UTAUTAI
1.0.0
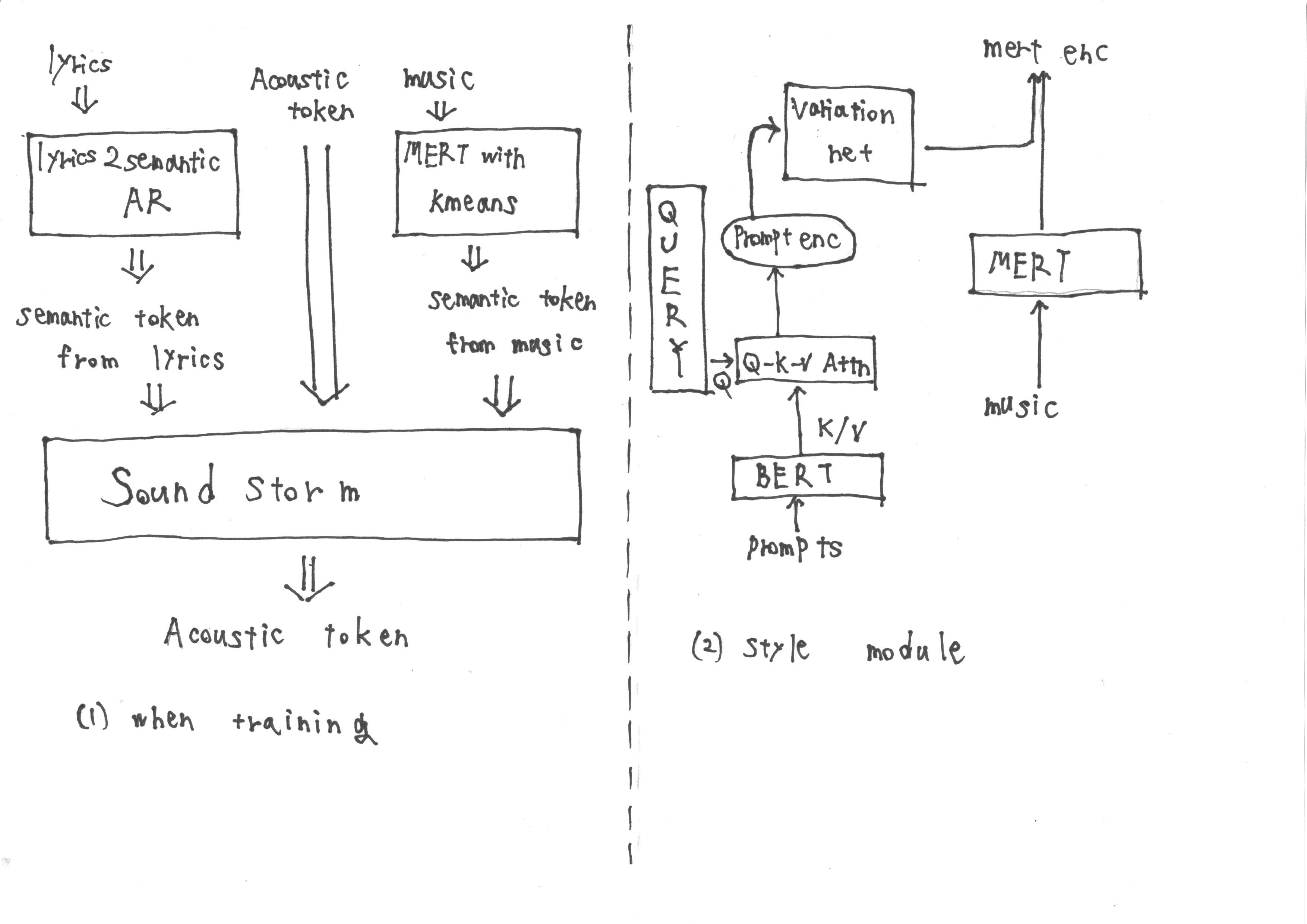 ?sorry for hand-draw
?sorry for hand-draw
An open-source repository aimed at generating matching vocal and instrumental tracks from lyrics, similar to Suno AI's Chirp and Riffusion.
UTAUTAI's method are mainly inspired by SPEAR TTS
During training, the input consists of semantic tokens obtained from 'lyrics2semantic AR', which extracts semantic tokens from lyrics, as well as Acoustic tokens. Additionally, MERT representations derived from the music are subjected to k-means quantization to obtain further semantic tokens.
However, during inference, it is not possible to obtain MERT representations from the music. Therefore, we train a Style Module following the methodology of Prompt TTS2 to acquire the target MERT representations from the prompt during inference. The Style Module is composed of a transformer-based diffusion model.
I think that using this approach, we can successfully accomplish the target tasks. What do you think?
If you find UTAUTAI interesting and useful, give us a star on GitHub! ️ It encourages us to keep improving the model and adding exciting features.
Contributions are always welcome.


