UTAUTAI
1.0.0
 Entschuldigung für die Handschaltung
Entschuldigung für die Handschaltung
Ein Open-Source-Repository, das mit der Erzeugung passender Gesangs- und Instrumental-Tracks aus Texten zielte, ähnlich wie bei Suno Ais Chirp und Riffusion.
Die Methode von Utautai ist hauptsächlich von Speer -TTs inspiriert
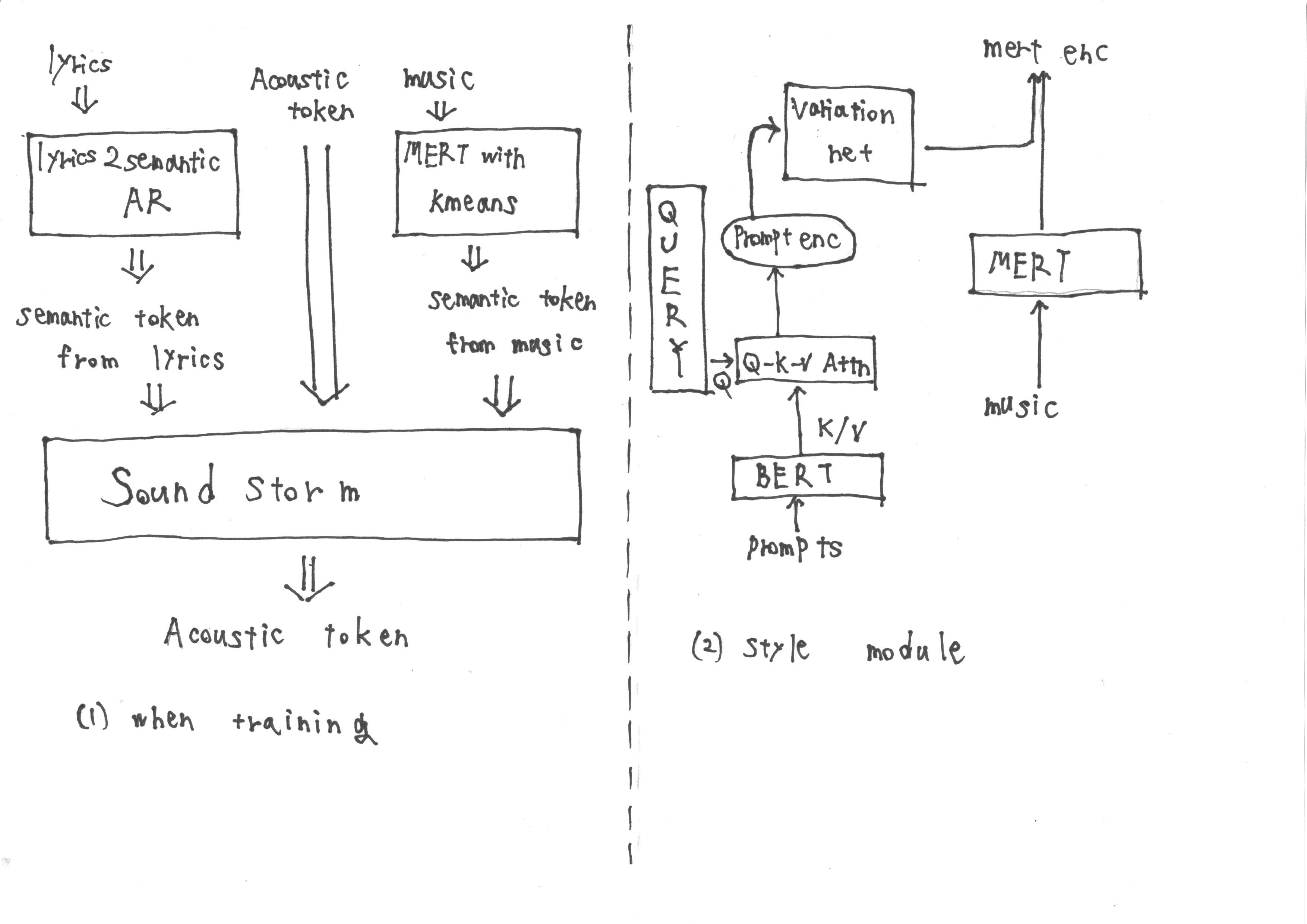
Während des Trainings besteht die Eingabe aus semantischen Token, die aus 'Lyrics2semantic AR' erhalten wurden, die semantische Token aus Texten sowie akustische Token extrahiert. Zusätzlich werden MERT-Darstellungen, die aus der Musik abgeleitet sind, einer Quantisierung von K-mittels K-Mittel unterzogen, um weitere semantische Token zu erhalten.
Während der Inferenz ist es jedoch nicht möglich, MERT -Darstellungen aus der Musik zu erhalten. Daher schulen wir ein Stilmodul, das der Methodik von forculiertem TTS2 nach der Eingabeaufforderung während der Inferenz aus der Eingabeaufforderung erfasst. Das Stilmodul besteht aus einem Transformator-basierten Diffusionsmodell.
Ich denke, dass wir mit diesem Ansatz die Zielaufgaben erfolgreich erledigen können. Was denken Sie?
Wenn Sie Utautai interessant und nützlich finden, geben Sie uns einen Stern auf Github! ️ es ermutigt uns, das Modell weiter zu verbessern und aufregende Funktionen hinzuzufügen.
Beiträge sind immer willkommen.


