ControlNet for Diffusers
1.0.0
Ce référentiel fournit le code de didacticiel le plus simple pour les développeurs utilisant ControlNet avec BasEmodel dans le framework de diffuseur au lieu de WebUI. Notre travail se construit fortement sur d'autres excellents œuvres. Bien que ces travaux aient fait des tentatives, il n'y a pas de tutoriel pour soutenir divers ControlNet dans les diffuseurs.
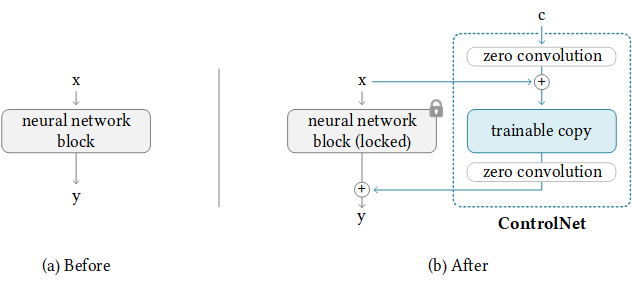
Nous avons également soutenu le T2I-adaptateur-pour-diffuseurs, Lora-for-Diffuseurs. Ne soyez pas méchant de nous donner une étoile si elle vous est utile.
Notre objectif est de remplacer le BasEmodel de ControlNet et de déduire dans le cadre des diffuseurs. Le ControlNet d'origine est formé à Pytorch_lightning, et les poids libérés avec uniquement stable-diffusion-1.5 comme BasEmodel. Cependant, il est plus flexible pour les utilisateurs d'adopter leur propre Basemodel au lieu de SD-1.5. Maintenant, prenons n'importe quoi-V3 comme exemple. Nous vous montrerons comment y parvenir (ControlNet-AnythingV3) étape par étape. Nous fournissons une démo Colab, mais cela ne fonctionne que pour les utilisateurs de Colab Pro avec un RAM plus grand.
Heureusement, ControlNet a déjà fourni une directive pour transférer le ControlNet vers tout autre modèle communautaire. La logique derrière est comme ci-dessous, où nous gardons les poids de contrôle supplémentaires et remplacez uniquement le Basemodel. Notez que cela peut ne pas fonctionner toujours, car ControlNet peut avoir des poids de trains dans BasEmodel.
NewBaseModel-ControlHint = NewBaseModel + OriginalBaseModel-ControlHint - OriginalBaseModelTout d'abord, nous clonons ce dépôt de ControlNet.
git clone https://github.com/lllyasviel/ControlNet.git
cd ControlNetEnsuite, nous devons préparer des poids requis pour OriginalBasemodel (path_sd15), OriginalBasemodel-ControlHint (path_sd15_with_control), newBasemodel (path_input). Il vous suffit de télécharger des poids suivants, et nous utilisons Pose comme ControlHint et n'importe quoi-V3 comme notre nouveau Basemodel par exemple. Nous mettons tous les poids à l'intérieur ./Models.
path_sd15 = ' ./models/v1-5-pruned.ckpt '
path_sd15_with_control = ' ./models/control_sd15_openpose.pth '
path_input = ' ./models/anything-v3-full.safetensors '
path_output = ' ./models/control_any3_openpose.pth 'Enfin, nous pouvons courir directement
python tool_transfer_control.pyEn cas de succès, vous obtiendrez le nouveau modèle. Ce modèle peut déjà être utilisé dans la base de code ControlNet.
models/control_any3_openpose.pthSi vous voulez essayer avec d'autres modèles, vous pouvez simplement définir votre propre Path_SD15_With_Control et Path_Input. Si le path_input est formé avec des diffuseurs, vous pouvez utiliser convert_diffusers_to_original_stable_diffusion.py pour le convertir en safettenseurs en premier.
Généralités, Takuma Mori l'a soutenu dans ce récent RP, afin que nous puissions facilement y parvenir. Comme il est encore sous-évlopant, il peut donc être instable, nous devons donc utiliser une version de validation spécifique. Nous remarquons que les diffuseurs ont fusionné le PR au 3/2/2023, nous reformorons bientôt notre tutoriel.
git clone https://github.com/takuma104/diffusers.git
cd diffusers
git checkout 9a37409663a53f775fa380db332d37d7ea75c915
pip install .Compte tenu du chemin du modèle généré à l'étape (1), exécutez
python ./scripts/convert_controlnet_to_diffusers.py --checkpoint_path control_any3_openpose.pth --dump_path control_any3_openpose --device cpuNous avons le modèle enregistré dans Control_Any3_OpenSpose. Nous pouvons maintenant le tester aussi régulièrement.
