densenet.pytorch
1.0.0
Это реализация архитектуры Densenet-BC Pytorch, как описано в бумаге, плотно связанных сверточных сетях Г. Хуангом, З. Лю, К. Вайнбергером и Л. Ван дер Маатен. Эта реализация получает частоту ошибок CIFAR-10+ 4,77 с 100-слойным Densenet-BC с темпами роста 12. Их официальная реализация и ссылки со многими другими сторонними реализациями доступны в репо Liuzhuang13/Densenet на Github.

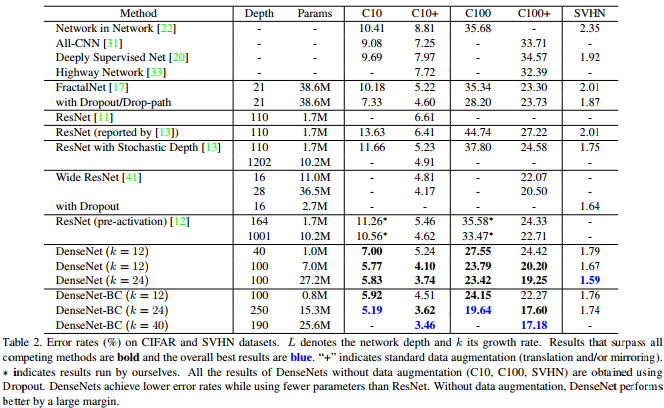
Как показывает эта таблица из Densenet Paper, она обеспечивает конкурентоспособные результаты искусства на CIFAR-10, CIFAR-100 и SVHN.
Pytorch-это отличная новая структура, и приятно иметь такие переосмысления, чтобы их можно было интегрировать с другими проектами Pytorch.
Интересно, что, реализуя это, у меня было много проблем с тем, чтобы он сходился и посмотрел на каждую часть кода ближе, чем обычно. Я сравнил все скрытые состояния и градиенты модели с официальной реализацией, чтобы убедиться, что мой код был правильным, и даже обучил сеть в стиле VGG на CIFAR-10 с кодом обучения здесь. Оказывается, я обнаружил новую критическую ошибку Pytorch (сейчас фиксированная), которая вызывала это.
Я оставил свое первоначальное сообщение о том, как это не работает, и о том, что я проверил в этом документе. Я думаю, что это должно быть интересно для других людей, чтобы увидеть мои стратегии развития и отладки, когда возникают проблемы, внедряющие модель, которая, как известно, сходится. Я также начал эту ветку форума Pytorch, в которой есть несколько других точек обсуждения. Вы также можете быть заинтересованы в моем сценарии, который сравнивает градиенты Pytorch с градиентами факелов и мой сценарий, который численно проверяет градиенты Pytorch.
Мои проблемы с конвергенцией были связаны с критической ошибкой Pytorch, связанной с использованием torch.cat с свержениями с включенной Cudnn (что по умолчанию используется при использовании CUDA). Эта ошибка вызвала неверные градиенты, и исправление к этой ошибке состоит в том, чтобы отключить cudnn (который больше не должен быть сделан, потому что она фиксирована). Наблюдение за моими стратегиями отладки, которое заставило меня не найти эту ошибку, заключается в том, что я не думал отключить Cudnn. До сих пор я предполагал, что опция Cudnn в фреймворках не имеет ошибок, но узнал, что это не всегда так. Возможно, я также нашел что -то, если бы я был численно отлаживать слои torch.cat с свержениями вместо полностью подключенных слоев.
Адам исправил ошибку Pytorch, которая вызвала это в этом PR и был объединен в главную ветвь Torch. Если вы заинтересованы в использовании кода Densenet в этом репозитории, убедитесь, что ваша версия Pytorch содержит этот PR и была загружена после 2017-02-10.
Вы можете увидеть здесь вычислительный график, который я создал с помощью make_graph.py, который я скопировал из сустава Адама Пашке. Адам говорит, что у Pytorch скоро будет лучший способ создать вычислительные графики.
По умолчанию это Repo обучает 100-слойного Densenet-BC с скоростью роста 12 на наборе данных CIFAR-10 с увеличением данных. Из -за размеров памяти графических процессоров это самая большая модель, которую я могу запустить. В статье сообщается о окончательной ошибке тестирования 4.51 с этой архитектурой, и мы получаем окончательную ошибку теста 4.77.
