UTAUTAI
1.0.0
 ? Desculpe pelo desenho à mão
? Desculpe pelo desenho à mão
Um repositório de código aberto destinado a gerar faixas vocais e instrumentais combinando a partir de letras, semelhantes ao chirp e riffusão de Samo Ai.
O método de Utautai é inspirado principalmente por Spear TTS
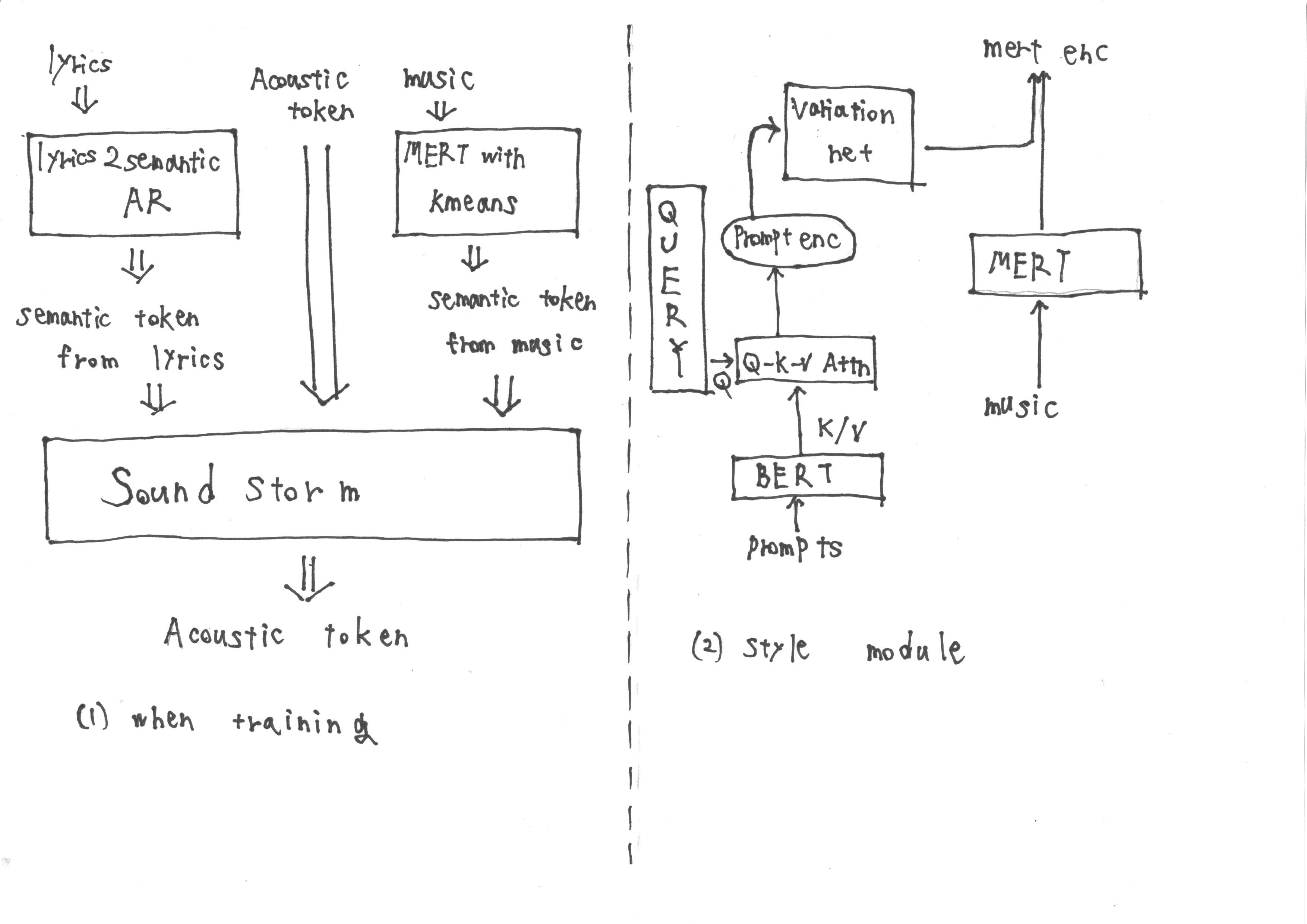
Durante o treinamento, a entrada consiste em tokens semânticos obtidos de 'Lyrics2Semantic AR', que extrai tokens semânticas das letras, bem como tokens acústicos. Além disso, as representações MERT derivadas da música são submetidas à quantização de K-means para obter mais tokens semânticos.
No entanto, durante a inferência, não é possível obter representações MERT da música. Portanto, treinamos um módulo de estilo seguindo a metodologia do prompt TTS2 para adquirir as representações de Mert de destino do prompt durante a inferência. O módulo de estilo é composto por um modelo de difusão baseado em transformador.
Penso que, usando essa abordagem, podemos realizar com sucesso as tarefas de destino. O que você acha?
Se você achar Utautai interessante e útil, dê -nos uma estrela no Github! ️ Isso nos incentiva a continuar melhorando o modelo e adicionando recursos interessantes.
As contribuições são sempre bem -vindas.