from diffusers import StableDiffusionControlNetPipeline
from diffusers . utils import load_image
pose_image = load_image ( 'https://huggingface.co/takuma104/controlnet_dev/resolve/main/pose.png' )
pipe = StableDiffusionControlNetPipeline . from_pretrained ( "control_any3_openpose" ). to ( "cuda" )
pipe . safety_checker = lambda images , clip_input : ( images , False )
image = pipe ( prompt = "1gril,masterpiece,graden" , controlnet_hint = pose_image ). images [ 0 ]
image . save ( "generated.png" )Le résultat généré peut ne pas être assez bon car la pose est un peu difficile. Donc, pour nous assurer que tout se passe bien, nous suggérons de générer une pose normale via le poste ou d'utiliser notre image de pose fournie dans ./images/pose.png.
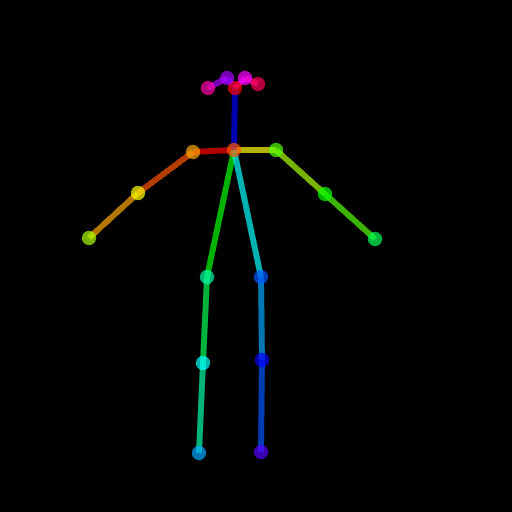

Il s'agit de prendre en charge ControlNet avec la possibilité de modifier uniquement une région cible au lieu d'une image complète comme l'intégralité de diffusion stable. Pour l'instant, nous fournissons la condition (pose, carte de segmentation) au préalable, mais vous pouvez utiliser adopter le détecteur pré-formé utilisé dans ControlNet.
Nous avons fourni le pipeline requis pour l'utilisation. Mais veuillez noter que ce fichier est fragile sans test complet, nous considérerons le prendre en charge dans le cadre DIFFUSERS FIRMALLEMENT plus tard. De plus, nous constatons que ControlNet (basé sur SD1.5) n'est pas compatible avec l'intérêt stable-diffusion-2, car certaines couches ont des modules et une dimension différents, si vous chargez de force les poids et sautez ces couches inégalées, le résultat sera mauvais
# assume you already know the absolute path of installed diffusers
cp pipeline_stable_diffusion_controlnet_inpaint.py PATH/pipelines/stable_diffusionEnsuite, vous devez importer ce nouveau pipeline ajouté dans des fichiers correspondants
PATH/pipelines/__init__.py
PATH/__init__.py
Maintenant, nous pouvons courir
import torch
from diffusers . utils import load_image
from diffusers import StableDiffusionInpaintPipeline , StableDiffusionControlNetInpaintPipeline
# we have downloaded models locally, you can also load from huggingface
# control_sd15_seg is converted from control_sd15_seg.safetensors using instructions above
pipe_control = StableDiffusionControlNetInpaintPipeline . from_pretrained ( "./diffusers/control_sd15_seg" , torch_dtype = torch . float16 ). to ( 'cuda' )
pipe_inpaint = StableDiffusionInpaintPipeline . from_pretrained ( "./diffusers/stable-diffusion-inpainting" , torch_dtype = torch . float16 ). to ( 'cuda' )
# yes, we can directly replace the UNet
pipe_control . unet = pipe_inpaint . unet
pipe_control . unet . in_channels = 4
# we also the same example as stable-diffusion-inpainting
image = load_image ( "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png" )
mask = load_image ( "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png" )
# the segmentation result is generated from https://huggingface.co/spaces/hysts/ControlNet
control_image = load_image ( 'tmptvkkr0tg.png' )
image = pipe_control ( prompt = "Face of a yellow cat, high resolution, sitting on a park bench" ,
negative_prompt = "lowres, bad anatomy, worst quality, low quality" ,
controlnet_hint = control_image ,
image = image ,
mask_image = mask ,
num_inference_steps = 100 ). images [ 0 ]
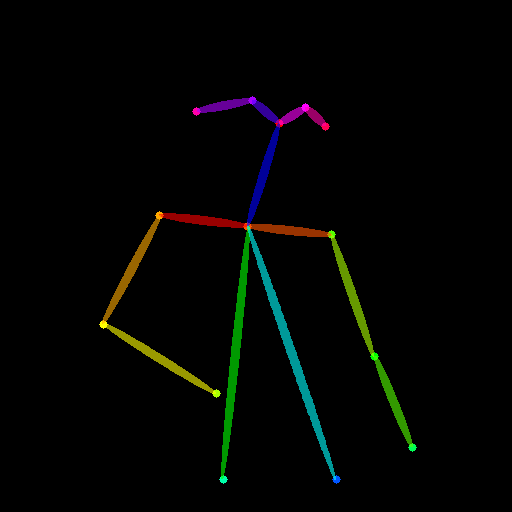
image . save ( "inpaint_seg.jpg" )Les images suivantes sont une image originale, une image de masque, une segmentation (indice de contrôle) et une nouvelle image générée.


