densenet.pytorch
1.0.0
Ini adalah implementasi Pytorch dari arsitektur Densenet-BC seperti yang dijelaskan dalam kertas yang terhubung dengan jaringan konvolusional yang terhubung oleh G. Huang, Z. Liu, K. Weinberger, dan L. van der Maaten. Implementasi ini mendapatkan tingkat kesalahan CIFAR-10+ 4,77 dengan Densenet-BC 100-layer dengan tingkat pertumbuhan 12. Implementasi resmi mereka dan tautan ke banyak impo pihak ketiga lainnya tersedia di Liuzhuang13/Densenet Repo di Github.

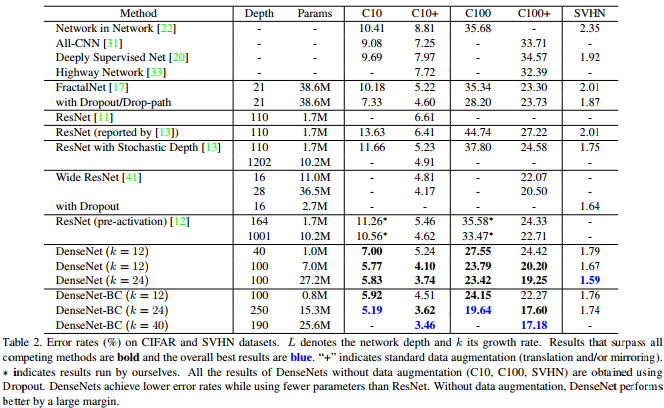
Seperti yang ditunjukkan tabel dari kertas Densenet ini, ini memberikan hasil yang kompetitif dari hasil seni pada CIFAR-10, CIFAR-100, dan SVHN.
Pytorch adalah kerangka kerja baru yang hebat dan senang memiliki implementasi ulang semacam ini sehingga mereka dapat diintegrasikan dengan proyek Pytorch lainnya.
Menariknya saat menerapkan ini, saya mengalami banyak kesulitan untuk menyatu dan melihat setiap bagian dari kode lebih dekat dari biasanya. Saya membandingkan semua status tersembunyi model dan gradien dengan implementasi resmi untuk memastikan kode saya benar dan bahkan melatih jaringan gaya VGG di CIFAR-10 dengan kode pelatihan di sini. Ternyata saya menemukan bug Pytorch kritis baru (sekarang diperbaiki) yang menyebabkan ini.
Saya telah meninggalkan pesan asli saya tentang bagaimana ini tidak berfungsi dan hal -hal yang telah saya periksa dalam dokumen ini. Saya pikir ini harus menarik bagi orang lain untuk melihat strategi pengembangan dan debugging saya ketika mengalami masalah menerapkan model yang diketahui bertemu. Saya juga memulai utas forum Pytorch ini, yang memiliki beberapa poin diskusi lainnya. Anda mungkin juga tertarik pada skrip saya yang membandingkan gradien pytorch dengan gradien obor dan skrip saya yang secara numerik memeriksa gradien Pytorch.
Masalah konvergensi saya adalah karena bug Pytorch yang kritis terkait dengan penggunaan torch.cat dengan konvolusi dengan CUDNN diaktifkan (yang secara default ketika CUDA digunakan). Bug ini menyebabkan gradien yang salah dan perbaikan pada bug ini adalah menonaktifkan Cudnn (yang tidak harus dilakukan lagi karena sudah diperbaiki). Pengawasan dalam strategi debugging saya yang menyebabkan saya tidak menemukan kesalahan ini adalah bahwa saya tidak berpikir untuk menonaktifkan Cudnn. Sampai sekarang, saya berasumsi bahwa opsi Cudnn dalam kerangka kerja bebas bug, tetapi telah belajar bahwa ini tidak selalu terjadi. Saya mungkin juga menemukan sesuatu jika saya memiliki lapisan torch.cat yang debugal numerik dengan konvolusi alih -alih lapisan yang sepenuhnya terhubung.
