이 프로젝트에는 영어, Hokkien (Poj Script), Hokkien (Tai-Lo Script) 및 Hokkien (漢字 스크립트)을 번역 및 평가하는 데 도움이되는 도구가 포함되어 있습니다.
이 프로젝트는 텍스트-텍스트 번역에 중점을 둡니다.
(Hokkien은 Minnan, Taiwanese, Hoklo, Southern Min 및 ISO 639-3 : Nan으로도 알려져 있습니다.)
데모
최신 Hokkien 번역 모델의 온라인 데모를 시도해보십시오.
업데이트
2023-11-07
Hokkien (라틴 스크립트 ) 의 모델, 번역 및 평가 추가
Hokkien (라틴 스크립트) = 매뉴얼 및 자동 번역/음역의 혼합. 자동화 된 것들은 남부 + 북부 hokkien 방언의 혼합이며, Tai-lo 및 Poj 스크립트가 혼합되어 있습니다.
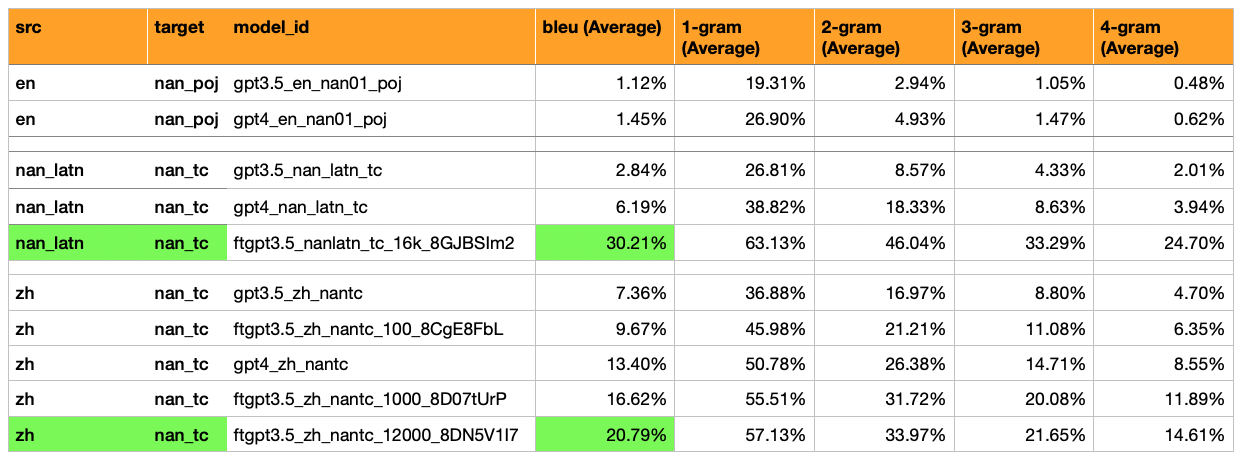
결과 : 미세 조정 GPT3.5는 30% BLEU를 달성했습니다 (6%를 얻은 GPT4- 제로 샷보다 5 배 더 많음).
결과 :이 모델은 Hokkien Wikipedia를 처리하는 데 유용합니다.
