ControlNet for Diffusers
1.0.0
このリポジトリは、WebUIの代わりにDiffuser FrameworkでBaseModelを使用してControlNetを使用して開発者向けの最もシンプルなチュートリアルコードを提供します。私たちの作品は、他の優れた作品に高く構築されています。これらの作品はいくつかの試みを行っていますが、ディフューザーの多様なコントロールネットをサポートするためのチュートリアルはありません。
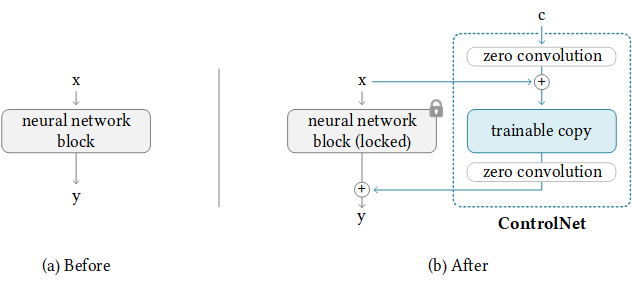
また、T2I-Adapter-For-DiffusersであるLora-For-Diffusersもサポートしています。それがあなたにぴったりであるならば、私たちに星を与えることを意図しないでください。
私たちの目標は、diffusersフレームワークでコントロールネットと推測のベースモデルを置き換えることです。元のControlNetは、Pytorch_lightningでトレーニングされており、安定した拡散-1.5のみでリリースされた重量がベースモデルとしてトレーニングされています。ただし、ユーザーがSD-1.5の代わりに独自のベースモデルを採用する方が柔軟です。それでは、何かv3を例にとらえましょう。これを実現する方法(ControlNet-Anythingv3)を段階的に紹介します。 Colab Demoは提供していますが、RAMが大きいColab Proユーザーでのみ機能します。
幸いなことに、ControlNetはすでにControlNetを他のコミュニティモデルに転送するためのガイドラインを提供しています。背後にあるロジックは以下のように、追加のコントロールウェイトを保持し、ベースメモデルのみを置き換えます。コントロールネットにはベースメモデルにある訓練可能なウェイトがあるため、これは常に機能しない可能性があることに注意してください。
NewBaseModel-ControlHint = NewBaseModel + OriginalBaseModel-ControlHint - OriginalBaseModelまず、ControlNetからこのレポをクローンします。
git clone https://github.com/lllyasviel/ControlNet.git
cd ControlNet次に、OriginalBaseModel(path_sd15)、originalbasemodel-controlhint(path_sd15_with_control)、newbasemodel(path_input)に必要なウェイトを準備する必要があります。次のウェイトをダウンロードするだけで、たとえば新しいベースメモデルとしてcontrolhintおよびAnything-v3を使用します。すべてのウェイトを./models内に入れます。
path_sd15 = ' ./models/v1-5-pruned.ckpt '
path_sd15_with_control = ' ./models/control_sd15_openpose.pth '
path_input = ' ./models/anything-v3-full.safetensors '
path_output = ' ./models/control_any3_openpose.pth '最後に、直接実行できます
python tool_transfer_control.py成功すれば、新しいモデルが取得されます。このモデルは、既にControlNet CodeBaseで使用できます。
models/control_any3_openpose.pth他のモデルで試してみたい場合は、独自のPATH_SD15_WITH_CONTROLとPATH_INPUTを定義できます。 PATH_INPUTがDiffusersでトレーニングされている場合、convert_diffusers_to_original_stable_diffusion.pyを使用して、最初にSafetensorsに変換できます。
ありがたいことに、森はこの最近のPRでそれをサポートしているので、これを簡単に達成できます。まだ不安定であるため、不安定な場合があるため、特定のコミットバージョンを使用する必要があります。 Diffusersが2013年3月2日にPRを統合したことに気付き、すぐにチュートリアルを再フォーマットします。
git clone https://github.com/takuma104/diffusers.git
cd diffusers
git checkout 9a37409663a53f775fa380db332d37d7ea75c915
pip install .ステップ(1)に生成されたモデルのパスが与えられた場合、実行する
python ./scripts/convert_controlnet_to_diffusers.py --checkpoint_path control_any3_openpose.pth --dump_path control_any3_openpose --device cpucontrol_any3_openposeに保存されたモデルがあります。これで、定期的にテストできます。
from diffusers import StableDiffusionControlNetPipeline
