UTAUTAI
1.0.0
 ?手描きでごめんなさい
?手描きでごめんなさい
Suno AiのChirpとRiffusionに似た、歌詞から一致するボーカルとインストゥルメンタルトラックを生成することを目的としたオープンソースリポジトリ。
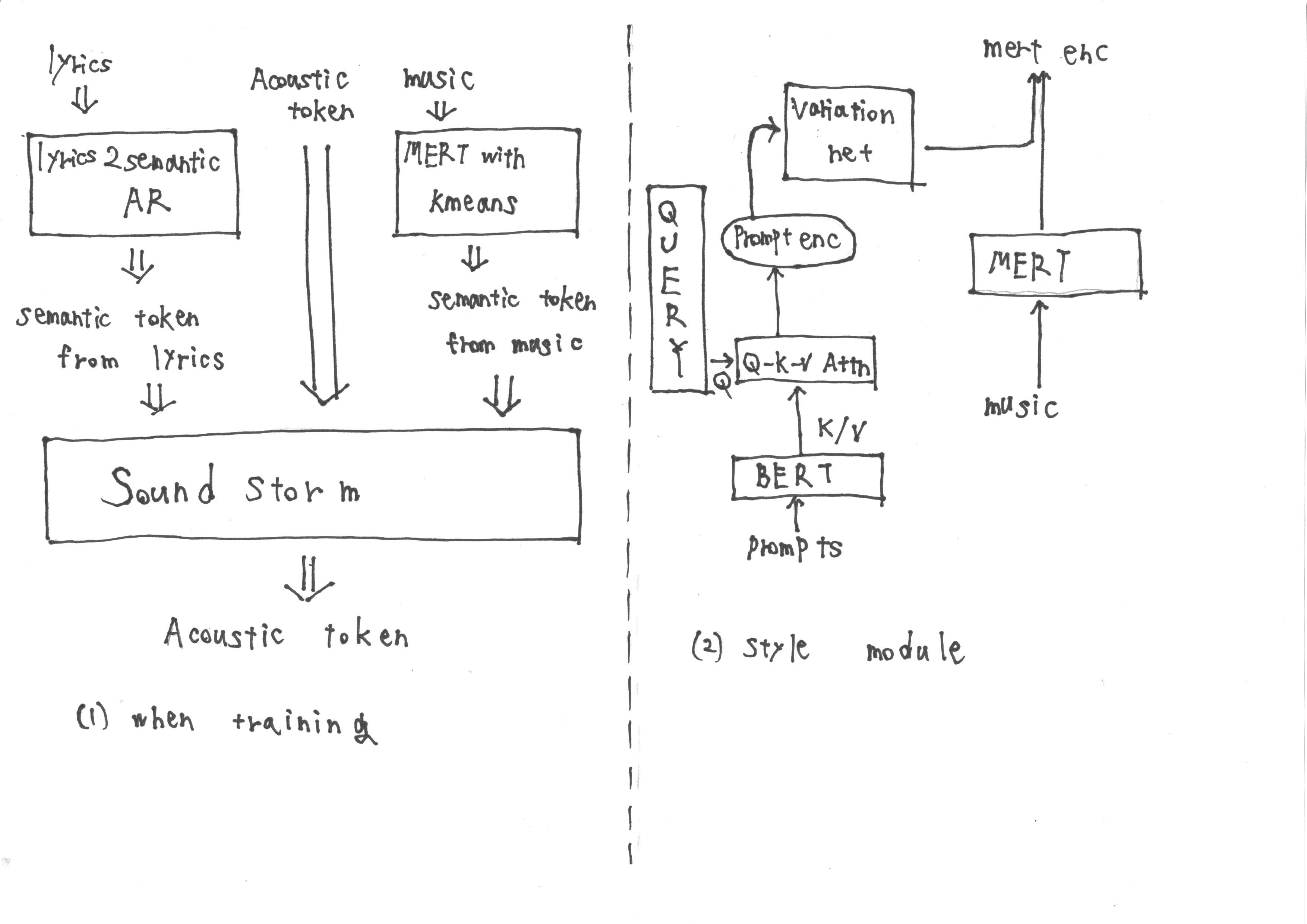
Utautaiの方法は、主にSpear TTSに触発されています
トレーニング中、入力は「歌詞2Semantic AR」から取得したセマンティックトークンで構成され、歌詞からセマンティックトークンとアコースティックトークンを抽出します。さらに、音楽から派生したMERT表現は、K-Meansの量子化にさらされて、さらにセマンティックトークンを取得します。
ただし、推論中は、音楽からMERT表現を取得することはできません。したがって、プロンプトTTS2の方法論に従ってスタイルモジュールをトレーニングして、推論中にプロンプトからターゲットMERT表現を取得します。スタイルモジュールは、変圧器ベースの拡散モデルで構成されています。
このアプローチを使用して、ターゲットタスクを正常に達成できると思います。どう思いますか?
Utautaiが面白くて便利だと思うなら、Githubでスターをください! §これは、モデルの改善を続け、エキサイティングな機能を追加することを奨励しています。
貢献はいつでも大歓迎です。