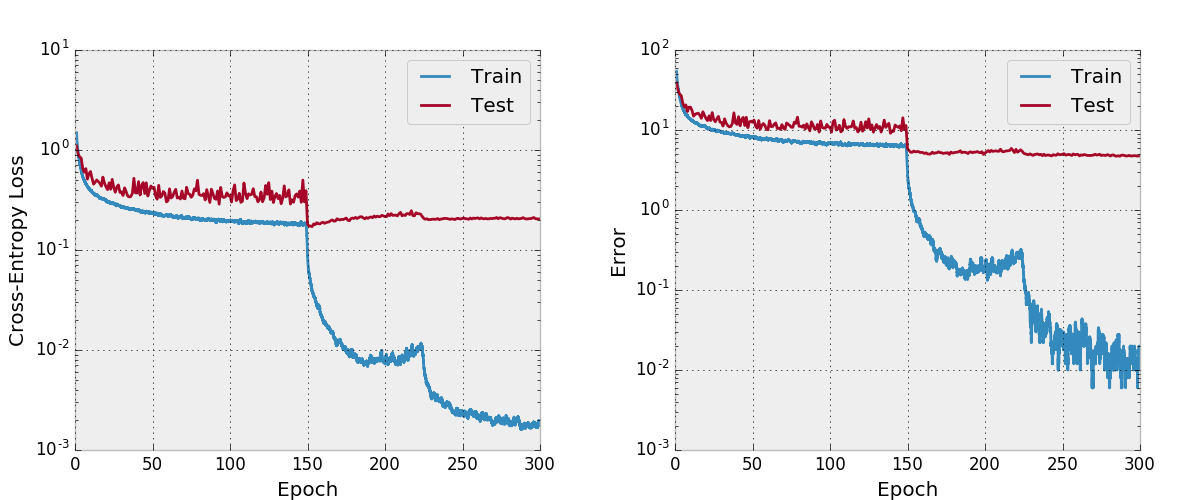
Я также попытался обучать сеть с Адамом и обнаружил, что она не сходилась и с гиперпараметрами по умолчанию по сравнению с SGD с разумным графиком обучения.
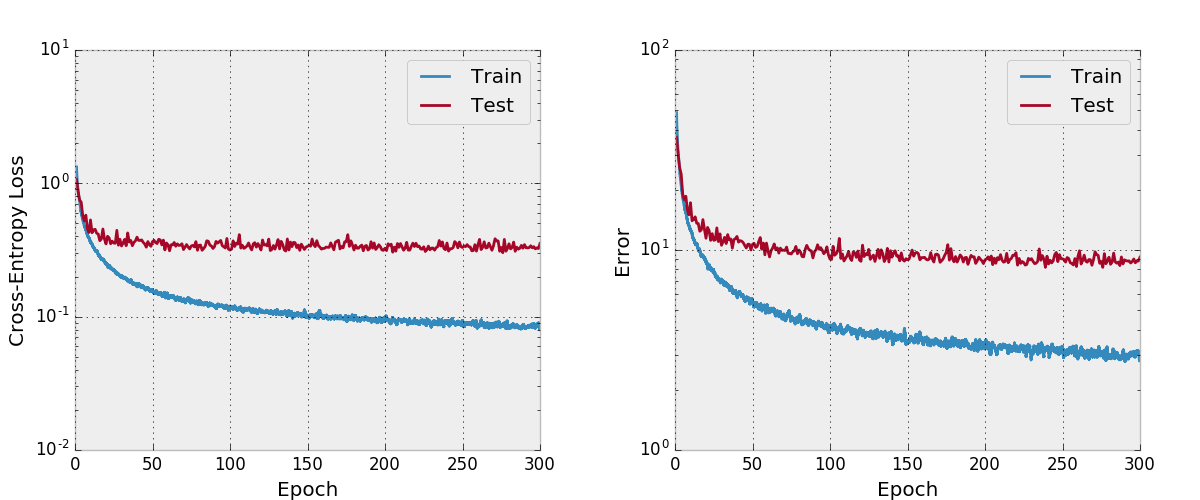
Я не тестировал это как тщательно, вы должны убедиться, что он работает, как и ожидалось, если вы планируете использовать и изменить его. Дайте мне знать, если вы найдете что -то не так с этим.
Мне нравится включать несколько функций в мои проекты, которых я не вижу в некоторых других повторных внедрения, которые присутствуют в этом репо. Учебный код в train.py использует argparse , поэтому размер пакета и некоторые другие гиперпарам можно легко изменить, и, поскольку модель обучается, прогресс записывается в файлы CSV в рабочем каталоге, также определяемый аргументами. Затем отдельный plot.py . Обучение сценария вызывает plot.py
Я думаю, что есть способы улучшить использование памяти в этом коде, как в официальной реализации космического факела. Я также был бы заинтересован в поддержке мульти-GPU.
Сначала установите Pytorch (в идеале в распределение Anaconda3). ./train.py создаст модель, начнет обучать ее и сохранить прогресс до args.save , который является work/cifar10.base по умолчанию. Сценарий обучения будет вызовом stump.py после каждой эпохи, чтобы создать сюжеты из сохраненного прогресса.
Ниже приведена запись Bibtex для Densenet Paper, которую вы должны цитировать, если вы используете эту модель.
@article{Huang2016Densely,
author = {Huang, Gao and Liu, Zhuang and Weinberger, Kilian Q.},
title = {Densely Connected Convolutional Networks},
journal = {arXiv preprint arXiv:1608.06993},
year = {2016}
}
Если вы используете эту реализацию, также рассмотрите возможность ссылки на эту реализацию и репозиторий кода со следующей записью Bibtex или Plaintext. Запись Bibtex требует пакета LaTex url .
@misc{amos2017densenet,
title = {{A PyTorch Implementation of DenseNet}},
author = {Amos, Brandon and Kolter, J. Zico},
howpublished = {url{https://github.com/bamos/densenet.pytorch}},
note = {Accessed: [Insert date here]}
}
Brandon Amos, J. Zico Kolter
A PyTorch Implementation of DenseNet
https://github.com/bamos/densenet.pytorch.
Accessed: [Insert date here]
Этот репозиторий лицензирован Apache.