from diffusers . utils import load_image
pose_image = load_image ( 'https://huggingface.co/takuma104/controlnet_dev/resolve/main/pose.png' )
pipe = StableDiffusionControlNetPipeline . from_pretrained ( "control_any3_openpose" ). to ( "cuda" )
pipe . safety_checker = lambda images , clip_input : ( images , False )
image = pipe ( prompt = "1gril,masterpiece,graden" , controlnet_hint = pose_image ). images [ 0 ]
image . save ( "generated.png" )生成された結果は、ポーズがちょっと困難であるため、十分ではないかもしれません。したがって、すべてがうまくいくことを確認するために、Posemakerを介して通常のポーズを生成するか、提供されたポーズ画像を./images/pose.pngで使用することをお勧めします。

これは、安定した拡散のように完全な画像の代わりにターゲット領域を変更する機能を備えたControlNetをサポートするためです。今のところ、事前に条件(ポーズ、セグメンテーションマップ)を提供していますが、ControlNetで使用される事前に訓練された検出器を使用できます。
使用に必要なパイプラインを提供しました。ただし、このファイルは完全なテストなしでは脆弱であることに注意してください。ディフューザーフレームワークでは、後で正式にサポートを検討します。また、一部のレイヤーには異なるモジュールと寸法があるため、コントロールネット(SD1.5ベース)は安定した拡散-2インペインティングと互換性がないことがわかります。
# assume you already know the absolute path of installed diffusers
cp pipeline_stable_diffusion_controlnet_inpaint.py PATH/pipelines/stable_diffusion次に、対応するファイルにこの新しい追加されたパイプラインをインポートする必要があります
PATH/pipelines/__init__.py
PATH/__init__.py
今、私たちは実行できます
import torch
from diffusers . utils import load_image
from diffusers import StableDiffusionInpaintPipeline , StableDiffusionControlNetInpaintPipeline
# we have downloaded models locally, you can also load from huggingface
# control_sd15_seg is converted from control_sd15_seg.safetensors using instructions above
pipe_control = StableDiffusionControlNetInpaintPipeline . from_pretrained ( "./diffusers/control_sd15_seg" , torch_dtype = torch . float16 ). to ( 'cuda' )
pipe_inpaint = StableDiffusionInpaintPipeline . from_pretrained ( "./diffusers/stable-diffusion-inpainting" , torch_dtype = torch . float16 ). to ( 'cuda' )
# yes, we can directly replace the UNet
pipe_control . unet = pipe_inpaint . unet
pipe_control . unet . in_channels = 4
# we also the same example as stable-diffusion-inpainting
image = load_image ( "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png" )
mask = load_image ( "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png" )
# the segmentation result is generated from https://huggingface.co/spaces/hysts/ControlNet
control_image = load_image ( 'tmptvkkr0tg.png' )
image = pipe_control ( prompt = "Face of a yellow cat, high resolution, sitting on a park bench" ,
