densenet.pytorch
1.0.0
これは、G。huang、Z。Liu、K。Weinberger、およびL. van der Maatenによる密に接続された畳み込みネットワークで説明されているように、デンセンBCアーキテクチャのPytorch実装です。この実装では、100層のデンゼンセネットBCを備えたCIFAR-10+エラー率が4.77で、成長率は12です。他の多くのサードパーティ実装への公式実装とリンクは、GitHubのLiuzhuang13/Densenet Repoで利用できます。

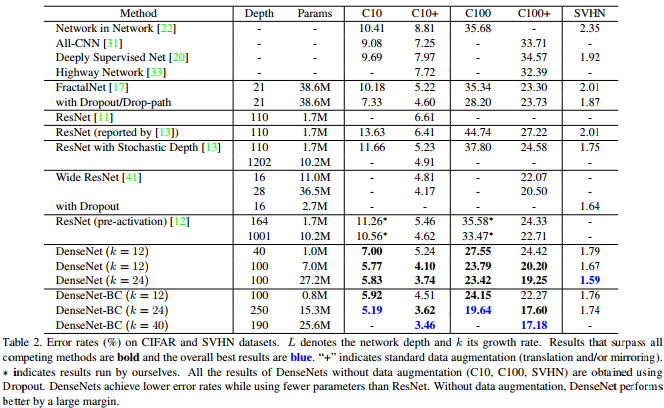
Densenet Paperのこの表が示すように、CIFAR-10、CIFAR-100、およびSVHNで競争力のある最先端の結果を提供します。
Pytorchは素晴らしい新しいフレームワークであり、他のPytorchプロジェクトと統合できるように、これらの種類の再実装をお楽しみいただけます。
興味深いことに、これを実装している間、私はそれを収束させて、コードのすべての部分を通常よりも近づけていることに多くの苦労をしました。モデルのすべての非表示状態と勾配を公式の実装と比較して、コードが正しいことを確認し、ここでトレーニングコードを使用してCIFAR-10のVGGスタイルのネットワークをトレーニングしました。これを引き起こしている新しい重要なPytorchバグ(現在固定)を発見したことがわかりました。
私は、これがどのように機能していないか、そして私がこのドキュメントでチェックしたものについて、私の元のメッセージを残しました。これは、収束することが知られているモデルの実装に問題があるときに、他の人が私の開発とデバッグ戦略を見るのは興味深いはずだと思います。また、このPytorchフォーラムスレッドも開始しました。これには、他にもいくつかの議論ポイントがあります。また、Pytorch勾配をトーチグラデーションと比較する私のスクリプトや、Pytorch勾配を数値的にチェックするスクリプトを比較する私のスクリプトにも興味があるかもしれません。
私の収束の問題は、CUDNNが有効になっている畳み込みを使用してtorch.cat使用することに関連する重要なPytorchバグによるものでした(CUDAが使用される場合はデフォルトではありません)。このバグは誤った勾配を引き起こし、このバグの修正はCudnnを無効にすることです(これは、修正されているため、もう実行する必要はありません)。私がこのエラーを見つけられなかった私のデバッグ戦略の監視は、Cudnnを無効にするとは考えていなかったということです。これまで、私はフレームワークのcudnnオプションはバグがないと想定していましたが、これが必ずしもそうではないことを学びました。また、完全に接続されたレイヤーの代わりに畳み込みを備えたtorch.catレイヤーを数値的にデバッグした場合、何かを見つけたかもしれません。
アダムは、このPRでこれを引き起こしたPytorchのバグを修正し、Torchのマスターブランチに統合されました。このリポジトリでDensenetコードを使用することに興味がある場合は、PytorchバージョンにこのPRが含まれており、2017-02-10以降にダウンロードされたことを確認してください。
ここでは、Adam Paszkeの要点からコピーしたmake_graph.pyで作成したComputeグラフを見ることができます。 Adamは、Pytorchが間もなく計算グラフを作成するためのより良い方法があると言います。
