ControlNet for Diffusers
1.0.0
Этот репозиторий предоставляет самый простой учебный код для разработчиков, использующих ControlNet с BaseModel в структуре Diffuser вместо WebUI. Наша работа сильно строится на других отличных работах. Хотя эти работы предприняли некоторые попытки, нет учебника для поддержки разнообразной ControlNet в диффузорах.
Мы также поддерживали T2-Adapter-For-Diffusers, Lora-For-Diffusers. Не будьте злым, чтобы дать нам звезду, если это Хельфул для вас.
Наша цель состоит в том, чтобы заменить BaseModel of ControlNet и сделать вывод в рамках диффузоров. Оригинальный ControlNet обучается в pytorch_lightning, а выпущенные веса только с стабильной диффузией-1,5 в качестве BaseModel. Тем не менее, для пользователей более гибко применяет свою собственную базодель вместо SD-1,5. Теперь давайте возьмем что-нибудь v3 в качестве примера. Мы покажем вам, как достичь этого (ControlNet-AnythingV3) шаг за шагом. Мы предоставляем демонстрацию Colab, но она работает только для пользователей Colab Pro с большей оперативной памятью.
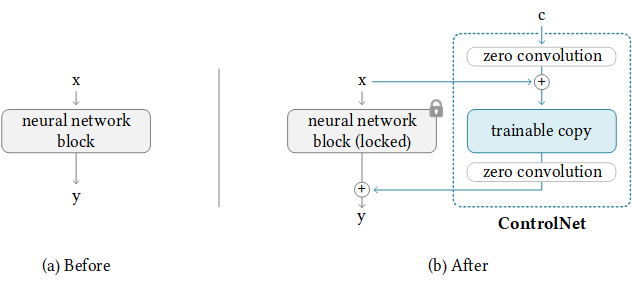
К счастью, ControlNet уже предоставил руководство по передаче ControlNet в любую другую модель сообщества. Логика позади, как показано ниже, где мы сохраняем дополнительные управляющие веса и только заменяем BaseModel. Обратите внимание, что это может не сработать всегда, так как ControlNet может иметь несколько весов в Basemodel.
NewBaseModel-ControlHint = NewBaseModel + OriginalBaseModel-ControlHint - OriginalBaseModelВо -первых, мы клонируем это репо из ControlNet.
git clone https://github.com/lllyasviel/ControlNet.git
cd ControlNetЗатем мы должны подготовить необходимые веса для оригинала BaseModel (path_sd15), оригинал Basemodel-controlhint (path_sd15_with_control), newbasemodel (path_input). Вам нужно только скачать следующие веса, и мы используем позу в качестве ControlHint и что-либо V3 в качестве нашей новой BaseModel. Мы помещаем все веса внутрь ./models.
path_sd15 = ' ./models/v1-5-pruned.ckpt '
path_sd15_with_control = ' ./models/control_sd15_openpose.pth '
path_input = ' ./models/anything-v3-full.safetensors '
path_output = ' ./models/control_any3_openpose.pth 'Наконец, мы можем прямо запустить
python tool_transfer_control.pyВ случае успеха вы получите новую модель. Эта модель уже можно использовать в кодовой базе ControlNet.
models/control_any3_openpose.pthЕсли вы хотите попробовать с другими моделями, вы можете просто определить свой собственный path_sd15_with_control и path_input. Если path_input обучен диффузорами, вы можете использовать Convert_diffusers_to_original_stable_diffusion.py, чтобы сначала преобразовать его в Safetensors.
С благодарностью, Takuma Mori поддерживает его в этом недавнем PR, чтобы мы могли легко достичь этого. Поскольку он все еще находится под разъяснением, он может быть нестабильным, поэтому мы должны использовать конкретную версию коммита. Мы замечаем, что Diffusers объединили PR в 3/2/2023, мы скоро переформим нашу учебник.
git clone https://github.com/takuma104/diffusers.git
cd diffusers
git checkout 9a37409663a53f775fa380db332d37d7ea75c915
pip install .Учитывая путь сгенерированной модели на шаге (1), запустите
python ./scripts/convert_controlnet_to_diffusers.py --checkpoint_path control_any3_openpose.pth --dump_path control_any3_openpose --device cpuУ нас есть сохраненная модель в CONTROL_ANY3_OPENPOLE. Теперь мы можем проверять это как регулярно.
from diffusers import StableDiffusionControlNetPipeline
from diffusers . utils import load_image
pose_image = load_image ( 'https://huggingface.co/takuma104/controlnet_dev/resolve/main/pose.png' )
pipe = StableDiffusionControlNetPipeline . from_pretrained ( "control_any3_openpose" ). to ( "cuda" )
pipe . safety_checker = lambda images , clip_input : ( images , False )
image = pipe ( prompt = "1gril,masterpiece,graden" , controlnet_hint = pose_image ). images [ 0 ]
image . save ( "generated.png" )Сгенерированный результат может быть недостаточно хорошим, так как поза довольно сложная. Таким образом, чтобы убедиться, что все идет хорошо, мы предлагаем генерировать обычную позу через PoseMaker или использовать наше предоставленное изображение Pose в ./images/pose.png.

