L'objectif de ce projet est de créer des traductions ML Hokkien de qualité.
Ce projet contient des outils pour aider à traduire et à évaluer l'anglais, Hokkien (script POJ), Hokkien (script Tai-Lo) et Hokkien (script 漢字 漢字 漢字 漢字 漢字.
Ce projet se concentre sur les traductions de texte à texte.
(Hokkien est également connu sous le nom de Minnan, Taïwanais, Hoklo, Southern Min et ISO 639-3: Nan.)
Démo
Essayez la démo en ligne du dernier modèle de traduction Hokkien
Mises à jour
2023-11-07
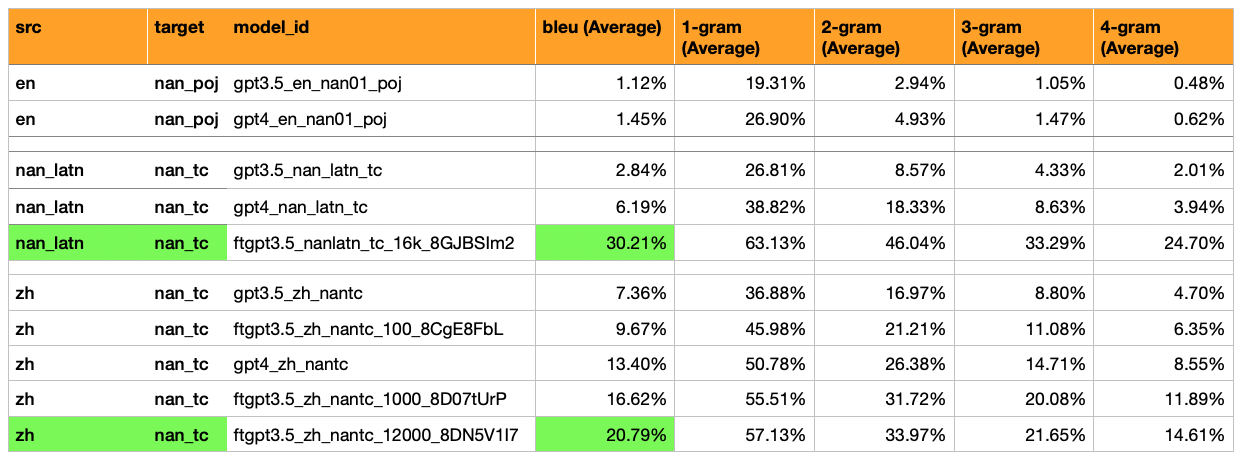
Modèles, traductions et évaluations ajoutées de Hokkien (script latin ) -> Hokkien (漢字 script) *
Hokkien (script latin) = un mélange de traductions / translatérations manuels et automatisés. Les automatisés sont un mélange de dialectes Hokkien Southern + Northern, ainsi qu'un mélange de scripts Tai-Lo et PoJ.
RÉSULTATS: GPT3,5 a rémunéré 30% BLEU (5x de plus que GPT4-Zero-Shot qui a obtenu 6%).
Résultats: Ce modèle serait utile pour le traitement de Hokkien Wikipedia, car il s'agit de la plus grande source de textes Hokkien facilement accessibles.
