript) und Hokkien (漢字 Skript).
Dieses Projekt konzentriert sich auf Text-zu-Text-Übersetzungen.
(Hokkien ist auch bekannt als Minnan, Taiwanese, Hooklo, Southern Min und ISO 639-3: Nan.)
Demo
Probieren Sie die Online -Demo des neuesten Hokkien -Übersetzungsmodells aus
Aktualisierungen
2023-11-07
Modelle, Übersetzungen und Bewertungen von Hokkien (lateinisches Skript ) -> Hokkien (漢字 Skript) * hinzugefügt
Hokkien (lateinisches Skript) = eine Mischung aus manuellen und automatisierten Übersetzungen/Transliterationen. Automatisierte sind eine Mischung aus Southern + Northern Hokkien-Dialekten sowie eine Mischung aus Tai-lo- und Poj-Skripten.
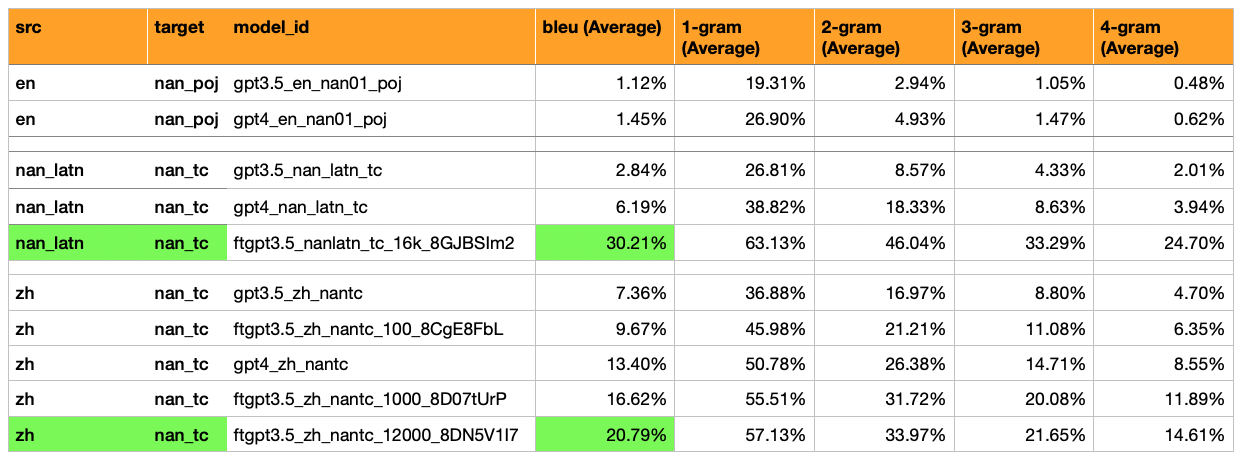
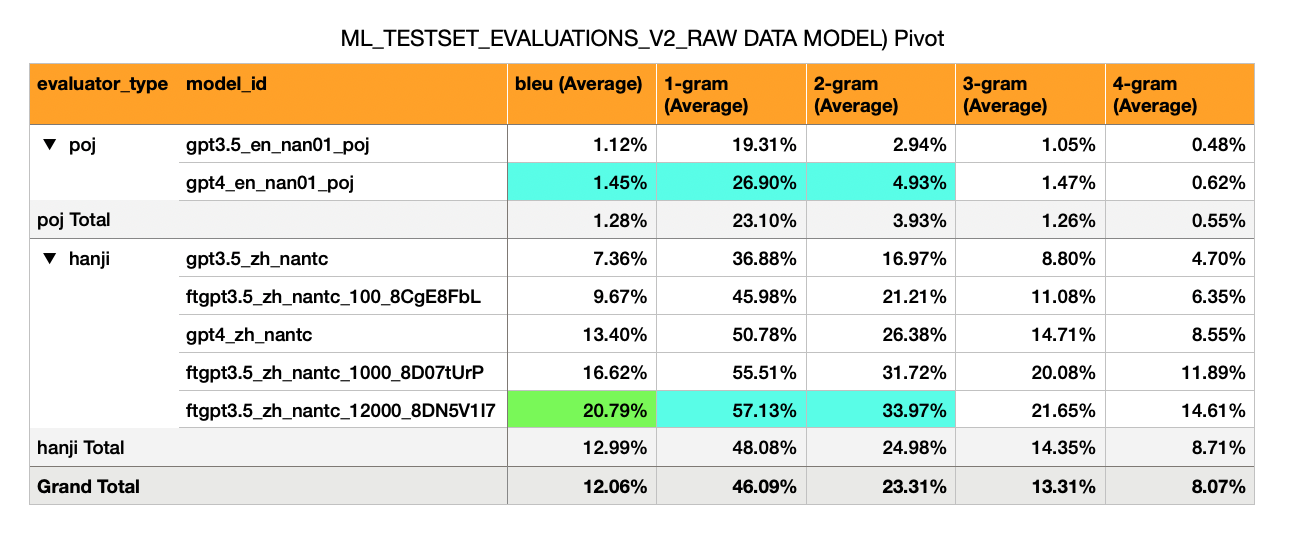
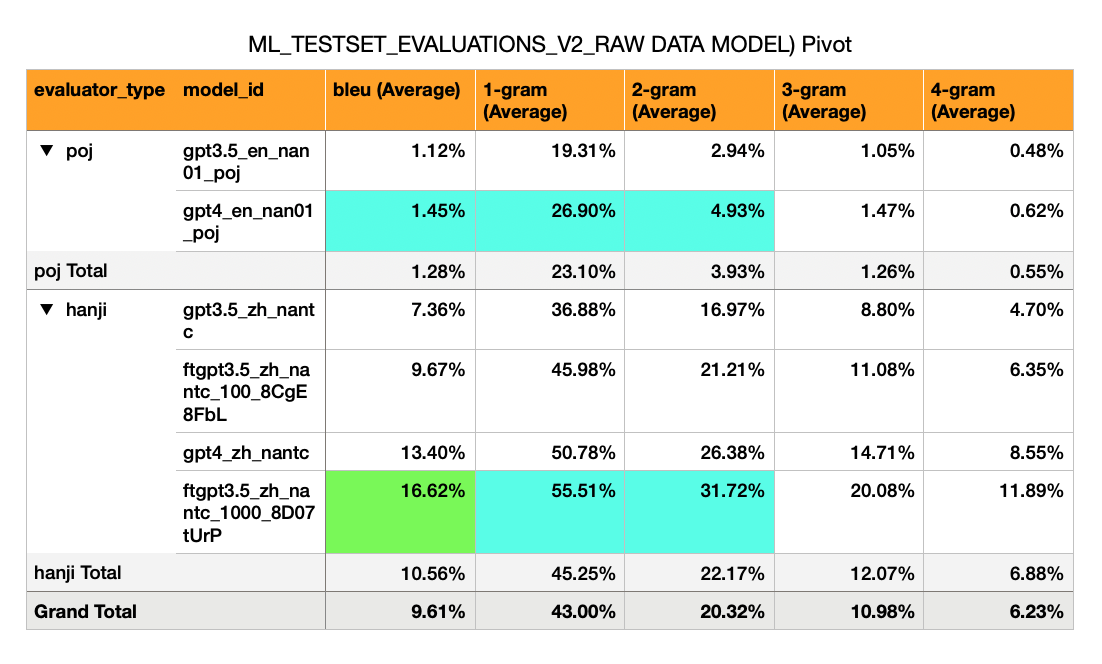
Ergebnisse: Fine-Tuned GPT3,5 erreichte 30% Bleu (5x mehr als GPT4-Null-Shot, der 6% erhielt).
Ergebnisse: Dieses Modell wäre nützlich für die Verarbeitung von Hokkien Wikipedia, da es die größte Quelle für leicht zugängliche Hokkien -Texte ist.
2023-10-31
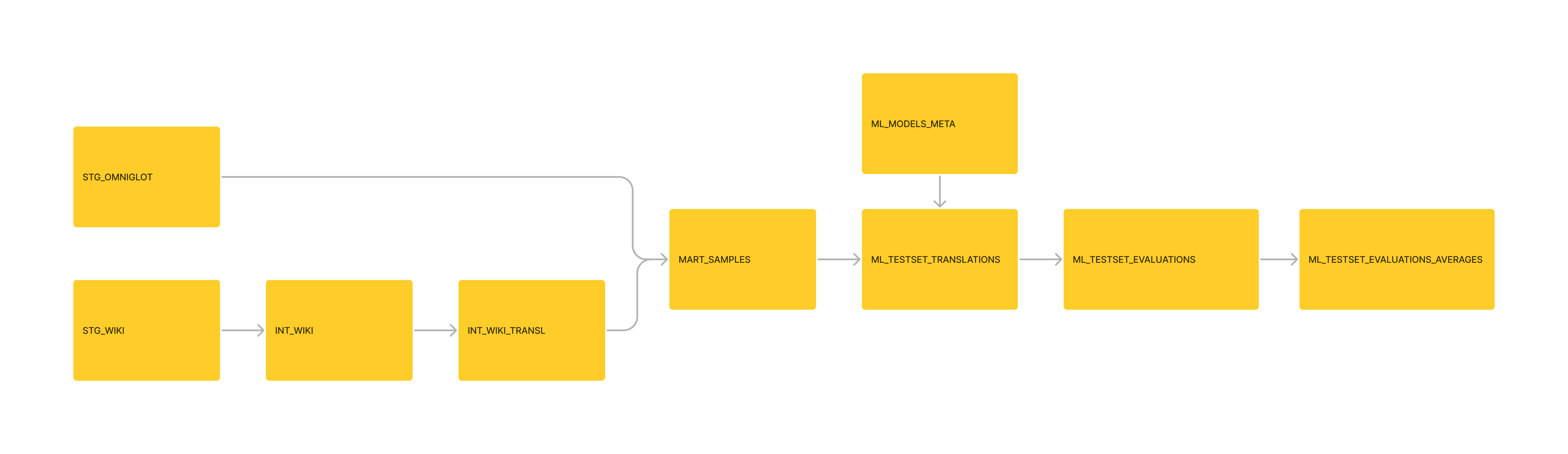
Datenverwaltung; Bewegte grundlegende Moedict -Transformationen in DBT -Pipeline. Angehängte Moedict -Daten auch für Mart_Sample -Usecasen.
