UTAUTAI
1.0.0
 ? Извините за руку
? Извините за руку
Репозиторий с открытым исходным кодом, направленный на создание подходящих вокальных и инструментальных треков из текстов, аналогично чирп и рифузии Suno AI.
Метод Utautai в основном вдохновлен Spear TTS
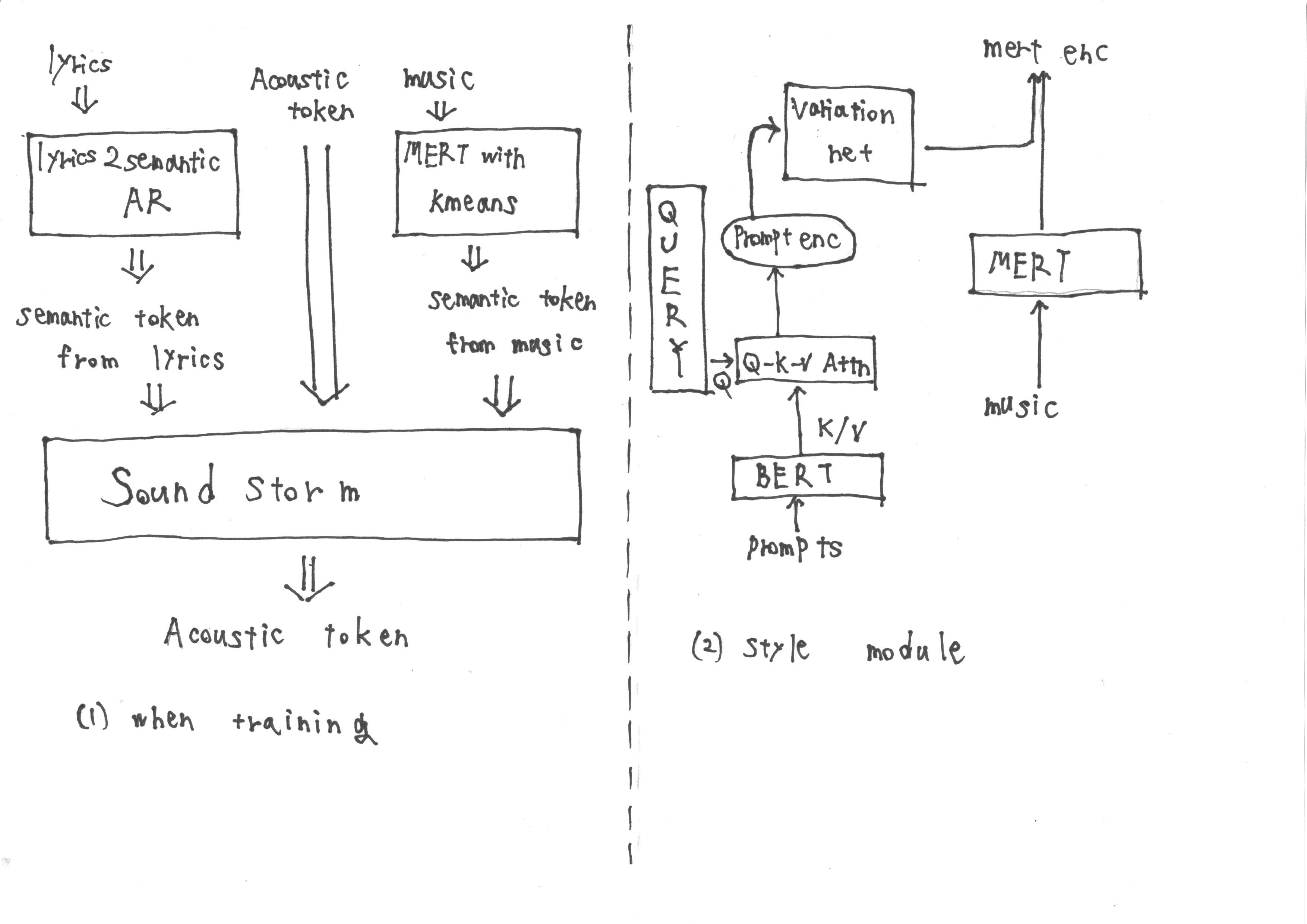
Во время тренировки вход состоит из семантических токенов, полученных из «текста2Semantic AR», которые извлекают семантические токены из текстов, а также акустических жетонов. Кроме того, представления MERT, полученные из музыки, подвергаются квантованию K-средних для получения дополнительных семантических токенов.
Однако во время вывода невозможно получить представления MERT от музыки. Поэтому мы обучаем стиль модуля с помощью методологии быстрого TTS2 для получения целевых представлений MERT из подсказки во время вывода. Модуль стиля состоит из диффузионной модели на основе трансформатора.
Я думаю, что, используя этот подход, мы можем успешно выполнить целевые задачи. Что вы думаете?
Если вы считаете Utautai интересным и полезным, дайте нам звезду на GitHub! ️ Это побуждает нас продолжать улучшать модель и добавлять захватывающие функции.
Вклад всегда приветствуются.