Adam memperbaiki bug Pytorch yang menyebabkan hal ini di PR ini dan telah digabungkan menjadi cabang utama Torch. Jika Anda tertarik menggunakan kode Densenet di repositori ini, pastikan versi Pytorch Anda berisi PR ini dan diunduh setelah 2017-02-10.
Anda dapat melihat grafik komputasi di sini, yang saya buat dengan make_graph.py, yang saya salin dari intisari Adam Paszke. Adam mengatakan Pytorch akan segera memiliki cara yang lebih baik untuk membuat grafik komputasi.
Secara default, repo ini melatih Densenet-BC 100-layer dengan tingkat pertumbuhan 12 pada dataset CIFAR-10 dengan augmentasi data. Karena ukuran memori GPU, ini adalah model terbesar yang dapat saya jalankan. Makalah ini melaporkan kesalahan uji akhir 4,51 dengan arsitektur ini dan kami mendapatkan kesalahan uji akhir 4,77.
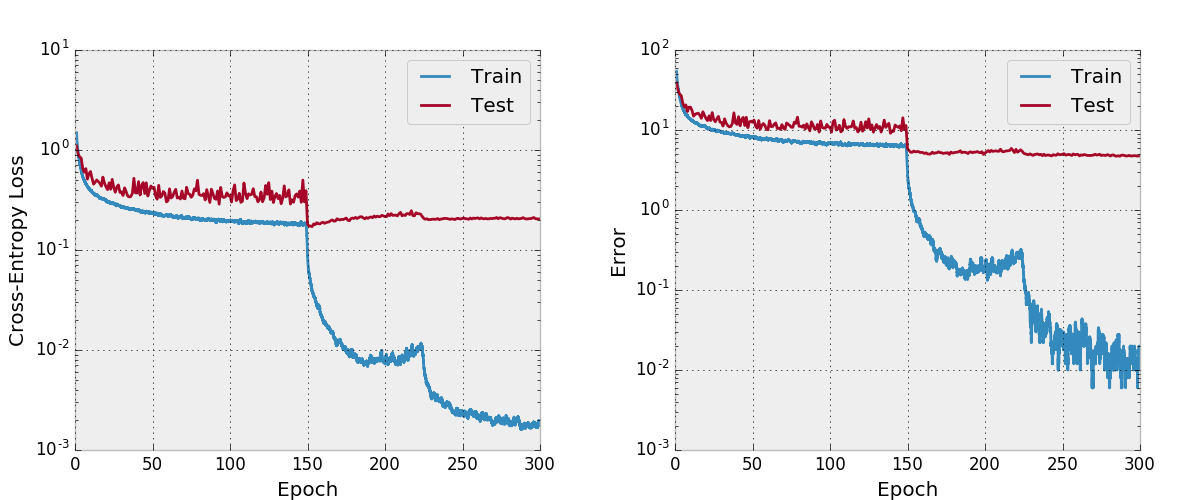
Saya juga mencoba melatih jaring dengan Adam dan menemukan bahwa itu tidak berkumpul juga dengan hyper-parameter default dibandingkan dengan SGD dengan jadwal tingkat pembelajaran yang masuk akal.