2023-10-31
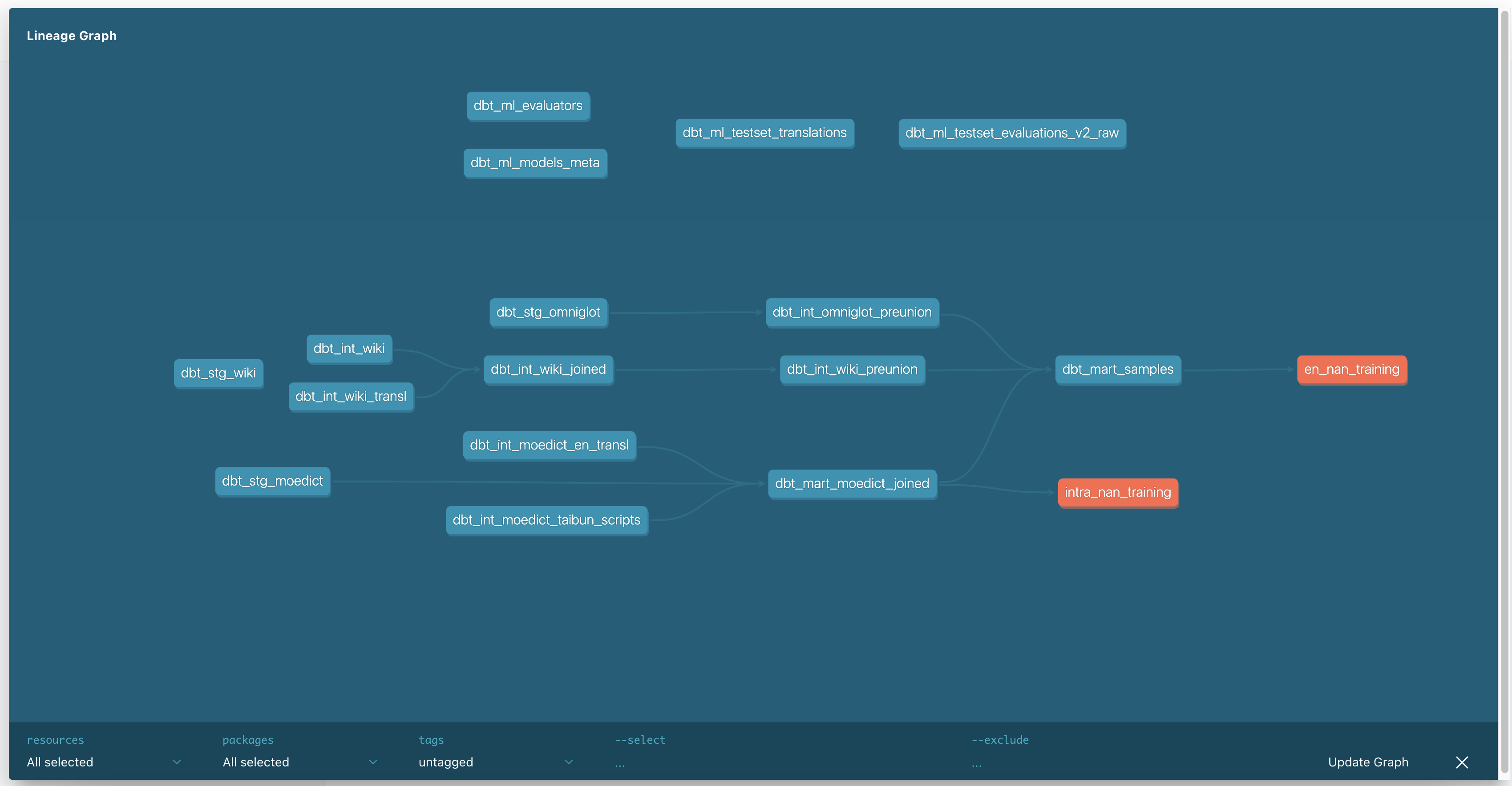
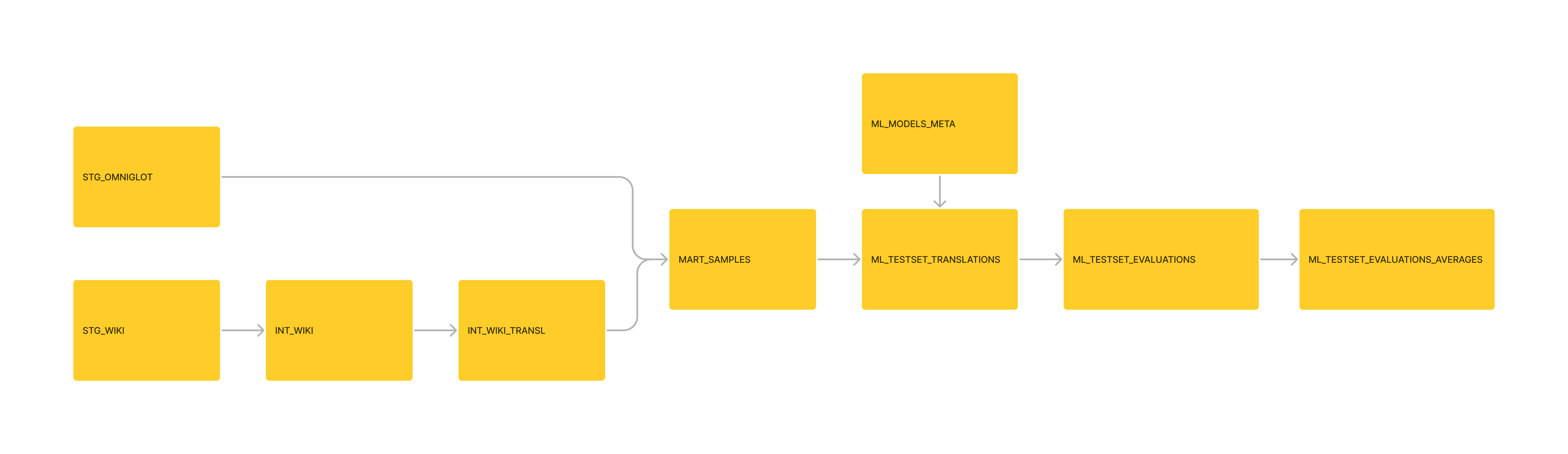
Gestion des données; A déplacé les transformations de base du moedict vers le pipeline DBT. Données moédits annexées pour les usèques Mart_Sample également.
2023-10-26
Ajout de traductions et évaluations de: GPT-3.5 Fine a été réglée sur 12 000 exemples (presque tous les échantillons de moedict), pour le mandarin -> Hokkien (漢字 script).
Résultat: score BLEU de 21
Conclusions:
Un modèle GPT3.5 finetuned fonctionne définitivement mieux qu'un modèle GPT4 zéro-shot lorsqu'il y a plus de 1000 paires de phrases.
Un modèle GPT3,5 finetuné avec ~ 10 000 paires de phrases fonctionne ~ ↑ 55% mieux que GPT4 Zero-Shot, et ~ ↑ 282% mieux que GPT3,5 Zero-Shot.
