ControlNet for Diffusers
1.0.0
Repositori ini menyediakan kode tutorial paling sederhana untuk pengembang yang menggunakan ControlNet dengan basemodel dalam kerangka kerja diffuser, bukan WebUI. Pekerjaan kami dibangun sangat di atas karya -karya luar biasa lainnya. Meskipun karya -karya tesis telah melakukan beberapa upaya, tidak ada tutorial untuk mendukung beragam controlNet pada diffuser.
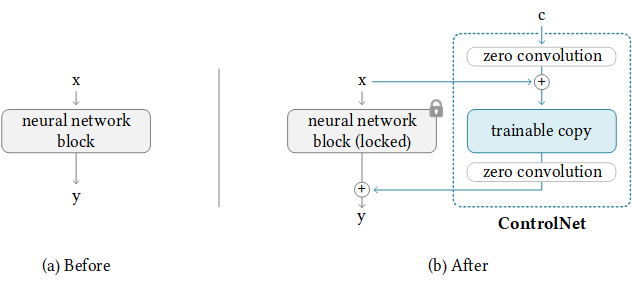
Kami juga telah mendukung T2I-Adapter-for-Diffusers, Lora-For-Diffusers. Jangan maksudkan untuk memberi kami bintang jika itu helful bagi Anda.
Tujuan kami adalah mengganti basemodel ControlNet dan menyimpulkan dalam kerangka kerja difuser. ControlNet asli dilatih dalam pytorch_lightning, dan bobot yang dilepaskan dengan hanya difusi stabil-1.5 sebagai basemodel. Namun, lebih fleksibel bagi pengguna untuk mengadopsi basemodel mereka sendiri daripada SD-1.5. Sekarang, mari kita ambil apa pun-V3 sebagai contoh. Kami akan menunjukkan kepada Anda cara mencapai ini (controlNet-anythingv3) langkah demi langkah. Kami memang menyediakan demo Colab, tetapi hanya berfungsi untuk pengguna Colab Pro dengan RAM yang lebih besar.
Untungnya, ControlNet telah memberikan pedoman untuk mentransfer ControlNet ke model komunitas lainnya. Logika di belakang adalah seperti di bawah ini, di mana kami menjaga bobot kontrol tambahan dan hanya mengganti basemodel. Perhatikan bahwa ini mungkin tidak bekerja selalu, karena ControlNet mungkin memiliki beberapa bobot pelatihan di basemodel.
NewBaseModel-ControlHint = NewBaseModel + OriginalBaseModel-ControlHint - OriginalBaseModelPertama, kami mengkloning repo ini dari ControlNet.
git clone https://github.com/lllyasviel/ControlNet.git
cd ControlNetKemudian, kita harus menyiapkan bobot yang diperlukan untuk asliBasemodel (Path_SD15), originalBasemodel-controlhint (path_sd15_with_control), newbasemodel (path_input). Anda hanya perlu mengunduh bobot berikut, dan kami menggunakan Pose sebagai ControlHint dan apa pun-V3 sebagai basemodel baru kami misalnya. Kami menempatkan semua bobot di dalam ./models.
path_sd15 = ' ./models/v1-5-pruned.ckpt '
path_sd15_with_control = ' ./models/control_sd15_openpose.pth '
path_input = ' ./models/anything-v3-full.safetensors '
path_output = ' ./models/control_any3_openpose.pth 'Akhirnya, kita bisa langsung berlari
python tool_transfer_control.pyJika berhasil, Anda akan mendapatkan model baru. Model ini sudah dapat digunakan dalam basis kode ControlNet.
models/control_any3_openpose.pthJika Anda ingin mencoba dengan model lain, Anda bisa mendefinisikan Path_SD15_With_Control dan Path_input Anda sendiri. Jika path_input dilatih dengan diffuser, Anda dapat menggunakan convert_diffusers_to_original_stable_diffusion.py untuk mengubahnya menjadi safetensor terlebih dahulu.
