RAG Enhanced NCERT Tutor
1.0.0
이 프로젝트는 텍스트 임베딩 및 벡터 데이터베이스를 위해 Ollama를 사용하여 NCERT 책에 대한 검색 된 세대 생성 (RAG) 시스템을 구현하고 언어 모델 응답을위한 Groq API를 구현합니다.
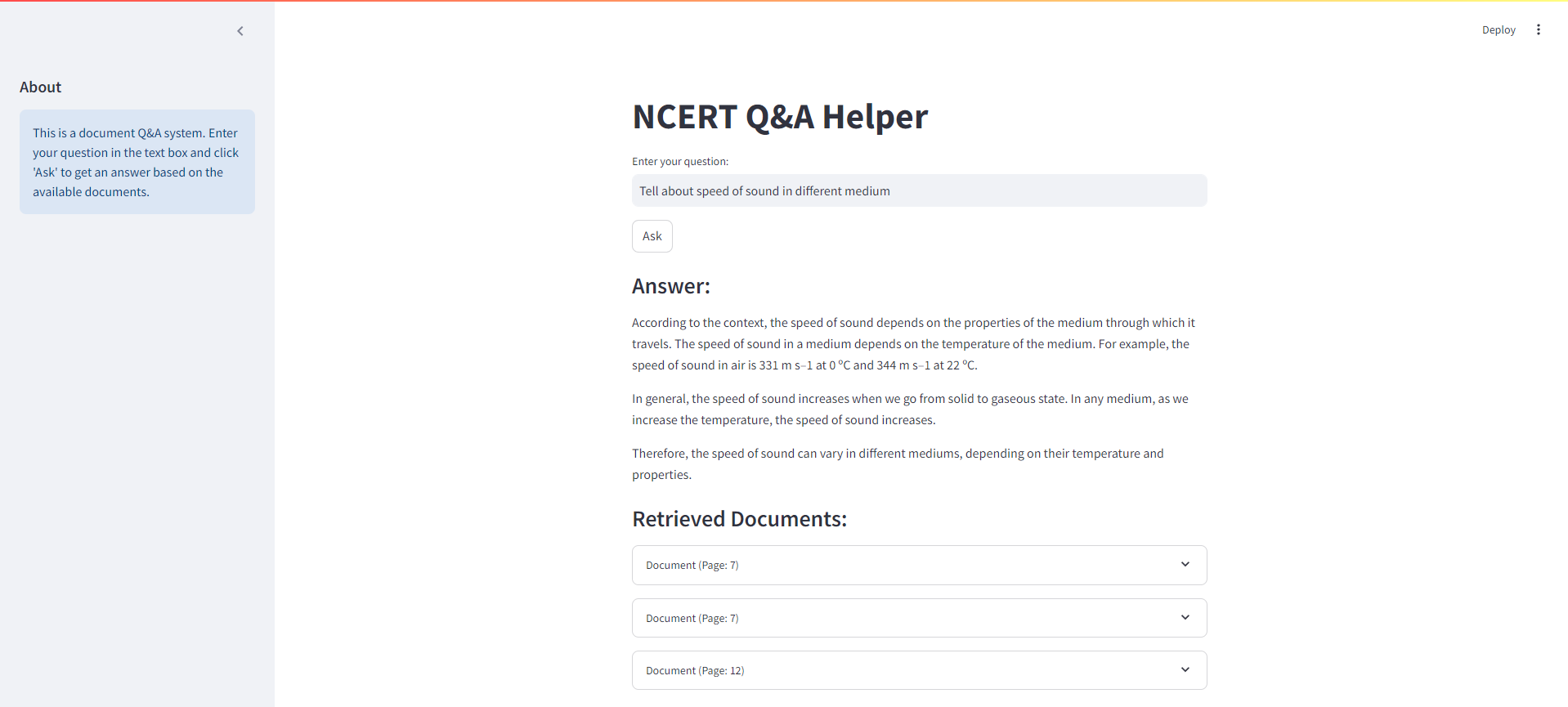
아래는 NCERT Books Rag 시스템의 Streamlit 인터페이스의 스크린 샷입니다.
다음은 NCERT BOOKS RAG 시스템 아키텍처에 대한 개요입니다.
