densenet.pytorch
1.0.0
Dies ist eine Pytorch-Implementierung der Densenet-BC-Architektur, wie in dem Papier beschrieben von G. Huang, Z. Liu, K. Weinberger und L. van der Maaten beschrieben. Diese Implementierung erhält eine CIFAR-10+ -Fehlerrate von 4,77 mit einem 100-Schicht-Densenet-BC mit einer Wachstumsrate von 12. Ihre offizielle Implementierung und die Verbindung zu vielen anderen Implementierungen von Drittanbietern sind im Liuzhuang13/Densenet Repo auf GitHub verfügbar.

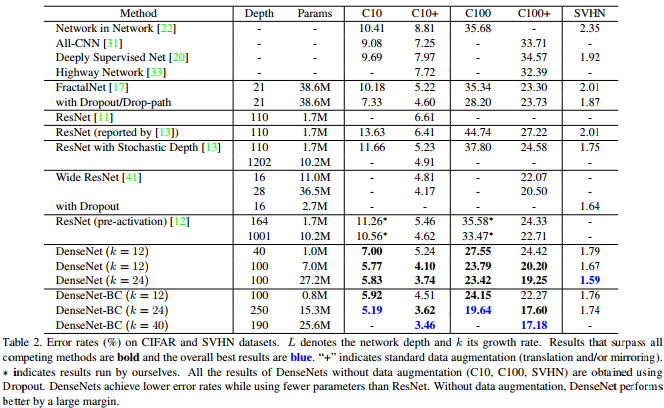
Wie diese Tabelle aus dem Densenet-Papier zeigt, liefert sie wettbewerbsfähige Stand der Kunstergebnisse zu CIFAR-10, CIFAR-100 und SVHN.
Pytorch ist ein großartiger neuer Framework und es ist schön, solche Neuimplementationen zu haben, damit sie in andere Pytorch-Projekte integriert werden können.
Interessanterweise hatte ich bei der Implementierung große Probleme damit, es zu konvergieren, und sah jeden Teil des Codes näher als ich normalerweise an. Ich habe alle versteckten Zustände und Gradienten des Modells mit der offiziellen Implementierung verglichen, um sicherzustellen, dass mein Code korrekt war und sogar ein VGG-Netzwerk im VGG-Stil in CIFAR-10 mit dem Trainingscode hier geschult hat. Es stellte sich heraus, dass ich einen neuen kritischen Pytorch -Fehler (jetzt behoben) entdeckt habe, der dies verursachte.
Ich habe meine ursprüngliche Nachricht darüber gelassen, wie dies nicht funktioniert und welche Dinge ich in diesem Dokument überprüft habe. Ich denke, dies sollte für andere Menschen interessant sein, meine Entwicklungs- und Debugging -Strategien zu sehen, wenn Probleme bei der Implementierung eines Modells, das bekannt ist, konvergiert. Ich habe auch diesen Pytorch Forum -Thread begonnen, der einige andere Diskussionspunkte hat. Möglicherweise interessieren Sie sich auch für mein Skript, das Pytorch -Gradienten mit Fackelgradienten und meinem Skript vergleicht, das numerisch Pytorch -Gradienten überprüft.
Meine Konvergenzprobleme waren auf einen kritischen Pytorch -Fehler zurückzuführen, der sich auf die Verwendung von torch.cat mit Konvolutionen mit aktiviertem CUDNN bezieht (was standardmäßig bei Verwendung von CUDA verwendet wird). Dieser Fehler verursachte falsche Gradienten, und die Fix für diesen Fehler besteht darin, Cudnn zu deaktivieren (was nicht mehr durchgeführt werden muss, weil er behoben ist). Die Aufsicht über meine Debugging -Strategien, die mich dazu veranlassten, diesen Fehler nicht zu finden, ist, dass ich nicht gedacht habe, Cudnn zu deaktivieren. Bis jetzt habe ich angenommen, dass die Cudnn-Option in Frameworks fehlerfrei ist, aber erfuhr, dass dies nicht immer der Fall ist. Ich habe vielleicht auch etwas gefunden, wenn ich numerisch torch.cat mit Konvolutionen anstelle von vollständig verbundenen Schichten debuggen hätte.