Vous pouvez également utiliser la pose comme indice de contrôle. Mais veuillez noter qu'il est suggéré d'utiliser le format OpenPose, qui est cohérent pour le processus de formation. Si vous souhaitez simplement tester quelques images sans installer OpenPose localement, vous pouvez utiliser directement la démo en ligne de ControlNet pour générer une image de pose compte tenu de l'entrée 512x512 redimensionnée.
image = load_image ( "./images/pose_image.jpg" )
mask = load_image ( "./images/pose_mask.jpg" )
pose_image = load_image ( './images/pose_hint.png' )
image = pipe_control ( prompt = "Face of a young boy smiling" ,
negative_prompt = "lowres, bad anatomy, worst quality, low quality" ,
controlnet_hint = pose_image ,
image = image ,
mask_image = mask ,
num_inference_steps = 100 ). images [ 0 ]
image . save ( "inpaint_pos.jpg" )


Nous avons téléchargé pipeline_stable_diffusion_controlnet_inpaint_img2img.py pour prendre en charge img2img. Vous pouvez suivre la même instruction que cette section.
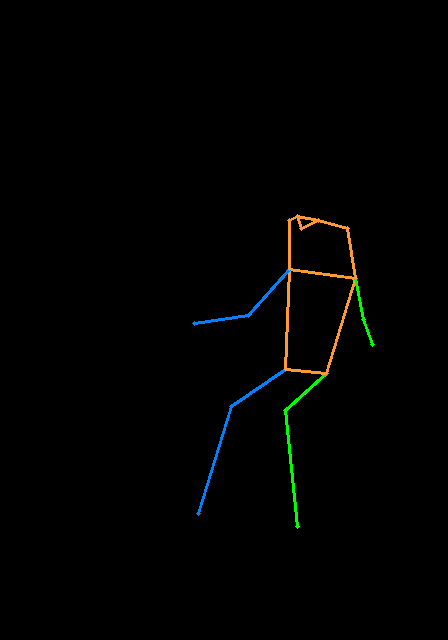
Semblable à T2I-Adapter, ControlNet prend également en charge plusieurs images de contrôle en entrée. L'idée derrière est simple, car le modèle de base est gelé, nous pouvons combiner les sorties de ControlNet1 et ControlNet2, et l'utiliser comme entrée à UNET. Ici, nous fournissons un pseudocode pour référence. Vous devez modifier le pipeline comme ci-dessous.
control1 = controlnet1 ( latent_model_input , t , encoder_hidden_states = prompt_embeds , controlnet_hint = controlnet_hint1 )
control2 = controlnet2 ( latent_model_input , t , encoder_hidden_states = prompt_embeds , controlnet_hint = controlnet_hint2 )
# please note that the weights should be adjusted accordingly
control1_weight = 1.00 # control_any3_openpose
control2_weight = 0.50 # control_sd15_depth
merged_control = []
for i in range ( len ( control1 )):
merged_control . append ( control1_weight * control [ i ] + control2_weight * control_1 [ i ])
control = merged_control
noise_pred = unet ( latent_model_input , t , encoder_hidden_states = prompt_embeds , cross_attention_kwargs = cross_attention_kwargs , control = control ). sampleVoici un exemple de multi-contrôlet, où nous utilisons la pose et la carte de profondeur sont des conseils de contrôle. Les images de test sont toutes deux créditées à T2I-Adapter.


Afin d'éviter que ce dépôt soit trop gonflé, nous fournissons un tutoriel sur la formation dans le train-contrôle en diffuseurs.
Nous remercions d'abord l'auteur de ControlNet pour un si bon travail, notre code de conversion est emprunté à partir d'ici. Nous sommes également appréciés les contributions de cette demande de traction dans les diffuseurs, afin que nous puissions charger ControlNet en diffuseurs.
Le repo est toujours en cours de développement actif, si vous avez un problème lorsque vous l'utilisez, n'hésitez pas à ouvrir un problème.