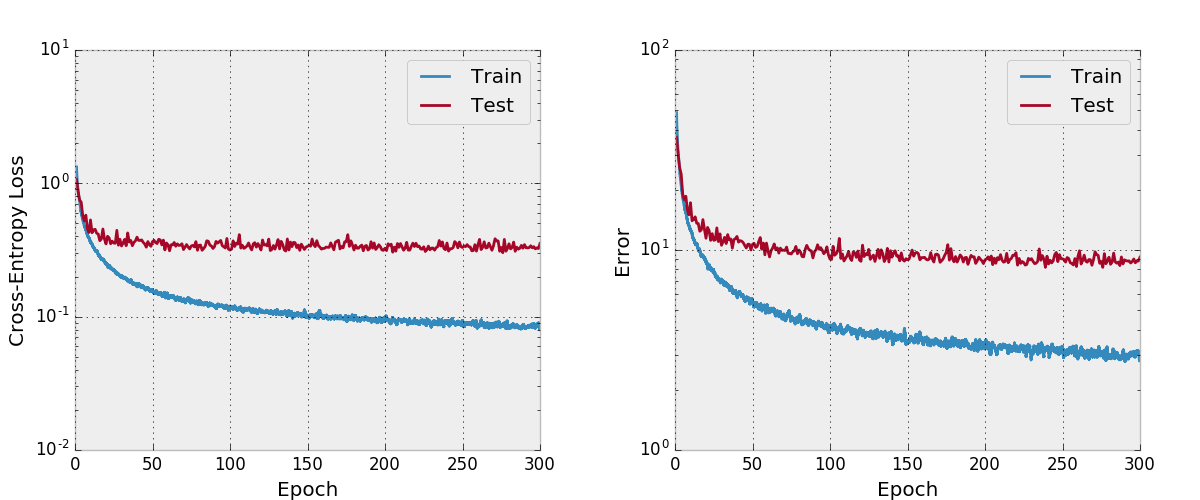
Saya belum menguji ini secara menyeluruh, Anda harus memastikan itu berfungsi seperti yang diharapkan jika Anda berencana untuk menggunakan dan memodifikasinya. Beri tahu saya jika Anda menemukan sesuatu yang salah dengannya.
Saya suka memasukkan beberapa fitur dalam proyek saya yang tidak saya lihat dalam beberapa implementasi ulang lain yang ada dalam repo ini. Kode pelatihan di train.py menggunakan argparse sehingga ukuran batch dan beberapa hiper-param lainnya dapat dengan mudah diubah dan karena modelnya pelatihan, kemajuan ditulis ke file CSV dalam direktori kerja yang juga ditentukan oleh argumen. Kemudian skrip terpisah plot.py plot kemajuan yang ditulis oleh skrip pelatihan. Script pelatihan menyebut plot.py setelah setiap zaman, tetapi yang secara penting dapat dijalankan dengan sendirinya sehingga angka-angka dapat di-tweak tanpa menjalankan kembali seluruh percobaan.
Saya pikir ada cara untuk meningkatkan pemanfaatan memori dalam kode ini seperti pada implementasi obor yang efisien ruang-ruang. Saya juga akan tertarik dengan dukungan multi-GPU.
Pertama -tama pasang pytorch (idealnya dalam distribusi Anaconda3). ./train.py akan membuat model, mulai melatihnya, dan menyimpan kemajuan ke args.save , yaitu work/cifar10.base secara default. Script pelatihan akan memanggil plot.py setelah setiap zaman untuk membuat plot dari kemajuan yang disimpan.
Berikut ini adalah entri Bibtex untuk kertas Densenet yang harus Anda kutip jika Anda menggunakan model ini.
@article{Huang2016Densely,
author = {Huang, Gao and Liu, Zhuang and Weinberger, Kilian Q.},
title = {Densely Connected Convolutional Networks},
journal = {arXiv preprint arXiv:1608.06993},
year = {2016}
}
Jika Anda menggunakan implementasi ini, harap juga pertimbangkan mengutip implementasi ini dan repositori kode dengan entri BIBTEX atau Plaintext berikut. Entri Bibtex membutuhkan paket lateks url .
@misc{amos2017densenet,
title = {{A PyTorch Implementation of DenseNet}},
author = {Amos, Brandon and Kolter, J. Zico},
howpublished = {url{https://github.com/bamos/densenet.pytorch}},
note = {Accessed: [Insert date here]}
}
Brandon Amos, J. Zico Kolter
A PyTorch Implementation of DenseNet
https://github.com/bamos/densenet.pytorch.
Accessed: [Insert date here]
Repositori ini dilisensikan Apache.