Dengan penuh syukur, Takuma Mori telah mendukungnya dalam PR baru -baru ini, sehingga kita dapat dengan mudah mencapai ini. Karena masih kurang devlopement, jadi mungkin tidak stabil, maka kita harus menggunakan versi komit tertentu. Kami melihat bahwa diffusers telah menggabungkan PR pada 3/2/2023, kami akan segera memformat ulang tutorial kami.
git clone https://github.com/takuma104/diffusers.git
cd diffusers
git checkout 9a37409663a53f775fa380db332d37d7ea75c915
pip install .Mengingat jalur model yang dihasilkan pada langkah (1), jalankan
python ./scripts/convert_controlnet_to_diffusers.py --checkpoint_path control_any3_openpose.pth --dump_path control_any3_openpose --device cpuKami memiliki model yang disimpan di control_any3_openpose. Sekarang kita bisa mengujinya secara teratur.
from diffusers import StableDiffusionControlNetPipeline
from diffusers . utils import load_image
pose_image = load_image ( 'https://huggingface.co/takuma104/controlnet_dev/resolve/main/pose.png' )
pipe = StableDiffusionControlNetPipeline . from_pretrained ( "control_any3_openpose" ). to ( "cuda" )
pipe . safety_checker = lambda images , clip_input : ( images , False )
image = pipe ( prompt = "1gril,masterpiece,graden" , controlnet_hint = pose_image ). images [ 0 ]
image . save ( "generated.png" )Hasil yang dihasilkan mungkin tidak cukup baik karena pose ini agak sulit. Jadi untuk memastikan semuanya berjalan dengan baik, kami sarankan untuk menghasilkan pose normal melalui Posemaker atau menggunakan gambar pose yang disediakan di ./images/pose.png.

Ini untuk mendukung ControlNet dengan kemampuan untuk hanya memodifikasi wilayah target alih-alih gambar penuh seperti halnya difusi stabil. Untuk saat ini, kami memberikan kondisi (pose, peta segmentasi) sebelumnya, tetapi Anda dapat menggunakan detektor yang diadopsi pra-terlatih yang digunakan dalam ControlNet.
Kami telah menyediakan pipa yang diperlukan untuk penggunaan. Tetapi harap dicatat bahwa file ini rapuh tanpa pengujian lengkap, kami akan mempertimbangkan mendukungnya dalam kerangka kerja difusal secara formal nanti. Kami juga menemukan bahwa controlNet (berbasis SD1.5) tidak kompatibel dengan stabil-difusi-2-inpainting, karena beberapa lapisan memiliki modul dan dimensi yang berbeda, jika Anda memuat bobot secara paksa dan melewatkan lapisan yang tak tertandingi, hasilnya akan buruk
# assume you already know the absolute path of installed diffusers
cp pipeline_stable_diffusion_controlnet_inpaint.py PATH/pipelines/stable_diffusionKemudian, Anda perlu mengimpor pipa tambahan baru ini di file yang sesuai
PATH/pipelines/__init__.py
PATH/__init__.py
Sekarang, kita bisa berlari
import torch
from diffusers . utils import load_image
from diffusers import StableDiffusionInpaintPipeline , StableDiffusionControlNetInpaintPipeline
# we have downloaded models locally, you can also load from huggingface
# control_sd15_seg is converted from control_sd15_seg.safetensors using instructions above
pipe_control = StableDiffusionControlNetInpaintPipeline . from_pretrained ( "./diffusers/control_sd15_seg" , torch_dtype = torch . float16 ). to ( 'cuda' )
pipe_inpaint = StableDiffusionInpaintPipeline . from_pretrained ( "./diffusers/stable-diffusion-inpainting" , torch_dtype = torch . float16 ). to ( 'cuda' )
# yes, we can directly replace the UNet
pipe_control . unet = pipe_inpaint . unet
pipe_control . unet . in_channels = 4
# we also the same example as stable-diffusion-inpainting
image = load_image ( "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png" )
mask = load_image ( "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png" )
# the segmentation result is generated from https://huggingface.co/spaces/hysts/ControlNet
control_image = load_image ( 'tmptvkkr0tg.png' )
image = pipe_control ( prompt = "Face of a yellow cat, high resolution, sitting on a park bench" ,
negative_prompt = "lowres, bad anatomy, worst quality, low quality" ,
controlnet_hint = control_image ,
image = image ,
mask_image = mask ,
num_inference_steps = 100 ). images [ 0 ]
image . save ( "inpaint_seg.jpg" )Gambar -gambar berikut adalah gambar asli, gambar topeng, segmentasi (petunjuk kontrol) dan menghasilkan gambar baru.


