densenet.pytorch
1.0.0
Esta é uma implementação de Pytorch da arquitetura Densenet-BC, conforme descrito nas redes convolucionais densamente conectadas por G. Huang, Z. Liu, K. Weinberger e L. van der Maaten. Essa implementação obtém uma taxa de erro CIFAR-10+ de 4,77 com um Densenet-BC de 100 camadas com uma taxa de crescimento de 12. Sua implementação oficial e links para muitas outras implementações de terceiros estão disponíveis no Liuzhuang13/Densenet Repo no Github.

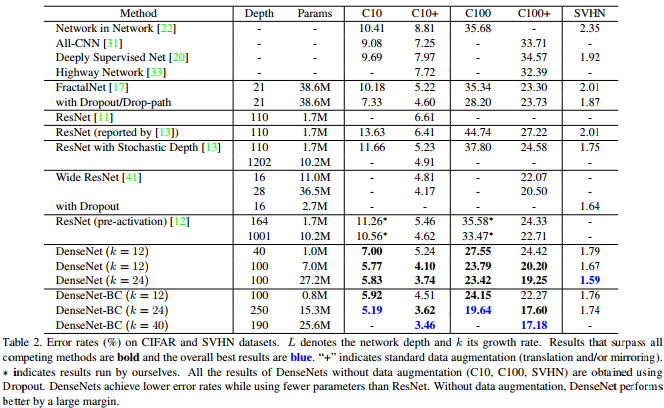
Como mostra esta tabela do artigo Densenet, fornece resultados competitivos de última geração no CIFAR-10, CIFAR-100 e SVHN.
O Pytorch é uma ótima nova estrutura e é bom ter esses tipos de implementações para que possam ser integrados a outros projetos da Pytorch.
Curiosamente, ao implementar isso, tive muitos problemas para convergir e analisei todas as partes do código mais perto do que normalmente. Comparei todos os estados e gradientes ocultos do modelo com a implementação oficial para garantir que meu código estivesse correto e até treinei uma rede no estilo VGG no CIFAR-10 com o código de treinamento aqui. Acontece que eu descobri um novo bug crítico de pytorch (agora corrigido) que estava causando isso.
Deixei em torno da minha mensagem original sobre como isso não está funcionando e as coisas que verifiquei neste documento. Eu acho que isso deve ser interessante para outras pessoas verem minhas estratégias de desenvolvimento e depuração ao ter problemas para implementar um modelo que é conhecido por convergir. Eu também iniciei este tópico do fórum Pytorch, que tem alguns outros pontos de discussão. Você também pode estar interessado no meu script que compara os gradientes Pytorch com os gradientes da tocha e meu script que verifica numericamente os gradientes do pytorch.
Meus problemas de convergência foram devidos a um bug crítico de pytorch relacionado ao uso torch.cat com convoluções com o CUDNN ativado (que é por padrão quando o CUDA é usado). Esse bug causou gradientes incorretos e a correção desse bug é desativar o CUDNN (que não precisa mais ser feito porque é corrigido). A supervisão em minhas estratégias de depuração que me levou a não encontrar esse erro é que eu não pensei em desativar o CUDNN. Até agora, assumi que a opção CUDNN nas estruturas é livre de bugs, mas aprendi que esse nem sempre é o caso. Eu também poderia ter encontrado algo se eu teria depurado numericamente as camadas torch.cat .
Adam corrigiu o bug pytorch que causou isso neste PR e foi mesclado no ramo principal da Torch. Se você estiver interessado em usar o código Densenet neste repositório, verifique se a versão Pytorch contém esse PR e foi baixada após 2017-02-10.
Você pode ver o gráfico de computação aqui, que eu criei com make_graph.py, que copiei da essência de Adam Paszke. Adam diz que Pytorch em breve terá uma maneira melhor de criar gráficos de computação.
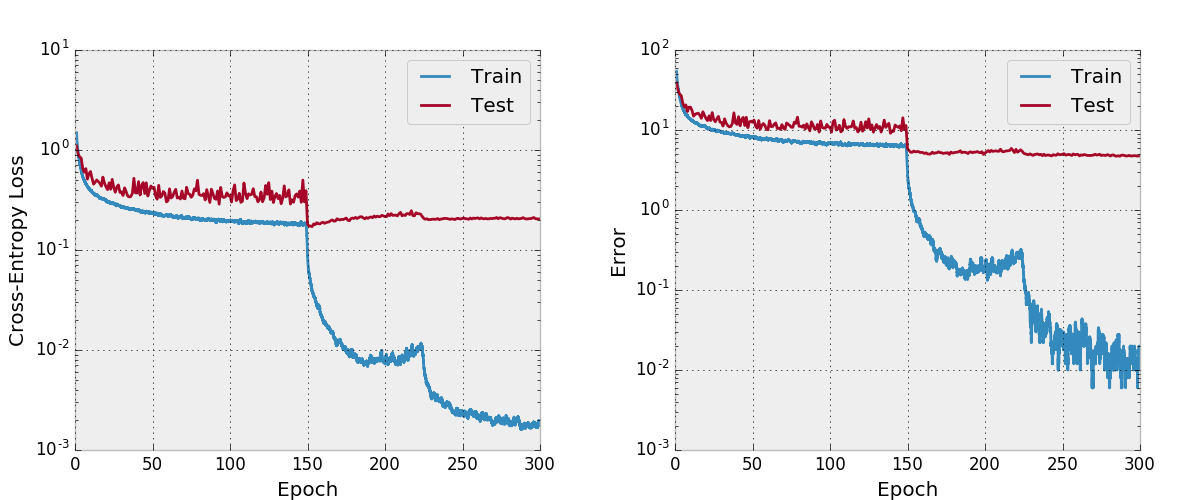
Por padrão, esse repo treina um Densenet-BC de 100 camadas com uma taxa de crescimento de 12 no conjunto de dados CIFAR-10 com aumento de dados. Devido aos tamanhos da memória da GPU, este é o maior modelo que eu posso executar. O artigo relata um erro de teste final de 4.51 com esta arquitetura e obtemos um erro de teste final de 4.77.