デフォルトでは、このレポは、データ増強を備えたCIFAR-10データセットで成長率が12の100層デンセンBCを訓練します。 GPUメモリサイズのため、これは私が実行できる最大のモデルです。このアーキテクチャを使用して、このアーキテクチャを使用して4.51の最終テストエラーを報告し、4.77の最終テストエラーを取得します。
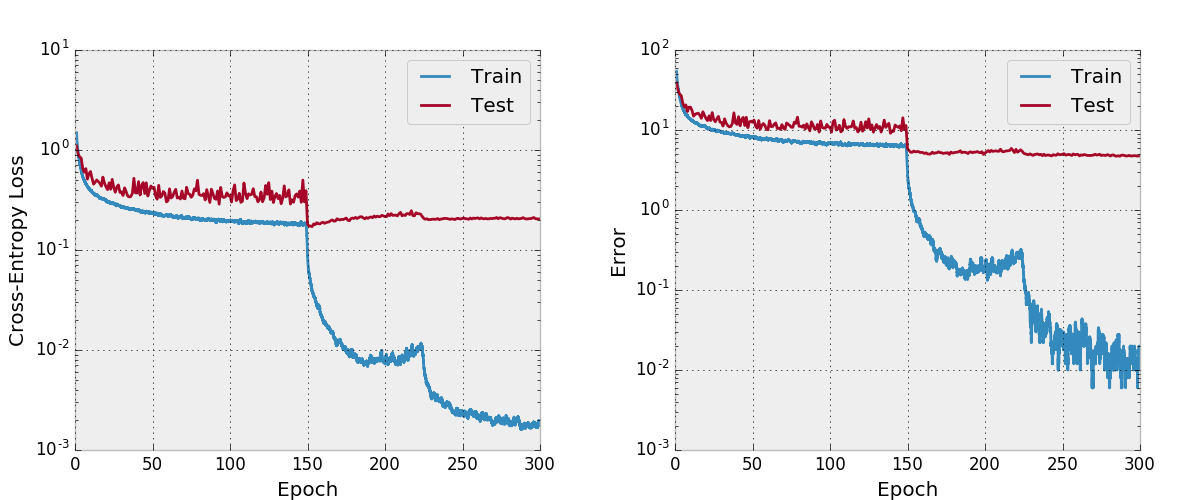
また、Adamとネットをトレーニングしようとしましたが、妥当な学習率のスケジュールを持つSGDと比較して、デフォルトのハイパーパラメーターと同様に収束していないことがわかりました。
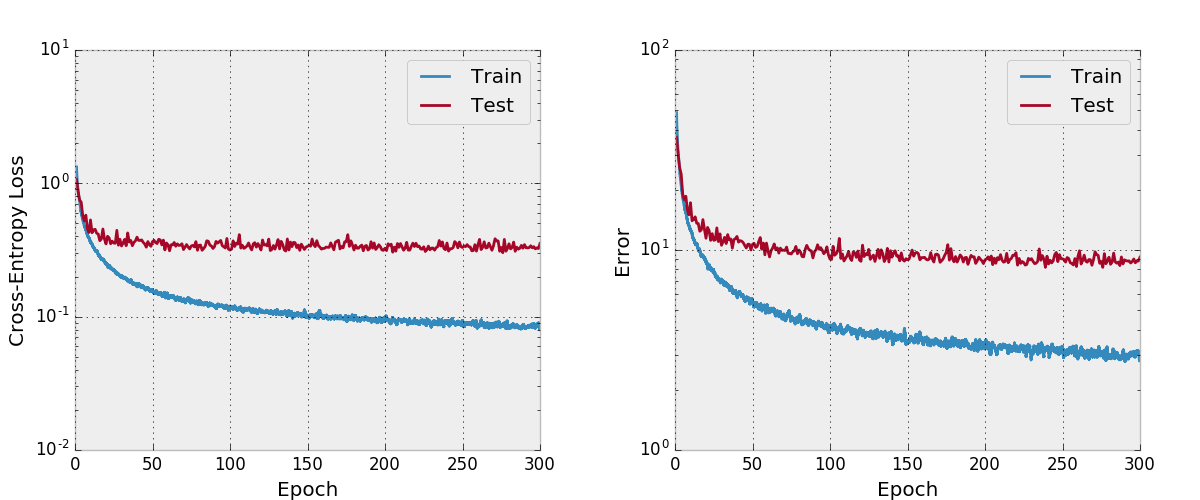
私はこれを徹底的にテストしていません。使用して変更する予定がある場合は、予想どおりに機能していることを確認する必要があります。あなたがそれで何か問題があるとわかったら私に知らせてください。
私はプロジェクトにいくつかの機能を、このレポに存在する他の再実装には見られないいくつかの機能を含めるのが好きです。 train.pyのトレーニングコードはargparseを使用するため、バッチサイズとその他のハイパーパラムを簡単に変更でき、モデルがトレーニングを行っているため、議論によって定義されたワークディレクトリのCSVファイルに進捗状況が書き込まれます。次に、個別のスクリプトplot.pyトレーニングスクリプトによって作成された進捗をプロットします。トレーニングスクリプトはエポックごとにplot.pyを呼び出しますが、重要なことには、実験全体を再実行することなく微調整できます。
公式の空間効率の良いトーチの実装のように、このコードのメモリの利用を改善する方法があると思います。また、マルチGPUサポートにも興味があります。
最初にPytorch(理想的にはAnaconda3分布に)をインストールします。 ./train.py work/cifar10.baseモデルを作成し、トレーニングを開始し、 args.saveに進行を節約します。トレーニングスクリプトは、エポックごとにplot.pyを呼び出して、保存された進捗からプロットを作成します。
以下は、このモデルを使用する場合は引用する必要があるデンセンペーパーのBibtexエントリです。
@article{Huang2016Densely,
author = {Huang, Gao and Liu, Zhuang and Weinberger, Kilian Q.},
title = {Densely Connected Convolutional Networks},
journal = {arXiv preprint arXiv:1608.06993},
year = {2016}
}
この実装を使用する場合は、次のBibtexまたはPlantextエントリを使用して、この実装とコードリポジトリを引用することも検討してください。 Bibtexエントリには、 url LaTexパッケージが必要です。
@misc{amos2017densenet,
title = {{A PyTorch Implementation of DenseNet}},
author = {Amos, Brandon and Kolter, J. Zico},
howpublished = {url{https://github.com/bamos/densenet.pytorch}},
note = {Accessed: [Insert date here]}
}
Brandon Amos, J. Zico Kolter
A PyTorch Implementation of DenseNet
https://github.com/bamos/densenet.pytorch.
Accessed: [Insert date here]
このリポジトリはApache-Licensedです。