2023-10-24
Ajout de l'ensemble de données Moedict. Il avec une colonne "anglaise" (traduite du mandarin via GPT4).
Scores BLEU calculés avec de nouvelles données.
️ Les calculs de score BLEU découverts ont découvert. Mise à jour avec les scores BLEU corrigés!
(Structures de données: refactorisé afin qu'ils soient plus faciles à gérer.)
Résultats:
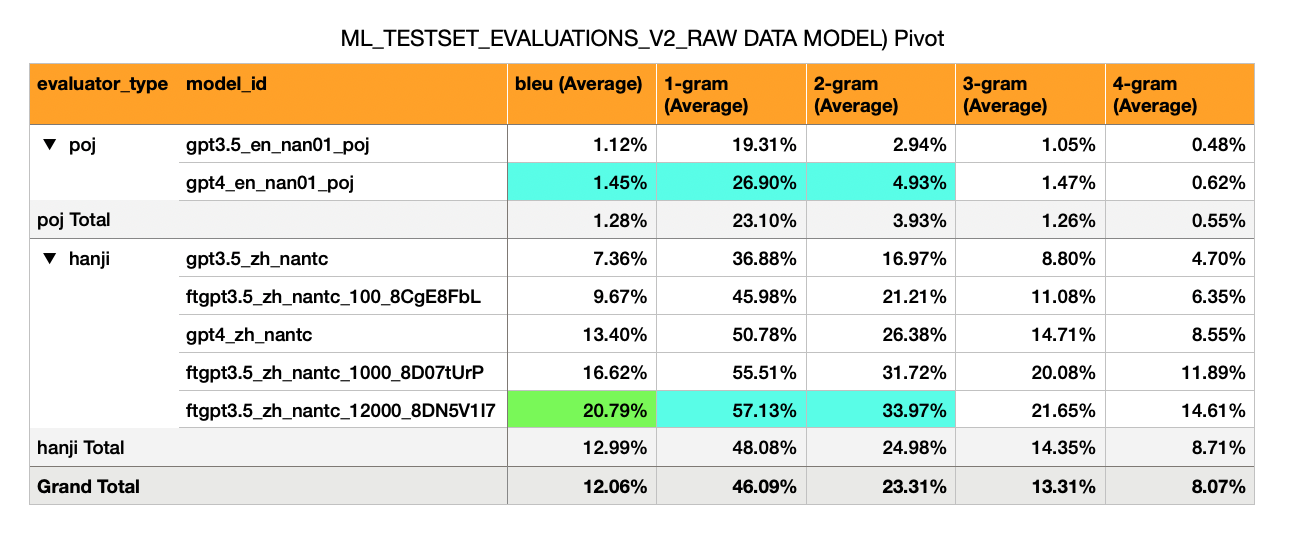
Anglais -> Hokkien (script POJ) - Les modèles NAIEVE initiaux ont des scores BLEU très faibles (1%)
Mandarin -> Hokkien (漢字 script) - a un BLEU beaucoup plus élevé (7% à 17%). Il s'agit d'environ la moitié de ce que l'on attendrait d'un score BLEU passable (30%).