Это должно поддержать ControlNet с возможностью изменять целевую область вместо полного изображения, как устойчиво-диффузионное инпаирование. На данный момент мы предоставляем условие (поза, карта сегментации) заранее, но вы можете использовать предварительно обученный детектор, используемый в ControlNet.
Мы предоставили необходимый трубопровод для использования. Но обратите внимание, что этот файл хрупкий без полного тестирования, мы рассмотрим его в рамках диффузоров формально позже. Кроме того, мы обнаруживаем, что ControlNet (на основе SD1.5) не совместима с стабильной диффузией-2-инпаинтией, поскольку некоторые слои имеют разные модули и размер, если вы насильно загружаете веса и пропустите эти непревзойденные слои, результат будет плохим
# assume you already know the absolute path of installed diffusers
cp pipeline_stable_diffusion_controlnet_inpaint.py PATH/pipelines/stable_diffusionЗатем вам нужно импортировать этот новый добавленный конвейер в соответствующих файлах
PATH/pipelines/__init__.py
PATH/__init__.py
Теперь мы можем бежать
import torch
from diffusers . utils import load_image
from diffusers import StableDiffusionInpaintPipeline , StableDiffusionControlNetInpaintPipeline
# we have downloaded models locally, you can also load from huggingface
# control_sd15_seg is converted from control_sd15_seg.safetensors using instructions above
pipe_control = StableDiffusionControlNetInpaintPipeline . from_pretrained ( "./diffusers/control_sd15_seg" , torch_dtype = torch . float16 ). to ( 'cuda' )
pipe_inpaint = StableDiffusionInpaintPipeline . from_pretrained ( "./diffusers/stable-diffusion-inpainting" , torch_dtype = torch . float16 ). to ( 'cuda' )
# yes, we can directly replace the UNet
pipe_control . unet = pipe_inpaint . unet
pipe_control . unet . in_channels = 4
# we also the same example as stable-diffusion-inpainting
image = load_image ( "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png" )
mask = load_image ( "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png" )
# the segmentation result is generated from https://huggingface.co/spaces/hysts/ControlNet
control_image = load_image ( 'tmptvkkr0tg.png' )
image = pipe_control ( prompt = "Face of a yellow cat, high resolution, sitting on a park bench" ,
negative_prompt = "lowres, bad anatomy, worst quality, low quality" ,
controlnet_hint = control_image ,
image = image ,
mask_image = mask ,
num_inference_steps = 100 ). images [ 0 ]
image . save ( "inpaint_seg.jpg" )Следующие изображения представляют собой исходное изображение, изображение маски, сегментация (намек на управление) и сгенерированное новое изображение.


Вы также можете использовать позу в качестве контрольного намека. Но обратите внимание, что предлагается использовать открытый формат, который согласуется с процессом обучения. Если вы просто хотите протестировать несколько изображений без установки Openpose Locally, вы можете напрямую использовать онлайн -демонстрацию ControlNet для генерации изображения Pose, учитывая вход соответствующего размера 512x512.
image = load_image ( "./images/pose_image.jpg" )
mask = load_image ( "./images/pose_mask.jpg" )
pose_image = load_image ( './images/pose_hint.png' )
image = pipe_control ( prompt = "Face of a young boy smiling" ,
negative_prompt = "lowres, bad anatomy, worst quality, low quality" ,
controlnet_hint = pose_image ,
image = image ,
mask_image = mask ,
num_inference_steps = 100 ). images [ 0 ]
image . save ( "inpaint_pos.jpg" )


Мы загрузили Pipeline_stable_diffusion_controlnet_inpaint_img2img.py для поддержки img2img. Вы можете следовать той же инструкции, что и в этом разделе.
Подобно T2-Adapter, ControlNet также поддерживает несколько управляющих изображений в качестве входных. Идея проста, так как базовая модель заморожена, мы можем объединить выходы из ControlNet1 и ControlNet2 и использовать ее в качестве входных данных для UNET. Здесь мы предоставляем псевдокод для справки. Вам нужно изменить трубопровод, как показано ниже.
control1 = controlnet1 ( latent_model_input , t , encoder_hidden_states = prompt_embeds , controlnet_hint = controlnet_hint1 )
control2 = controlnet2 ( latent_model_input , t , encoder_hidden_states = prompt_embeds , controlnet_hint = controlnet_hint2 )
# please note that the weights should be adjusted accordingly
control1_weight = 1.00 # control_any3_openpose
control2_weight = 0.50 # control_sd15_depth
merged_control = []
for i in range ( len ( control1 )):
merged_control . append ( control1_weight * control [ i ] + control2_weight * control_1 [ i ])
control = merged_control
noise_pred = unet ( latent_model_input , t , encoder_hidden_states = prompt_embeds , cross_attention_kwargs = cross_attention_kwargs , control = control ). sampleВот пример мультиконтролнета, где мы используем позу, а карта глубины-это контрольные подсказки. Тестовые изображения оба зачислены на T2-Adapter.


Чтобы избежать этого репо, мы слишком раздутыми, мы предоставляем учебные пособия по обучению в управлении поездами-в-диффузиторам.
Сначала мы благодарим автора ControlNet за такую отличную работу, наш код конвертации заимствован отсюда. Мы также ценим вклады из этого запроса на притяжение в диффузорах, чтобы мы могли загружать ControlNet в диффузоры.
Репо все еще находится в активном развитии, если у вас есть какие -либо проблемы при его использовании, не стесняйтесь открывать проблему.