Adam hat den Pytorch -Fehler behoben, der dies in dieser PR verursachte, und wurde in Torchs Master -Zweig zusammengefasst. Wenn Sie daran interessiert sind, den Densenet-Code in diesem Repository zu verwenden, stellen Sie sicher, dass Ihre Pytorch-Version diese PR enthält und nach 2017-02-10 heruntergeladen wurde.
Sie können das Rechendiagramm hier sehen, das ich mit make_graph.py erstellt habe, das ich von Adam Paszkes Gist kopiert habe. Laut Adam wird Pytorch bald eine bessere Möglichkeit haben, Berechnungdiagramme zu erstellen.
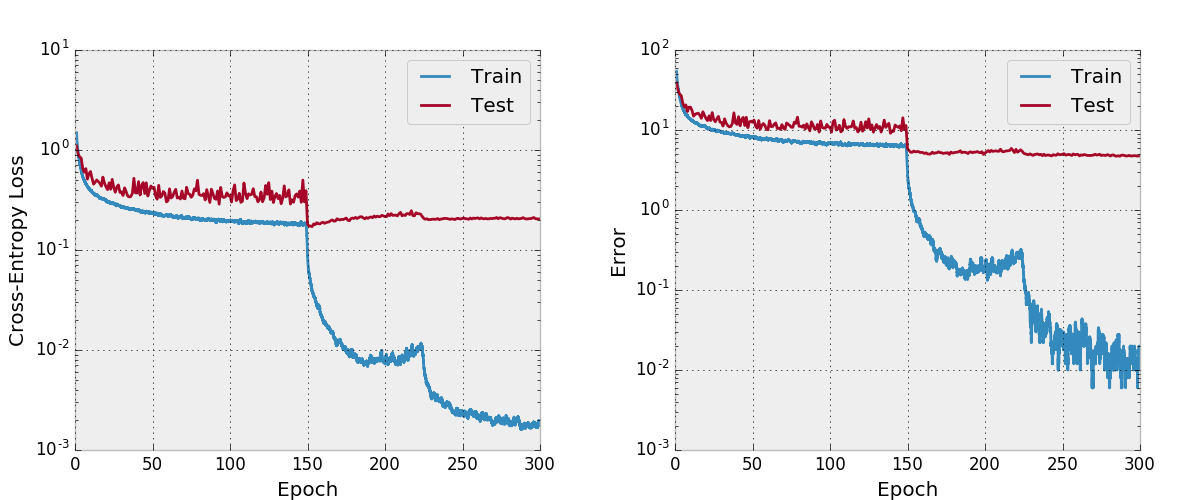
Standardmäßig schult dieses Repo mit einer Wachstumsrate von 12 auf dem CIFAR-10-Datensatz mit einer Wachstumsrate von 12 mit Datenvergrößerungen. Aufgrund von GPU -Speichergrößen ist dies das größte Modell, das ich ausführen kann. Das Papier berichtet über einen endgültigen Testfehler von 4,51 mit dieser Architektur und wir erhalten einen endgültigen Testfehler von 4,77.
