UTAUTAI
1.0.0
 ? Maaf untuk menggambar tangan
? Maaf untuk menggambar tangan
Repositori open-source yang bertujuan menghasilkan trek vokal dan instrumental yang cocok dari lirik, mirip dengan kicauan dan riffusi Suno Ai.
Metode Utautai terutama terinspirasi oleh tts tts
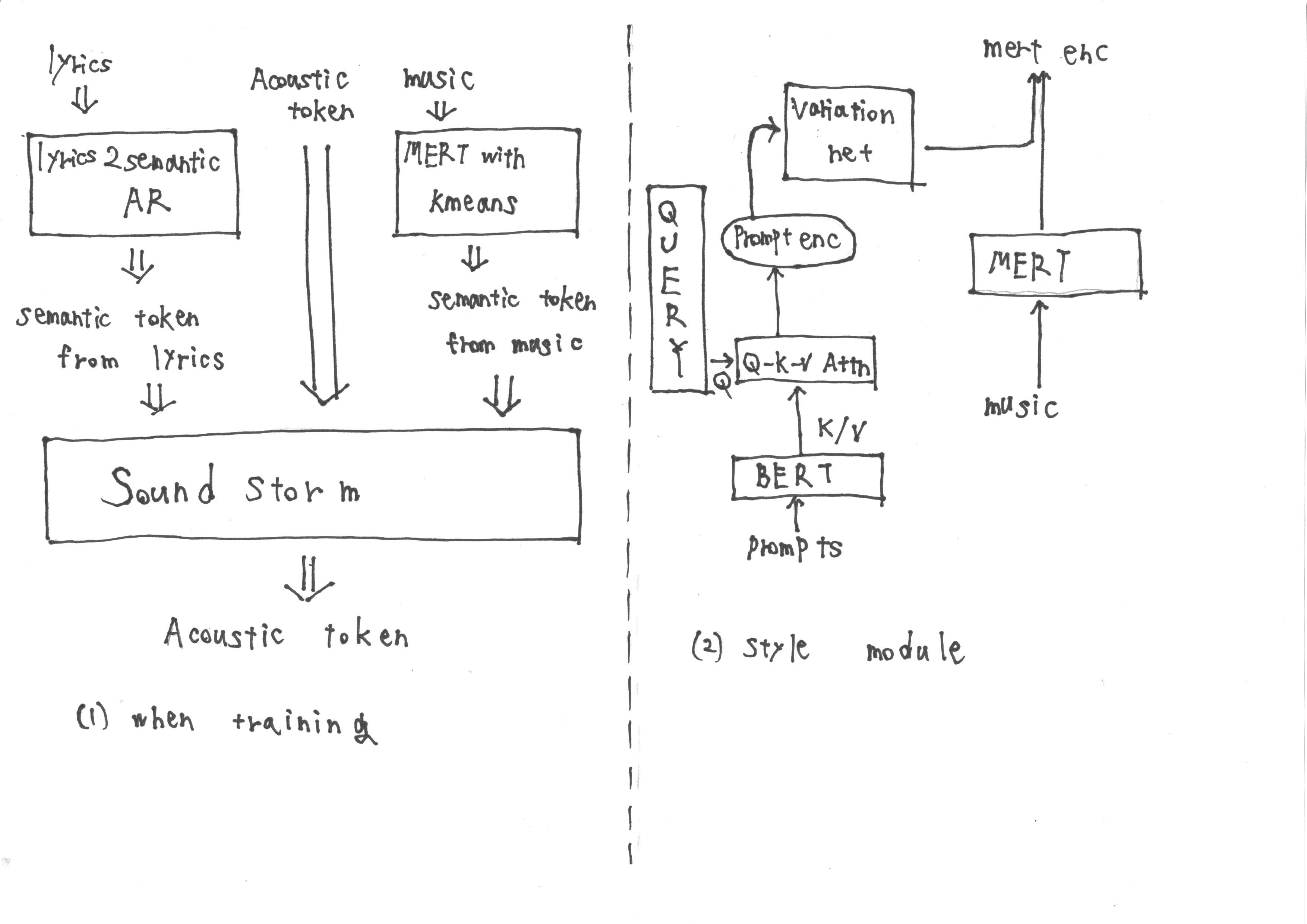
Selama pelatihan, input terdiri dari token semantik yang diperoleh dari 'lirik2semantic ar', yang mengekstraksi token semantik dari lirik, serta token akustik. Selain itu, representasi Mert yang berasal dari musik menjadi sasaran kuantisasi K-means untuk mendapatkan token semantik lebih lanjut.
Namun, selama inferensi, tidak mungkin untuk mendapatkan representasi Mert dari musik. Oleh karena itu, kami melatih modul gaya mengikuti metodologi TTS2 prompt untuk memperoleh representasi target Mert dari prompt selama inferensi. Modul gaya terdiri dari model difusi berbasis transformator.
Saya pikir menggunakan pendekatan ini, kita dapat berhasil menyelesaikan tugas target. Bagaimana menurutmu?
Jika Anda menganggap Utautai menarik dan bermanfaat, beri kami bintang di GitHub! ️ itu mendorong kita untuk terus meningkatkan model dan menambahkan fitur yang menarik.
Kontribusi selalu diterima.