negative_prompt = "lowres, bad anatomy, worst quality, low quality" ,
controlnet_hint = control_image ,
image = image ,
mask_image = mask ,
num_inference_steps = 100 ). images [ 0 ]
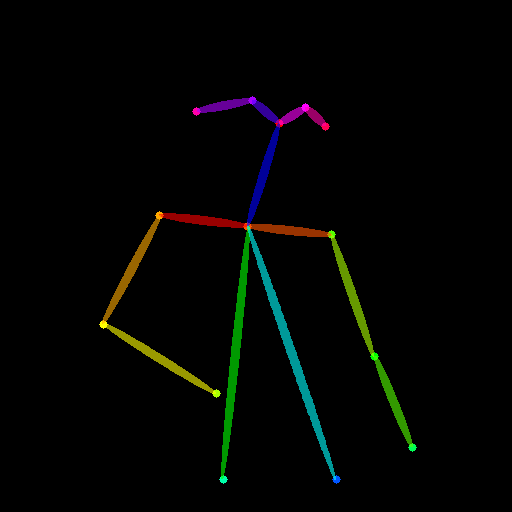
image . save ( "inpaint_seg.jpg" )次の画像は、元の画像、マスク画像、セグメンテーション(制御ヒント)、および新しい画像を生成しました。


コントロールのヒントとしてポーズを使用することもできます。ただし、トレーニングプロセスに一致するOpenPose形式を使用することが提案されていることに注意してください。 OpenPoseをローカルにインストールせずにいくつかの画像をテストするだけの場合、ControlNetのオンラインデモを使用して、サイズ変更された512x512入力を考慮してポーズ画像を生成できます。
image = load_image ( "./images/pose_image.jpg" )
mask = load_image ( "./images/pose_mask.jpg" )
pose_image = load_image ( './images/pose_hint.png' )
image = pipe_control ( prompt = "Face of a young boy smiling" ,
negative_prompt = "lowres, bad anatomy, worst quality, low quality" ,
controlnet_hint = pose_image ,
image = image ,
mask_image = mask ,
num_inference_steps = 100 ). images [ 0 ]
image . save ( "inpaint_pos.jpg" )


img2imgをサポートするために、pipeline_stable_diffusion_controlnet_inpaint_img2img.pyをアップロードしました。このセクションと同じ命令に従うことができます。
T2I-Adapterと同様に、ControlNetは入力として複数のコントロール画像もサポートします。ベースモデルが凍結されているため、背後にあるアイデアは簡単です。ControlNet1とControlNet2からの出力を組み合わせて、UNETへの入力として使用できます。ここでは、参照用の擬似コードを提供します。以下のようにパイプラインを変更する必要があります。
control1 = controlnet1 ( latent_model_input , t , encoder_hidden_states = prompt_embeds , controlnet_hint = controlnet_hint1 )
control2 = controlnet2 ( latent_model_input , t , encoder_hidden_states = prompt_embeds , controlnet_hint = controlnet_hint2 )
# please note that the weights should be adjusted accordingly
control1_weight = 1.00 # control_any3_openpose
control2_weight = 0.50 # control_sd15_depth
merged_control = []
for i in range ( len ( control1 )):
merged_control . append ( control1_weight * control [ i ] + control2_weight * control_1 [ i ])
control = merged_control
noise_pred = unet ( latent_model_input , t , encoder_hidden_states = prompt_embeds , cross_attention_kwargs = cross_attention_kwargs , control = control ). sample以下はマルチコントロールネットの例です。ポーズマップと深度マップを使用して、コントロールのヒントがあります。テスト画像はどちらもT2I-Adapterにクレジットされています。
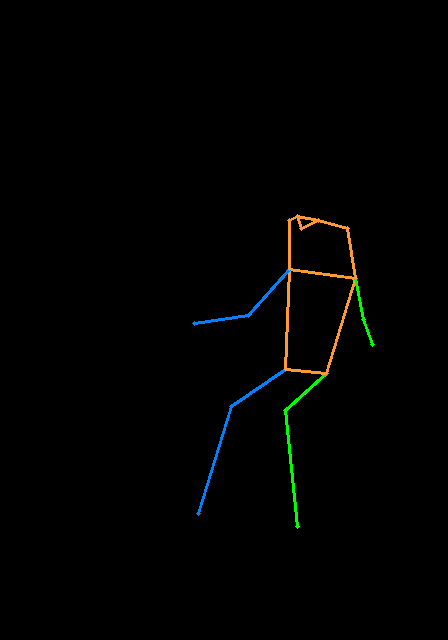


このリポジトリを回避するには、あまりにも肥大化しているため、列車制御者のトレーニングに関するチュートリアルを提供します。
まず、ControlNetの著者にこのような優れた仕事をしてくれたことに感謝します。変換コードはここから借用されています。また、Diffusersのこのプルリクエストからの貢献を紹介して、コントロールネットをディフューザーにロードできるようにします。
リポジトリはまだアクティブな開発中です。使用する際に問題がある場合は、お気軽に問題を開いてください。


