densenet.pytorch
1.0.0
Il s'agit d'une implémentation Pytorch de l'architecture densenet-BC comme décrit dans les réseaux convolutionnels densément connectés de papier par G. Huang, Z. Liu, K. Weinberger et L. van der Maaten. Cette implémentation obtient un taux d'erreur CIFAR-10 + de 4,77 avec un denset-BC de 100 couches avec un taux de croissance de 12. Leur implémentation officielle et les liens vers de nombreuses autres implémentations tierces sont disponibles dans le repo Liuzhuang13 / densenet sur Github.

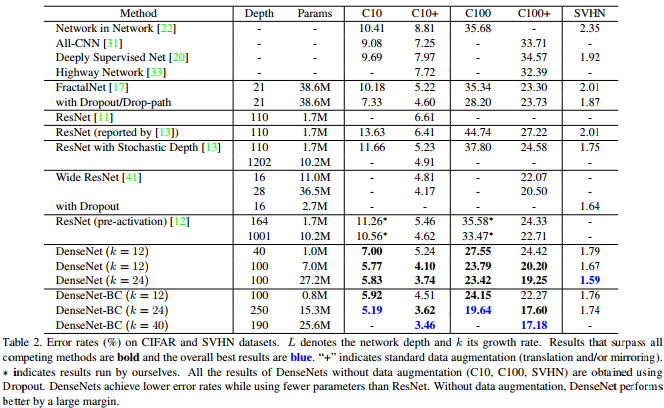
Comme le montre ce tableau du papier densenet, il fournit des résultats de pointe compétitifs sur CIFAR-10, CIFAR-100 et SVHN.
Pytorch est un excellent nouveau cadre et il est agréable d'avoir ce genre de réimplémentations pour qu'ils puissent être intégrés à d'autres projets Pytorch.
Fait intéressant, lors de la mise en œuvre de cela, j'ai eu beaucoup de mal à le converger et j'ai regardé chaque partie du code plus proche que d'habitude. J'ai comparé tous les états et gradients cachés du modèle avec l'implémentation officielle pour m'assurer que mon code était correct et a même formé un réseau de style VGG sur CIFAR-10 avec le code de formation ici. Il s'avère que j'ai découvert un nouveau pytorch critique critique (maintenant corrigé) qui provoquait cela.
J'ai laissé mon message d'origine sur la façon dont cela ne fonctionne pas et les choses que j'ai vérifiées dans ce document. Je pense que cela devrait être intéressant pour d'autres personnes de voir mes stratégies de développement et de débogage lors de la mise en œuvre de problèmes d'un modèle connu pour converger. J'ai également commencé ce fil de forum Pytorch, qui a quelques autres points de discussion. Vous pouvez également être intéressé par mon script qui compare les gradients Pytorch aux gradients de torche et mon script qui vérifie numériquement les gradients Pytorch.
Mes problèmes de convergence étaient dus à un bogue pytorch critique lié à l'utilisation torch.cat avec des convolutions avec CUDNN activées (ce qui est par défaut lorsque Cuda est utilisé). Ce bogue a provoqué des gradients incorrects et la correction de ce bogue est de désactiver CUDNN (ce qui n'a plus à être fait car il est corrigé). La surveillance de mes stratégies de débogage qui m'ont amené à ne pas trouver cette erreur est que je n'ai pas pensé à désactiver CUDNN. Jusqu'à présent, j'ai supposé que l'option CUDNN dans les cadres est sans bug, mais j'ai appris que ce n'est pas toujours le cas. J'ai peut-être aussi trouvé quelque chose si j'avais des couches de torch.cat à débogage numériquement avec des couches avec des couches entièrement connectées.
Adam a corrigé le bug de Pytorch qui a provoqué cela dans ce RP et a été fusionné dans la branche maîtresse de Torch. Si vous êtes intéressé à utiliser le code Densenet dans ce référentiel, assurez-vous que votre version Pytorch contient ce PR et a été téléchargé après 2017-02-10.
Vous pouvez voir le graphique de calcul ici, que j'ai créé avec Make_graph.py, que j'ai copié à partir de l'essentiel d'Adam Paszke. Adam dit que Pytorch aura bientôt une meilleure façon de créer des graphiques de calcul.
Par défaut, ce repo forme un denset-BC de 100 couches avec un taux de croissance de 12 sur l'ensemble de données CIFAR-10 avec des augmentations de données. En raison des tailles de mémoire GPU, il s'agit du plus grand modèle que je puisse exécuter. L'article rapporte une erreur de test finale de 4,51 avec cette architecture et nous obtenons une erreur de test finale de 4,77.
