UTAUTAI
1.0.0
 ? Désolé pour le dessin à main
? Désolé pour le dessin à main
Un référentiel open source visait à générer des morceaux vocaux et instrumentaux assortis de paroles, similaires au chirp et à la riffusion de Suno AI.
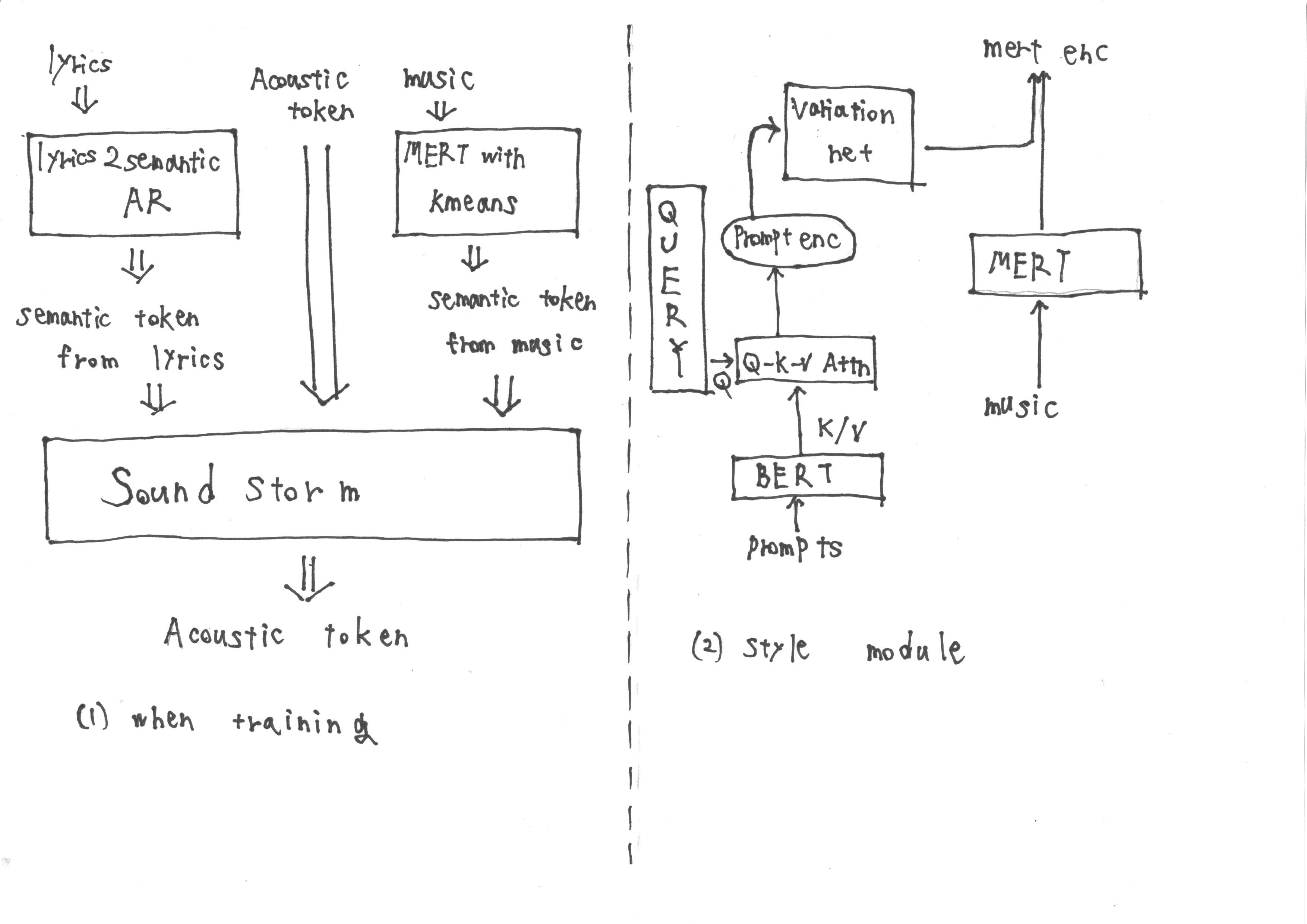
La méthode d'Utautai est principalement inspirée par Spear TTS
Pendant l'entraînement, la contribution se compose de jetons sémantiques obtenus à partir de «Lyrics2Sémantic AR», qui extrait les jetons sémantiques des paroles, ainsi que des jetons acoustiques. De plus, les représentations MERT dérivées de la musique sont soumises à la quantification des k-means pour obtenir d'autres jetons sémantiques.
Cependant, pendant l'inférence, il n'est pas possible d'obtenir des représentations Mert de la musique. Par conséquent, nous formons un module de style suivant la méthodologie de l'invite TTS2 à acquérir les représentations cibles Mert à partir de l'invite pendant l'inférence. Le module de style est composé d'un modèle de diffusion basé sur un transformateur.
Je pense qu'en utilisant cette approche, nous pouvons accomplir avec succès les tâches cibles. Qu'en penses-tu?
Si vous trouvez Utautai intéressant et utile, donnez-nous une étoile sur Github! ️ Il nous encourage à continuer d'améliorer le modèle et à ajouter des fonctionnalités passionnantes.
Les contributions sont toujours les bienvenues.