GPT-3,5 Zero Shot: Bleu 7%
GPT-3.5 Fine a été réglé sur 100 exemples: 10%
GPT-4 Zero Shot: Bleu 13%
GPT-3,5 Fine a été réglé sur 1 000 exemples: 16%
(Yup, un modèle GPT3.5 affiné surpases GPT-4 Zero Shot)
Hypothèses:
Pour ZH-> NAN (TC): Étant donné le changement de magnitude avec le finetuning (0-> 100-> 1 000 exemples = 7% -> 10% -> 16% BLEU), il est prévisible que si la plupart du jeu de données Moédict est utilisé (~ 13 201 paires de phrases), alors il y a un risque que le score BLEU puisse atteindre un niveau passable (30%).
2023-10-19
Gestion: continuer à remplacer plus de modèles de données, par des modèles DBT.
2023-10-12
GESTION: FORMATÉ LA TABLEAU 'ML_TESTSET_EVALAUATIONS_ALERVEAT' ML_TESTSETSET_EVALUATIONS_AFFICATION en tant que modèle DBT, dans le cadre du pipeline.
2023-10-11
Gestion: Reformaté les données en tant que SQLite3 et initialisé un projet DBT à partir de celui-ci.
2023-10-10
Textes de référence
Rassemblé du texte de référence de Wikipedia (licence GFDL) et Omniglot (licence non commerciale)
Textes de référence nettoyés
Généré quelques traductions anglaises de référence de Minnan Wikipedia (POJ). Généré en prenant le "texte médian" des traductions GPT4. Ce n'est pas nécessairement exact, mais sert de base.
Textes candidats
Généré quelques traductions en → nan (via GPT4 et GPT3.5)
Évaluations
Généré plusieurs évaluations basées sur BLEU
Conclusions et étapes suivantes
Résultats: Les scores BLEU pour ces évaluations sont assez mauvais, avec seulement des scores d'unigrammes montrant les résultats non nuls. Choses à essayer d'améliorer ceci:
Un tokenizer POJ plus indulgent qui tokenise par syllabe plutôt que par mot. En effet, la séparation des mots n'est pas toujours cohérente.
Un tokenizer POJ plus indulgent qui ignore les diacritiques. En effet, les sources de POJ actuelles peuvent être incohérentes.
Utilisation de Hanzi comme script de base avant toute conversion POJ, pour les modèles de traduction précoces.
En utilisant le chinois mandarin comme intermédiaire.
Considérez l'utilisation de Tâi-lô (comme un convertisseur Hanzi → Tâi-lô existe actuellement, mais pas un Hanzi → Poj). Et comment Tâi-lô affecte certaines des données source.
Reportez-vous aux mots romanisés, comme "Hanzi", comme "Hàn-Jī / Hàn-lī" dans toutes les invites LLM. L'utilisation de scripts Hokkien peut légèrement biaiser le LLM vers le vocabulaire Hokkien, la grammaire et l'écriture de script plus précis.
Pipeline: Tout cela a été généré dans les feuilles de calcul. À l'avenir, ils devraient être mieux automatisés dans le cadre d'un pipeline de données.