Anda juga dapat menggunakan pose sebagai petunjuk kontrol. Tetapi harap dicatat bahwa disarankan untuk menggunakan format OpenPose, yang konsisten dengan proses pelatihan. Jika Anda hanya ingin menguji beberapa gambar tanpa menginstal OpenPose secara lokal, Anda dapat langsung menggunakan demo online ControlNet untuk menghasilkan gambar pose mengingat input 512x512 yang diubah ukurannya.
image = load_image ( "./images/pose_image.jpg" )
mask = load_image ( "./images/pose_mask.jpg" )
pose_image = load_image ( './images/pose_hint.png' )
image = pipe_control ( prompt = "Face of a young boy smiling" ,
negative_prompt = "lowres, bad anatomy, worst quality, low quality" ,
controlnet_hint = pose_image ,
image = image ,
mask_image = mask ,
num_inference_steps = 100 ). images [ 0 ]
image . save ( "inpaint_pos.jpg" )


Kami telah mengunggah pipeline_stable_diffusion_controlnet_inpaint_img2img.py untuk mendukung img2img. Anda dapat mengikuti instruksi yang sama dengan bagian ini.
Mirip dengan T2I-Adapter, ControlNet juga mendukung beberapa gambar kontrol sebagai input. Gagasan di baliknya sederhana, karena model dasar dibekukan, kita dapat menggabungkan output dari controlnet1 dan controlnet2, dan menggunakannya sebagai input untuk tidak. Di sini, kami menyediakan pseudocode untuk referensi. Anda perlu memodifikasi pipa seperti di bawah ini.
control1 = controlnet1 ( latent_model_input , t , encoder_hidden_states = prompt_embeds , controlnet_hint = controlnet_hint1 )
control2 = controlnet2 ( latent_model_input , t , encoder_hidden_states = prompt_embeds , controlnet_hint = controlnet_hint2 )
# please note that the weights should be adjusted accordingly
control1_weight = 1.00 # control_any3_openpose
control2_weight = 0.50 # control_sd15_depth
merged_control = []
for i in range ( len ( control1 )):
merged_control . append ( control1_weight * control [ i ] + control2_weight * control_1 [ i ])
control = merged_control
noise_pred = unet ( latent_model_input , t , encoder_hidden_states = prompt_embeds , cross_attention_kwargs = cross_attention_kwargs , control = control ). sampleBerikut adalah contoh multi-controlnet, di mana kami menggunakan pose dan peta kedalaman adalah petunjuk kontrol. Gambar uji keduanya dikreditkan ke T2I-Adapter.


Untuk menghindari repo ini terlalu membengkak, kami memberikan tutorial tentang pelatihan di train-controlnet-in-diffusers.
Kami pertama -tama berterima kasih kepada penulis ControlNet untuk pekerjaan yang luar biasa, kode konversi kami dipinjam dari sini. Kami juga menghargai kontribusi dari permintaan tarik ini di Diffusers, sehingga kami dapat memuat ControlNet ke Diffusers.
Repo masih dalam pengembangan aktif, jika Anda memiliki masalah saat menggunakannya, jangan ragu untuk membuka masalah.