2023-10-26
Übersetzungen und Bewertungen von: GPT -3,5 -fein auf 12.000 Beispiele (fast alle Moedict -Proben) für Mandarin -> Hokkien (漢字 Skript) hinzugefügt.
Ergebnis: Bleu -Score von 21
Schlussfolgerungen:
Ein flossenes GPT3.5-Modell leistet definitiv besser als ein GPT4-Null-Shot-Modell, wenn es mehr als 1000 Satzpaare gibt.
Ein flossenes GPT3,5-Modell mit ~ 10.000 Satzpaaren leistet ~ ↑ 55% besser als GPT4-Null-Shot und ~ ↑ 282% besser als 3,5 Null-Shot.
2023-10-24
MOEDICT -Datensatz hinzugefügt. Es zusammen mit einer "englischen" Spalte (übersetzt aus Mandarin über GPT4).
Berechnete BLEU -Ergebnisse mit neuen Daten.
Euen Entdeckte, dass frühere Bleu -Score -Berechnungen ausgeschaltet waren. Update mit korrigierten BLEU -Ergebnissen!
(Datenstrukturen: Umgerichtet, damit sie leichter umgehen können.)
Ergebnisse:
Englisch -> Hokkien (POJ -Skript) - Erste Navigationsmodelle haben sehr niedrige BLEU -Werte (1%)
Mandarin -> Hokkien (漢字 Skript) - hat eine viel höhere Bleu (7% bis 17%). Dies ist ungefähr die Hälfte dessen, was man von einem passablen Bleu -Score erwarten würde (30%).
GPT-3,5 Null Schuss: Bleu 7%
GPT-3,5-Fein abgestimmt auf 100 Beispiele: 10%
GPT-4 Zero Shot: Bleu 13%
GPT-3,5-Fein abgestimmt auf 1.000 Beispiele: 16%
(Yup, ein fein abgestimmter GPT3.5-Modell überschreitet GPT-4 Null-Schuss)
Hypothesen:
Für Zh-> Nan (TC): Angesichts der Größenänderung bei der Finetuning (0-> 100-> 1.000 Beispiele = 7%-> 10%-> 16%Bleu), ist es vorhersehbar, dass, wenn der größte Teil des Moedict-Datensatzes verwendet wird, wenn der größte Teil des Moedict-Datensatzes verwendet wird (~ 13.201.
2023-10-19
Management: Ersetzen Sie weiterhin weitere Datenmodelle durch DBT -Modelle.
2023-10-12
Management: formatierte die Tabelle 'ml_testset_evaluations_average' als DBT -Modell als Teil der Pipeline.
2023-10-11
Management: Die Daten als SQLite3 neu formatiert und ein DBT -Projekt daraus initialisiert.
2023-10-10
Referenztexte
Sammelte einen Referenztext von Wikipedia (GFDL-Lizenz) und Omniglot (nicht kommerzielle Lizenz)
Aufgereinigte Referenztexte
Erzeugte einige Referenz -englische Übersetzungen aus Minnan Wikipedia (POJ). Generiert durch den "Mediantext" von GPT4 -Übersetzungen. Dies ist nicht unbedingt genau, dient sondern als Grundlage.
Kandidatentexte
Erzeugte einige en → nan -Übersetzungen (über GPT4 und GPT3.5)
Bewertungen
Erzeugte mehrere Bewertungen auf der Grundlage von Bleu
Schlussfolgerungen und nächste Schritte
Ergebnisse: Die BLEU-Ergebnisse für diese Bewertungen sind ziemlich schlecht, wobei nur Unigram-Scores alle Ergebnisse ungleich Null zeigen. Dinge zu versuchen, dies zu verbessern:
Ein milderer Poj -Tokenizer, der eher nach Silbe als nach Wort token. Dies liegt daran, dass die Worttrennung nicht immer konsistent ist.
Ein milderer Poj -Tokenizer, der Diakritik ignoriert. Dies liegt daran, dass aktuelle POJ -Quellen inkonsistent sein können.
Verwenden von Hanzi als Basiskript vor allen POJ -Konvertierungen für frühe Übersetzungsmodelle.
Verwenden von Mandarin -Chinesisch als Vermittler.
Betrachten Sie die Verwendung von Tâi-Lô (als Hanzi → Tâi-lô-Wandler existiert derzeit, jedoch nicht als Hanzi → Poj). Und wie Tâi-Lô einige der Quelldaten bewirkt.
Beziehen Sie sich in jedem LLM auf romanisierte Wörter wie "Hanzi" als "Hàn-jī / hàn-lī". Die Verwendung von Hokkien -Skripten kann den LLM leicht in das genauere Hokkien -Vokabular, die Grammatik und das Schreiben von Skript verzerrt.
Pipeline: Diese wurden alle in Tabellenkalkulationen generiert. In Zukunft sollten sie im Rahmen einer Datenpipeline besser automatisiert werden.