densenet.pytorch
1.0.0
Esta es una implementación de Pytorch de la arquitectura Densenet-BC como se describe en las redes convolucionales densamente conectadas por G. Huang, Z. Liu, K. Weinberger y L. van der Maaten. Esta implementación obtiene una tasa de error CIFAR-10+ de 4.77 con un Densenet-BC de 100 capas con una tasa de crecimiento de 12. Su implementación oficial y sus enlaces a muchas otras implementaciones de terceros están disponibles en el repositorio de Liuzhuang13/Densenet en Github.

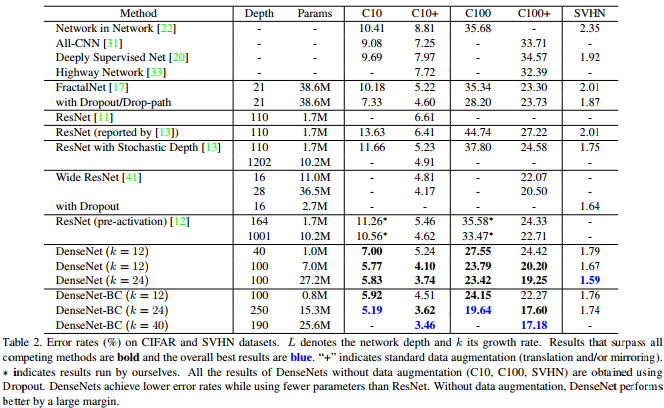
Como muestra esta tabla del artículo de Densenet, proporciona resultados competitivos de última generación en CIFAR-10, CIFAR-100 y SVHN.
Pytorch es un gran marco nuevo y es bueno tener este tipo de reimplementos para que puedan integrarse con otros proyectos de Pytorch.
Curiosamente, al implementar esto, tuve muchos problemas para que convergiera y miré cada parte del código más cerca de lo que normalmente lo haría. Comparé todos los estados ocultos y gradientes del modelo con la implementación oficial para asegurarme de que mi código fuera correcto e incluso entrené una red de estilo VGG en CIFAR-10 con el código de entrenamiento aquí. Resulta que descubrí un nuevo error crítico de Pytorch (ahora arreglado) que estaba causando esto.
He dejado en mi mensaje original sobre cómo esto no funciona y las cosas que he revisado en este documento. Creo que esto debería ser interesante para otras personas para ver mis estrategias de desarrollo y depuración al tener problemas para implementar un modelo que se sabe que converge. También comencé este hilo del foro de Pytorch, que tiene algunos otros puntos de discusión. También puede estar interesado en mi guión que compara los gradientes de Pytorch con los gradientes de antorcha y mi guión que verifica numéricamente los gradientes de Pytorch.
Mis problemas de convergencia se debieron a un error crítico de Pytorch relacionado con el uso de torch.cat con convoluciones con CUDNN habilitado (que es de manera predeterminada cuando se usa CUDA). Este error causó gradientes incorrectos y la solución a este error es deshabilitar CUDNN (que ya no tiene que hacerse porque se soluciona). La supervisión en mis estrategias de depuración que me hicieron no encontrar este error es que no pensé en deshabilitar Cudnn. Hasta ahora, he asumido que la opción CUDNN en los marcos está libre de errores, pero he aprendido que este no siempre es el caso. Es posible que también haya encontrado algo si hubiera depurado numéricamente capas torch.cat con convoluciones en lugar de capas completamente conectadas.
Adam solucionó el error de Pytorch que causó esto en este PR y se ha fusionado en la rama maestra de Torch. Si está interesado en usar el código Densenet en este repositorio, asegúrese de que su versión de Pytorch contenga este PR y se descargue después de 2017-02-10.
Puede ver el gráfico de cómputo aquí, que creé con make_graph.py, que copié de la esencia de Adam Paszke. Adam dice que Pytorch pronto tendrá una mejor manera de crear gráficos de cómputo.
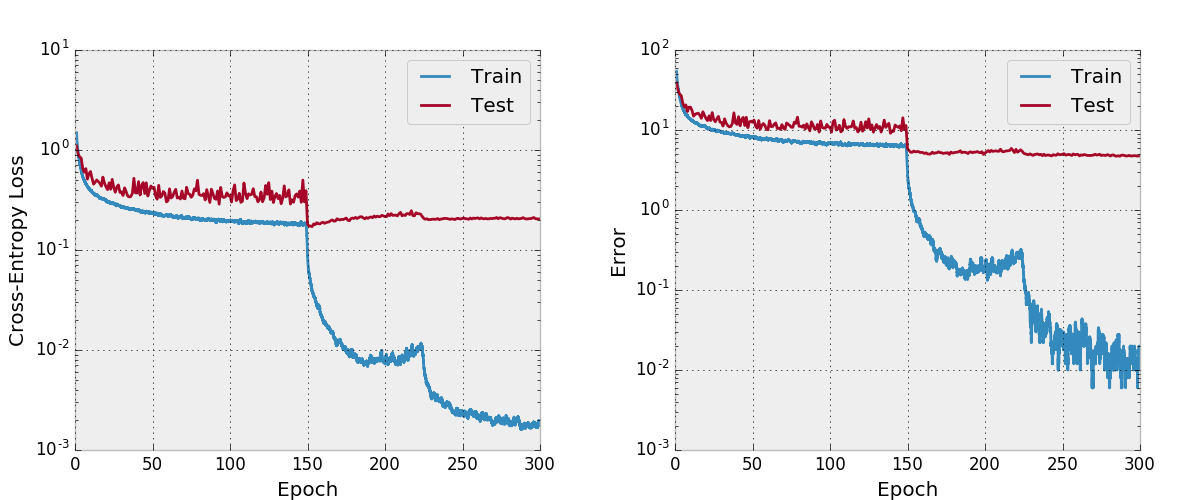
Por defecto, este repositorio entrena un Densenet-BC de 100 capas con una tasa de crecimiento de 12 en el conjunto de datos CIFAR-10 con aumentos de datos. Debido a los tamaños de memoria de GPU, este es el modelo más grande que puedo ejecutar. El documento informa un error de prueba final de 4.51 con esta arquitectura y obtenemos un error de prueba final de 4.77.
