RAG Enhanced NCERT Tutor
1.0.0
Этот проект реализует систему извлечения в поисках генерации (RAG) для книг NCERT с использованием OLLAMA для встраивания текста и векторной базы данных, а также API GROQ для ответа на языковой модели.
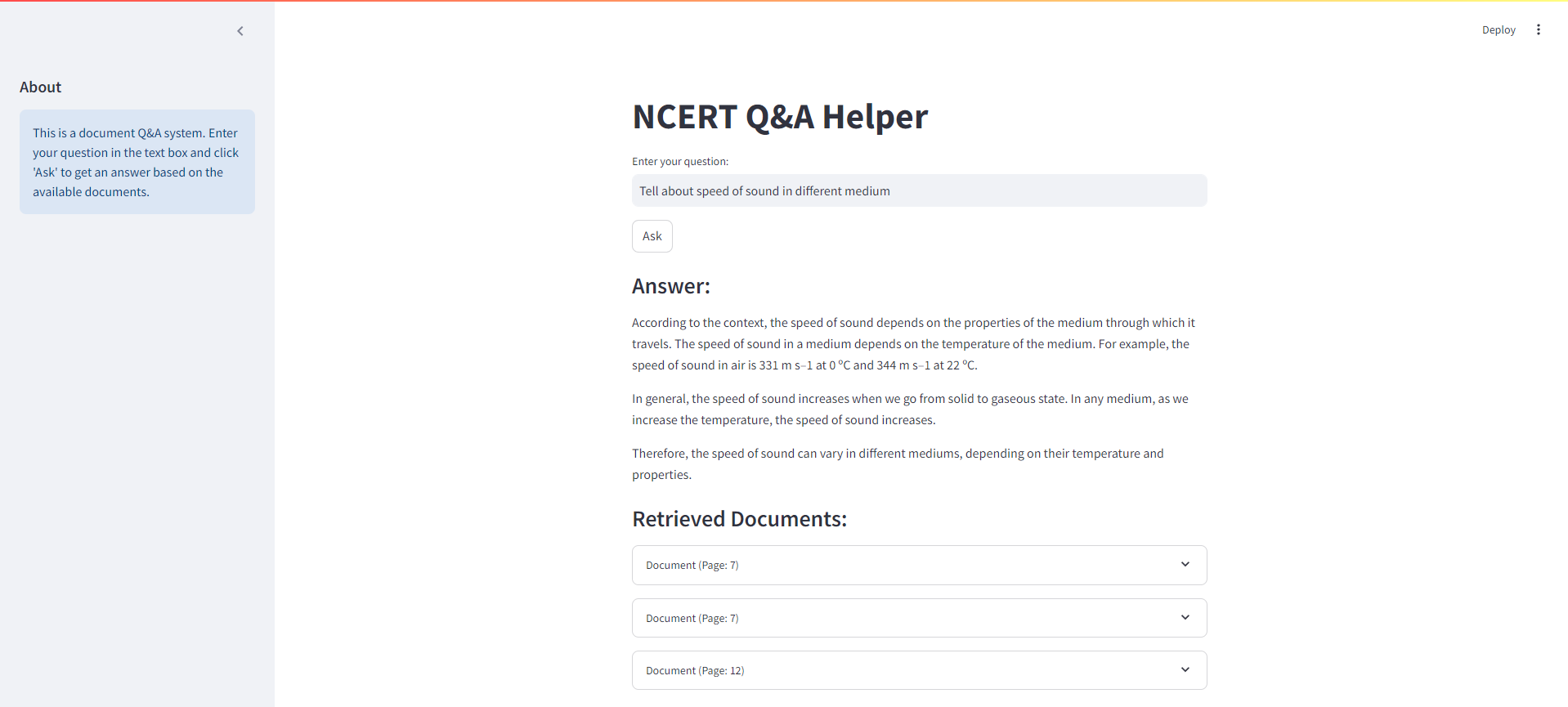
Ниже приведен скриншот интерфейса потока для нашей тряпичной системы NCERT:
Вот обзор архитектуры системы Rag Books Ncert Books:
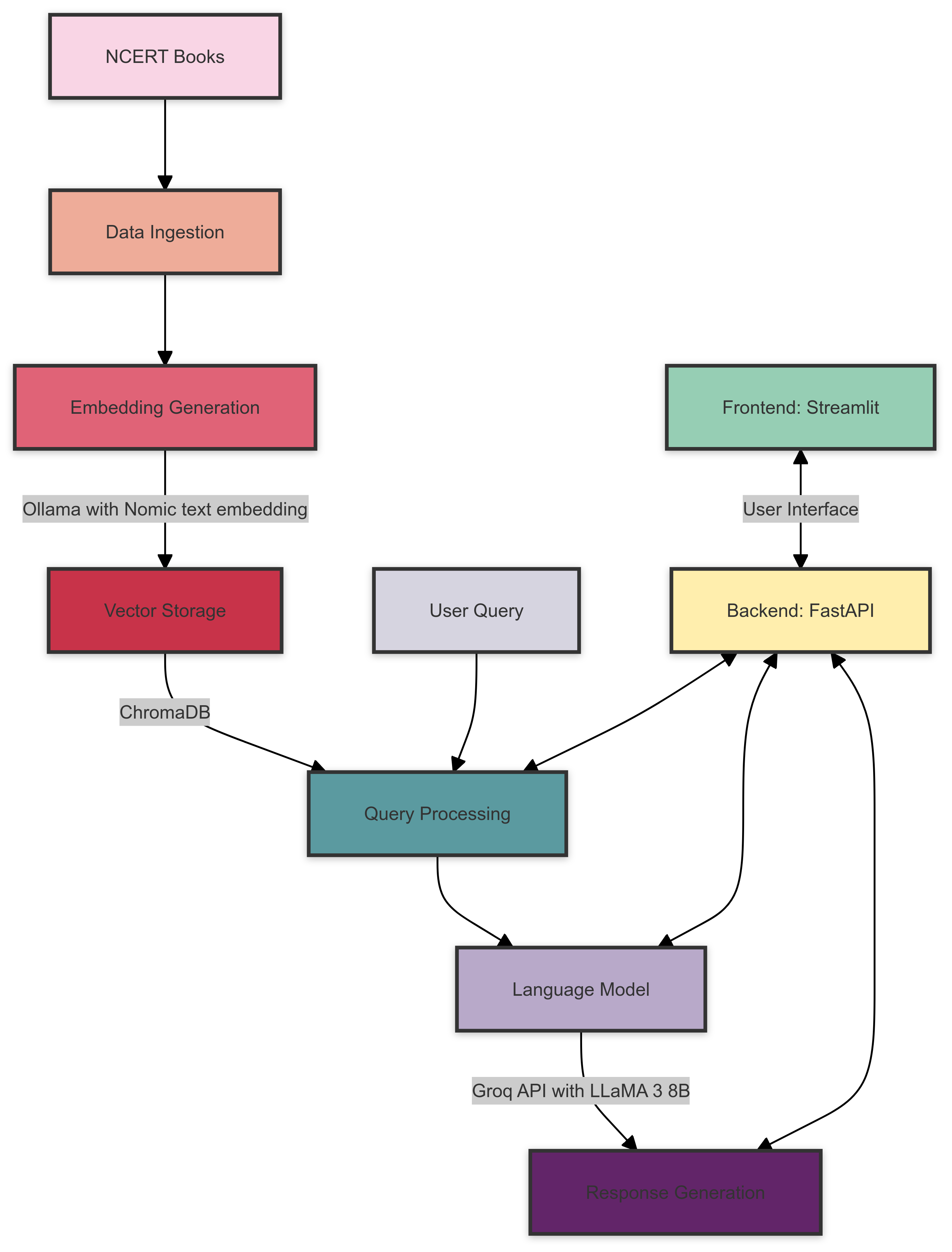
Архитектура системы состоит из следующих компонентов:
Прежде чем начать, убедитесь, что вы выполнили следующие требования:
Клонировать репозиторий:
git clone https://github.com/yourusername/ncert-rag-system.git
cd ncert-rag-system
Установите требуемые зависимости:
pip install -r requirements.txt
Скачать и настроить Ollama:
ollama pull nomic-embed-text
Установите свой ключ API Groq:
.env в корне проекта GROQ_API_KEY=your_api_key_here
Начните бэкэнд FASTAPI:
uvicorn main:app --reload
Запустите пользовательский интерфейс Streamlit:
streamlit run streamlit_app.py
Откройте свой веб -браузер и перейдите к URL -адресу приложения Streamlit (обычно http://localhost:8501 )
Используйте интерфейс для взаимодействия с тряпичной системой NCERT Books
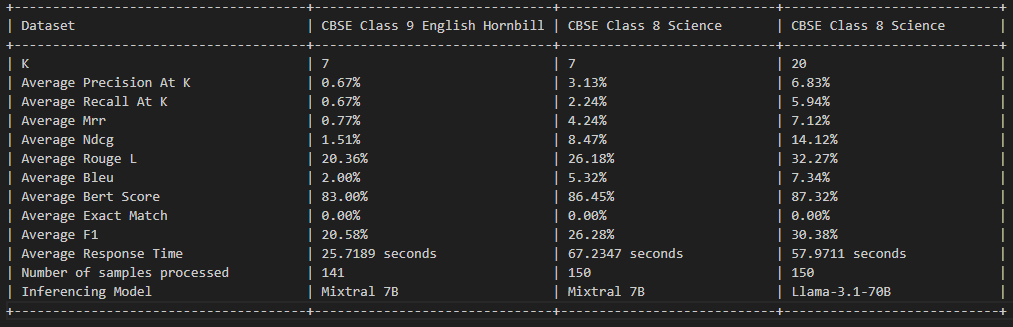
Этот проект лицензирован по лицензии MIT - для получения подробной информации см. Файл лицензии.
Взносы приветствуются! Пожалуйста, не стесняйтесь отправить запрос на привлечение.