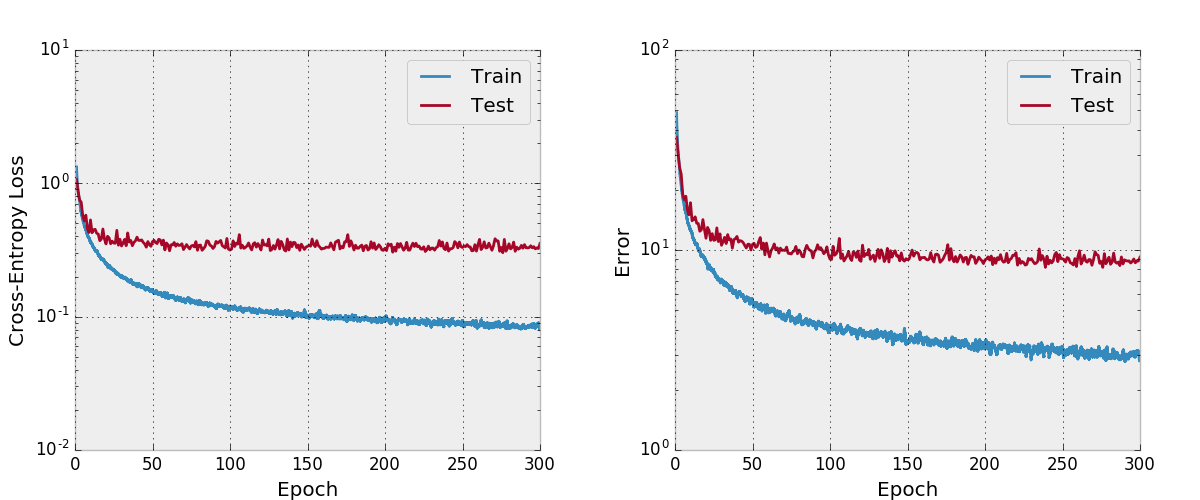
Ich habe auch versucht, ein Netz mit Adam zu trainieren und festzustellen, dass es im Vergleich zu SGD mit einem angemessenen Lernratesplan nicht auch mit den Standard-Hyperparametern zusammengestellt wurde.
Ich habe dies nicht so gründlich getestet. Sie sollten sicherstellen, dass es wie erwartet funktioniert, wenn Sie es verwenden und ändern möchten. Lassen Sie mich wissen, wenn Sie etwas falsches daran finden.
Ich möchte einige Funktionen in meine Projekte einbeziehen, die ich in einigen anderen Neuauflagen nicht sehe, die in diesem Repo vorhanden sind. Der Trainingscode in train.py verwendet argparse , sodass die Chargengröße und einige andere Hyperparams leicht geändert werden können. Wenn das Modell trainiert, wird der Fortschritt in CSV-Dateien in einem Arbeitsverzeichnis geschrieben, das ebenfalls durch die Argumente definiert ist. Dann plant ein separates Skript plot.py . Das Trainingsskript nennt plot.py nach jeder Epoche, kann jedoch von vor allem selbst ausgeführt werden, sodass die Figuren optimiert werden können, ohne das gesamte Experiment erneut zu veranstalten.
Ich denke, es gibt Möglichkeiten, die Speicherauslastung in diesem Code zu verbessern, wie in der offiziellen platzbezogenen Fackel-Implementierung. Ich würde mich auch für Support mit mehreren GPU interessieren.
Installieren Sie zuerst Pytorch (idealerweise in einer Anaconda3 -Verteilung). ./train.py erstellt ein Modell, beginnt es zu trainieren und den Fortschritt in args.save zu speichern, nämlich work/cifar10.base standardmäßig. Das Trainingsskript ruft Plot.py nach jeder Epoche an, um Diagramme aus dem gespeicherten Fortschritt zu erstellen.
Das Folgende ist ein Bibtex -Eintrag für das Densenetpapier, das Sie bei Verwendung dieses Modells zitieren sollten.
@article{Huang2016Densely,
author = {Huang, Gao and Liu, Zhuang and Weinberger, Kilian Q.},
title = {Densely Connected Convolutional Networks},
journal = {arXiv preprint arXiv:1608.06993},
year = {2016}
}
Wenn Sie diese Implementierung verwenden, erwägen Sie auch, diese Implementierung und das Code -Repository mit dem folgenden Bibtex- oder Klartexteintrag zu zitieren. Der Bibtex -Eintrag erfordert das url -Latexpaket.
@misc{amos2017densenet,
title = {{A PyTorch Implementation of DenseNet}},
author = {Amos, Brandon and Kolter, J. Zico},
howpublished = {url{https://github.com/bamos/densenet.pytorch}},
note = {Accessed: [Insert date here]}
}
Brandon Amos, J. Zico Kolter
A PyTorch Implementation of DenseNet
https://github.com/bamos/densenet.pytorch.
Accessed: [Insert date here]
Dieses Repository ist Apache-lizenziert.