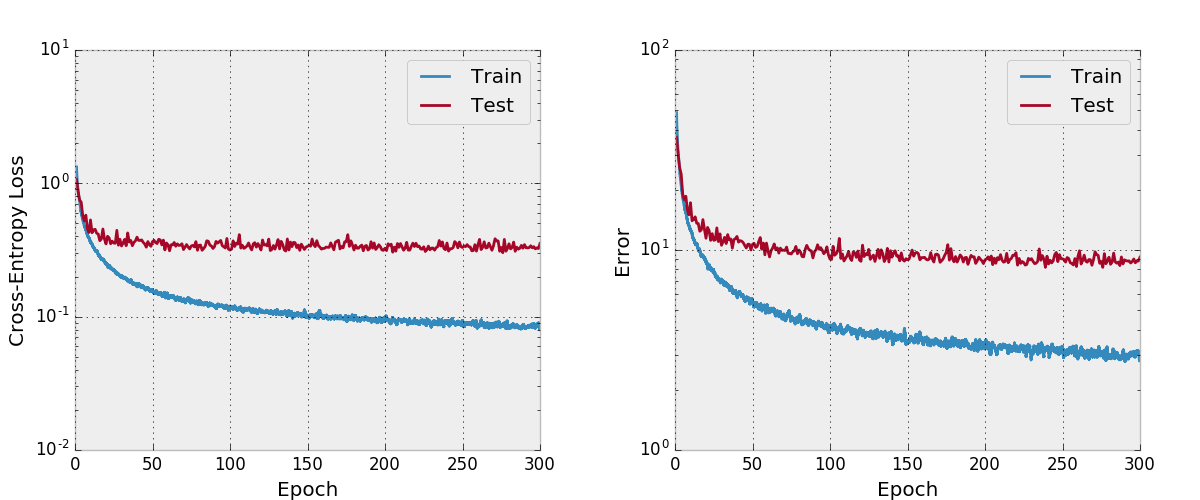
También intenté entrenar una red con Adam y descubrí que no convergió tan bien con los hiperparametros predeterminados en comparación con SGD con un programa de tasas de aprendizaje razonable.
No he probado esto tan a fondo, debe asegurarse de que funcione como se esperaba si planea usarlo y modificarlo. Avísame si encuentras algo malo en ello.
Me gusta incluir algunas características en mis proyectos que no veo en otras reimplementos que estén presentes en este repositorio. El código de entrenamiento en train.py usa argparse para que el tamaño del lote y algunos otros hiperparams se puedan cambiar fácilmente y, como el modelo está entrenando, el progreso se escribe en archivos CSV en un directorio de trabajo también definido por los argumentos. Luego, un script separado plot.py traza el progreso escrito por el script de entrenamiento. El script de entrenamiento llama a plot.py después de cada época, pero es importante que se pueda ejecutar por sí solo para que las figuras se puedan ajustar sin volver a ejecutar todo el experimento.
Creo que hay formas de mejorar la utilización de la memoria en este código como en la implementación oficial de antorcha de eficiencia espacial. También estaría interesado en el soporte de múltiples GPU.
Primero instale Pytorch (idealmente en una distribución Anaconda3). ./train.py creará un modelo, comenzará a entrenarlo y guardará el progreso en args.save , que es work/cifar10.base de forma predeterminada. El script de entrenamiento llamará a Plot.py después de cada época para crear tramas a partir del progreso guardado.
La siguiente es una entrada de Bibtex para el papel Densenet que debe citar si usa este modelo.
@article{Huang2016Densely,
author = {Huang, Gao and Liu, Zhuang and Weinberger, Kilian Q.},
title = {Densely Connected Convolutional Networks},
journal = {arXiv preprint arXiv:1608.06993},
year = {2016}
}
Si utiliza esta implementación, también considere citar esta implementación y repositorio de código con el siguiente bibtex o entrada de texto sin formato. La entrada de Bibtex requiere el paquete de látex url .
@misc{amos2017densenet,
title = {{A PyTorch Implementation of DenseNet}},
author = {Amos, Brandon and Kolter, J. Zico},
howpublished = {url{https://github.com/bamos/densenet.pytorch}},
note = {Accessed: [Insert date here]}
}
Brandon Amos, J. Zico Kolter
A PyTorch Implementation of DenseNet
https://github.com/bamos/densenet.pytorch.
Accessed: [Insert date here]
Este repositorio tiene licencia de apache.