2023-10-31
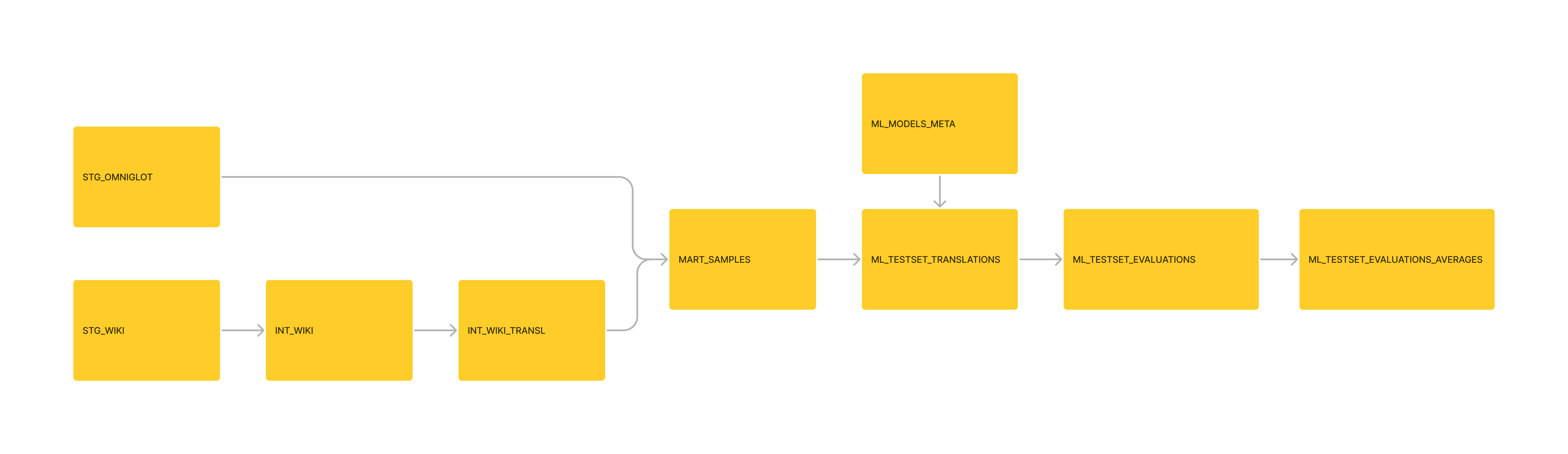
데이터 관리; 기본 MoEdict 변환을 DBT 파이프 라인으로 옮겼습니다. MART_SALLE USECASES에 대한 MOEDICT 데이터도 추가되었습니다.
2023-10-26
Mandarin-> Hokkien (漢字 스크립트)에 대한 12,000 개의 예 (거의 모든 Moedict 샘플)에 대해 GPT -3.5 미세 조정 된 번역 및 평가 추가.
결과 : Bleu 점수 21
결론 :
Finetuned GPT3.5 모델은 1000 개 이상의 문장 쌍이있을 때 GPT4 제로 샷 모델보다 확실히 더 잘 수행됩니다.
~ 10,000 문장 쌍을 가진 Finetuned GPT3.5 모델은 ~ ↑ 55% GPT4 Zero-Shot보다 ~ ↑ ↑ ↑ 282%가 gpt3.5 Zero-Shot보다 우수합니다.
2023-10-24
Moedict 데이터 세트가 추가되었습니다. "영어"열 (GPT4를 통해 만다린에서 번역)과 함께.
새로운 데이터로 BLEU 점수를 계산합니다.
켈 이전 BLEU 점수 계산이 꺼진 것으로 밝혀졌습니다. 수정 된 BLEU 점수로 업데이트하십시오!
(데이터 구조 : 다루기가 더 쉬워서 리팩토링됩니다.)
결과 :
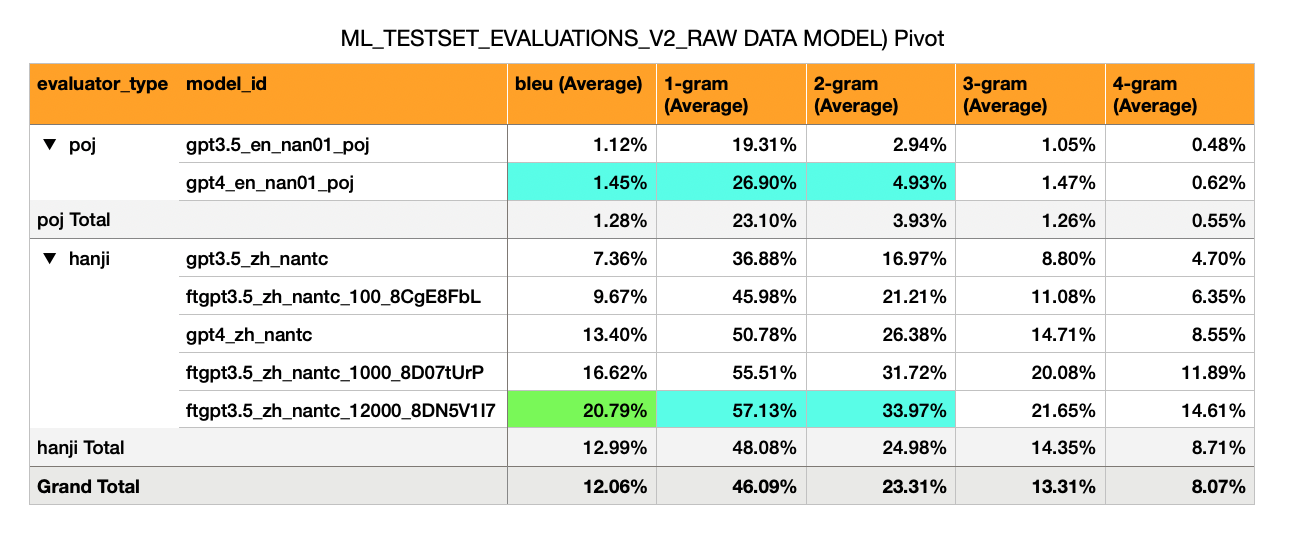
영어 -> hokkien (poj script) - 초기 Naieve 모델은 Bleu 점수가 매우 낮습니다 (1%)
Mandarin-> Hokkien (漢字 스크립트) - Bleu가 훨씬 높습니다 (7% ~ 17%). 이것은 통과 가능한 BLEU 점수 (30%)의 절반 정도입니다.