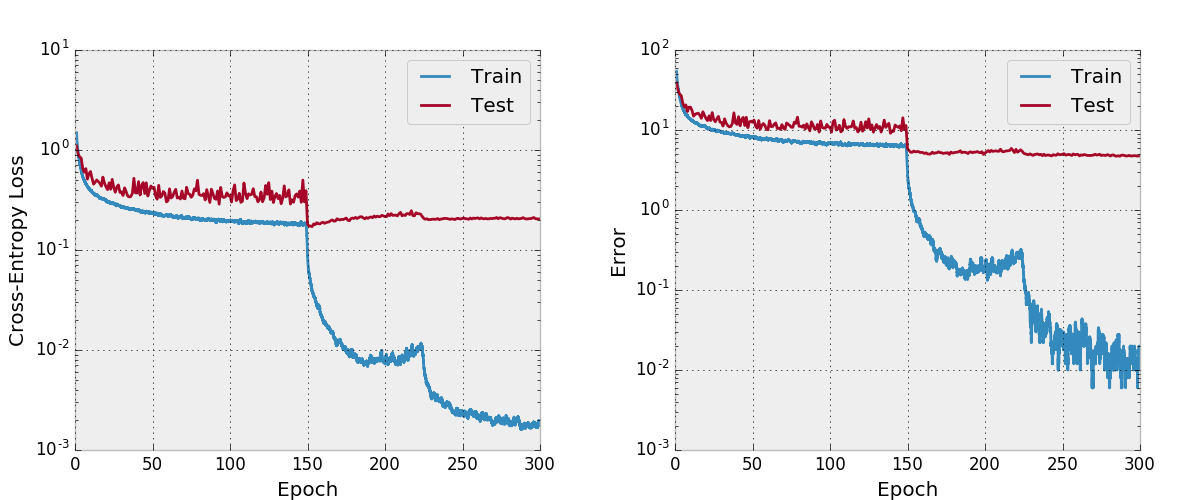
J'ai également essayé de former un filet avec Adam et j'ai constaté qu'il ne converge pas aussi avec les hyper-paramètres par défaut par rapport à SGD avec un calendrier de taux d'apprentissage raisonnable.
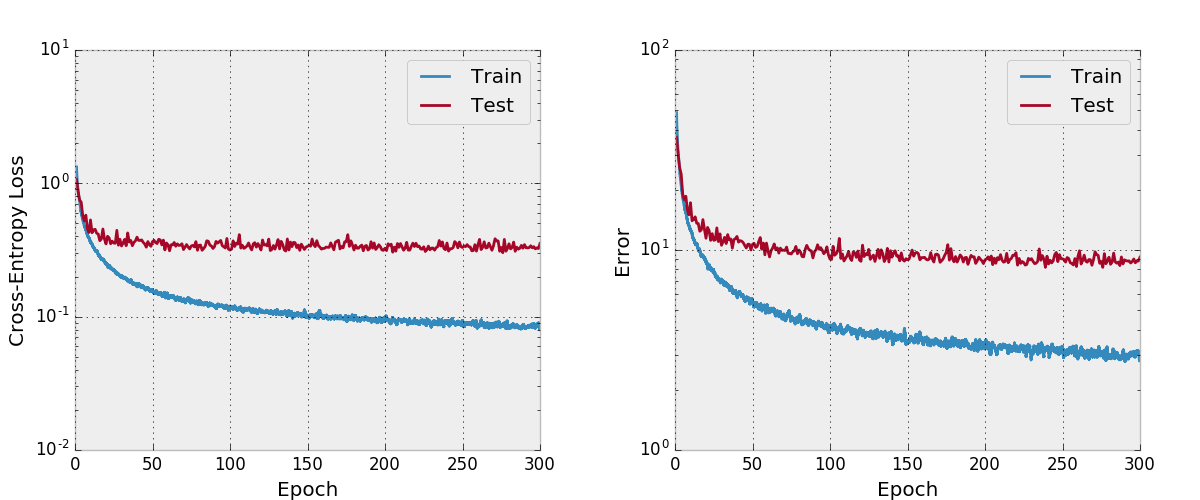
Je n'ai pas testé cela aussi soigneusement, vous devez vous assurer que cela fonctionne comme prévu si vous prévoyez de l'utiliser et de le modifier. Faites-moi savoir si vous trouvez quelque chose de mal à cela.
J'aime inclure quelques fonctionnalités dans mes projets que je ne vois pas dans d'autres réimplémentations qui sont présentes dans ce repo. Le code de formation à train.py utilise argparse afin que la taille du lot et certains autres hyper-parammes puissent facilement être modifiés et comme le modèle est une formation, les progrès sont écrits dans les fichiers CSV dans un répertoire de travail également défini par les arguments. Ensuite, un script séparé plot.py trace les progrès écrits par le script d'entraînement. Le script d'entraînement appelle plot.py après chaque époque, mais il peut être exécuté de manière importante pour que les chiffres puissent être modifiés sans relancer toute l'expérience.
Je pense qu'il existe des moyens d'améliorer l'utilisation de la mémoire dans ce code comme dans l'implémentation officielle de la torche économe en espace. Je serais également intéressé par le support multi-GPU.
Installez d'abord Pytorch (idéalement dans une distribution Anaconda3). ./train.py créera un modèle, commencera à le former et à enregistrer les progrès vers args.save , qui est work/cifar10.base par défaut. Le script de formation appellera Plot.Py après chaque époque pour créer des parcelles à partir des progrès enregistrés.
Ce qui suit est une entrée bibtex pour le papier denset que vous devez citer si vous utilisez ce modèle.
@article{Huang2016Densely,
author = {Huang, Gao and Liu, Zhuang and Weinberger, Kilian Q.},
title = {Densely Connected Convolutional Networks},
journal = {arXiv preprint arXiv:1608.06993},
year = {2016}
}
Si vous utilisez cette implémentation, veuillez également envisager de citer ce référentiel d'implémentation et de code avec le bibtex suivant ou l'entrée en texte clair. L'entrée Bibtex nécessite le package de latex url .
@misc{amos2017densenet,
title = {{A PyTorch Implementation of DenseNet}},
author = {Amos, Brandon and Kolter, J. Zico},
howpublished = {url{https://github.com/bamos/densenet.pytorch}},
note = {Accessed: [Insert date here]}
}
Brandon Amos, J. Zico Kolter
A PyTorch Implementation of DenseNet
https://github.com/bamos/densenet.pytorch.
Accessed: [Insert date here]
Ce référentiel est autorisé à Apache.