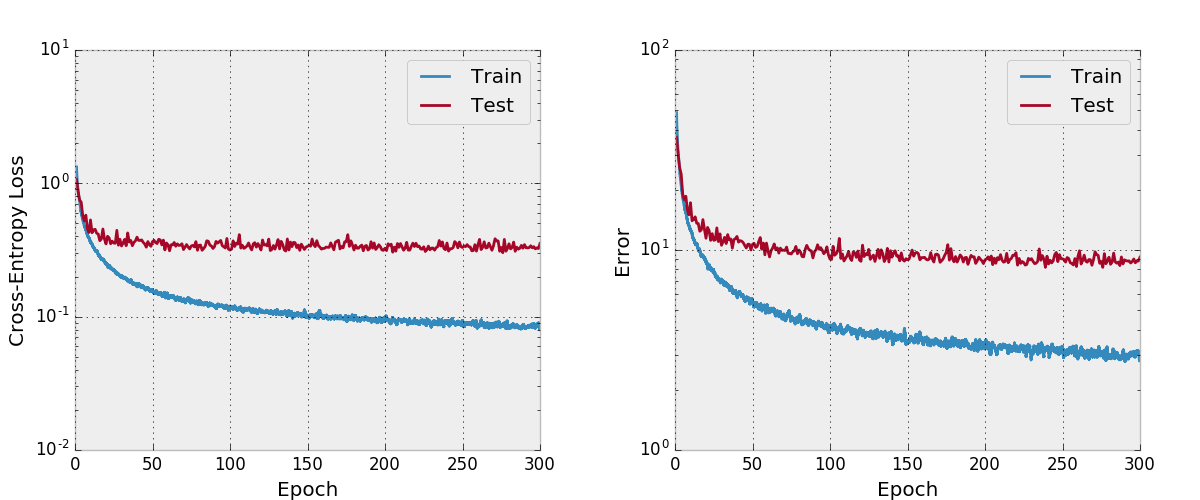
Também tentei treinar uma rede com Adam e descobri que ela não convergeu tão bem com os hiper-parâmetros padrão em comparação com o SGD com um cronograma de taxa de aprendizado razoável.
Eu não testei isso tão minuciosamente, você deve garantir que esteja funcionando como esperado se você planeja usá -lo e modificá -lo. Deixe -me saber se você encontrar algo de errado com isso.
Gosto de incluir alguns recursos em meus projetos que não vejo em outras reimplementações presentes neste repositório. O código de treinamento em train.py usa argparse , para que o tamanho do lote e algumas outras hiper-paramas possam ser facilmente alteradas e, como o modelo é o treinamento, o progresso é escrito para arquivos CSV em um diretório de trabalho também definido pelos argumentos. Em seguida, um plot.py script separado. Plota o progresso escrito pelo script de treinamento. O script de treinamento chama plot.py após cada época, mas pode ser executado por conta própria para que os números possam ser aprimorados sem executar novamente todo o experimento.
Eu acho que existem maneiras de melhorar a utilização da memória nesse código, como na implementação oficial da tocha com eficiência espacial. Eu também estaria interessado no suporte a multi-GPU.
Primeiro instale o Pytorch (idealmente em uma distribuição do Anaconda3). ./Train.py criará um modelo, começará a treiná -lo e salvará progresso no args.save , que é work/cifar10.base por padrão. O script de treinamento ligará para o plot.py após cada época para criar parcelas a partir do progresso salvo.
A seguir, é apresentada uma entrada do BibTex para o papel Densenet que você deve citar se usar este modelo.
@article{Huang2016Densely,
author = {Huang, Gao and Liu, Zhuang and Weinberger, Kilian Q.},
title = {Densely Connected Convolutional Networks},
journal = {arXiv preprint arXiv:1608.06993},
year = {2016}
}
Se você usar esta implementação, considere também citar essa implementação e repositório de código com a seguinte entrada BibTex ou PlainText. A entrada Bibtex requer o pacote de látex url .
@misc{amos2017densenet,
title = {{A PyTorch Implementation of DenseNet}},
author = {Amos, Brandon and Kolter, J. Zico},
howpublished = {url{https://github.com/bamos/densenet.pytorch}},
note = {Accessed: [Insert date here]}
}
Brandon Amos, J. Zico Kolter
A PyTorch Implementation of DenseNet
https://github.com/bamos/densenet.pytorch.
Accessed: [Insert date here]
Este repositório é licenciado pelo Apache.