gpt-3.5 Zero Shot : Bleu 7%
GPT-3.5 100 예에서 미세 조정 : 10%
gpt-4 Zero Shot : Bleu 13%
GPT-3.5 1,000 예에서 미세 조정 : 16%
(예, 미세 조정 된 GPT3.5 모델 Surpases GPT-4 Zero Shot)
가설 :
ZH-> NAN (TC)의 경우 : Finetuning (0-> 100-> 1,000 예 = 7%-> 10%-> 16%BLEU)의 크기의 변화를 감안할 때, 대부분의 Moedict 데이터 세트가 사용되면 (~ 13,201 문장 쌍) BLEU 점수가 통과 가능한 레벨에 도달 할 수있는 기회가 있다는 것이 예측 가능합니다.
2023-10-19
관리 : 더 많은 데이터 모델을 DBT 모델로 계속 대체합니다.
2023-10-12
관리 : 파이프 라인의 일부로 DBT 모델로 다운 스트림 'ML_TESTSET_EVALUATIONS_AVERAGE'테이블을 포맷했습니다.
2023-10-11
관리 : 데이터를 SQLITE3로 재구성하고 DBT 프로젝트를 초기화했습니다.
2023-10-10
참조 텍스트
Wikipedia (GFDL 라이센스) 및 Omniglot (비상업적 라이센스)에서 일부 참조 텍스트를 수집했습니다.
참조 텍스트를 정리했습니다
Minnan Wikipedia (POJ)에서 일부 참조 영어 번역을 생성했습니다. GPT4 번역에서 "중간 텍스트"를 가져와 생성됩니다. 이것은 반드시 정확한 것은 아니지만 기초 역할을합니다.
후보 텍스트
일부 EN → NAN 번역을 생성했습니다 (GPT4 및 GPT3.5를 통해)
평가
Bleu를 기반으로 여러 평가를 생성했습니다
결론과 다음 단계
결과 : 이러한 평가의 BLEU 점수는 상당히 나쁘고 유니 그램 점수 만 0이 아닌 결과를 보여줍니다. 이것을 개선하려는 것들 :
단어보다는 음절에 의해 토큰 화되는보다 관대 한 poj 토큰 화기. 단어 분리가 항상 일관되지는 않기 때문입니다.
Diacritics를 무시하는보다 관대 한 poj 토큰 화기. 현재 POJ 소스가 일관되지 않을 수 있기 때문입니다.
초기 번역 모델을 위해 Hanzi를 POJ 변환 전에 기본 스크립트로 사용합니다.
중국어로 중국어를 사용합니다.
tâi-lô의 사용을 고려하십시오 (Hanzi → Tâi-Lô Converter는 현재 존재하지만 Hanzi → Poj One은 아닙니다). 그리고 Tâi-lô가 일부 소스 데이터에 어떤 영향을 미치는지.
"한지"와 같은 로마 화 된 단어를 LLM 프롬프트에서 "hàn-jī / hàn-lī"라고 말합니다. Hokkien 스크립트를 사용하면 더 정확한 Hokkien 어휘, 문법 및 스크립트 작성에 대해 LLM을 약간 편향시킬 수 있습니다.
파이프 라인 : 이들은 모두 스프레드 시트에서 생성되었습니다. 앞으로 데이터 파이프 라인의 일부로 자동화되어야합니다.