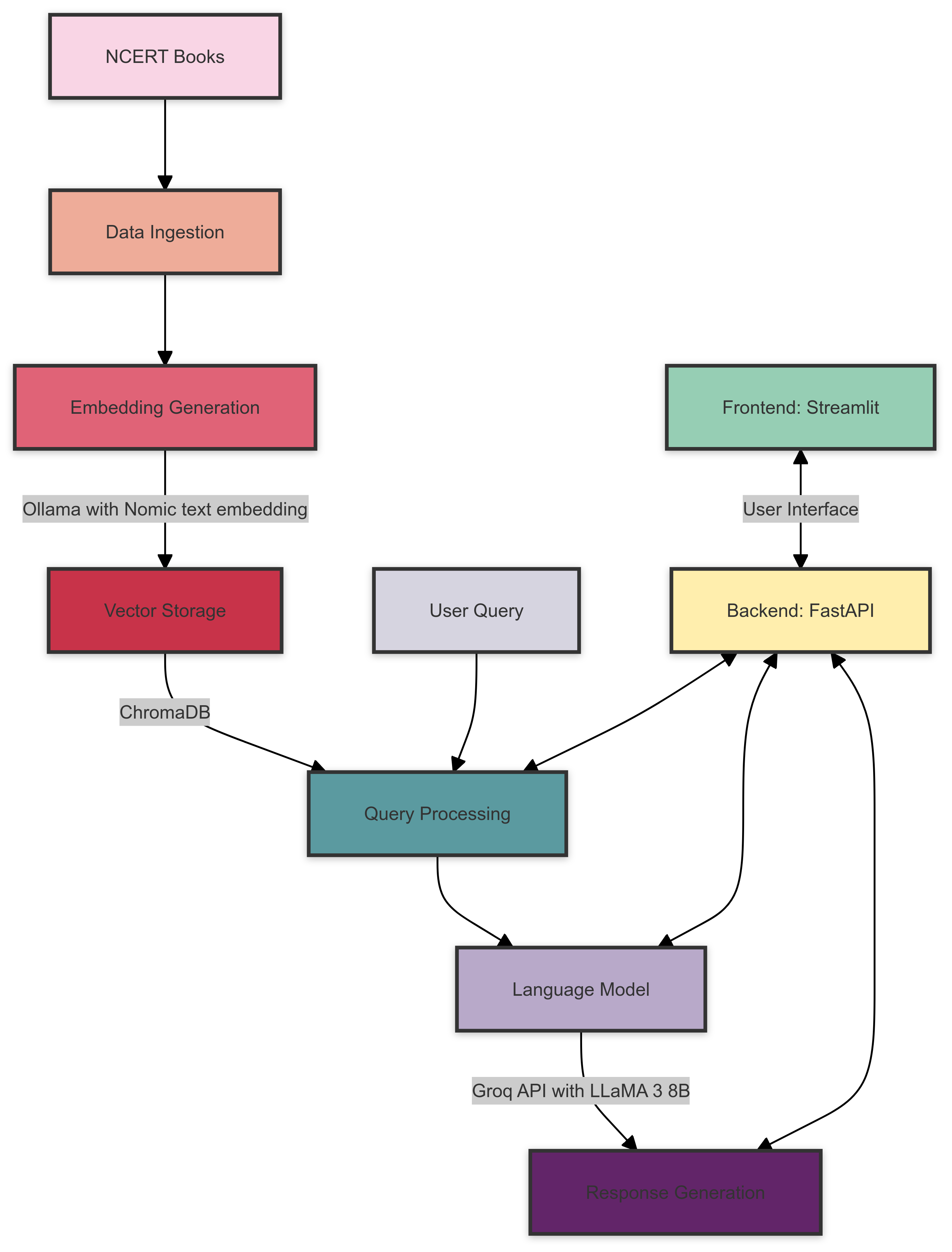
시스템 아키텍처는 다음 구성 요소로 구성됩니다.
시작하기 전에 다음 요구 사항을 충족했는지 확인하십시오.
저장소 복제 :
git clone https://github.com/yourusername/ncert-rag-system.git
cd ncert-rag-system
필요한 종속성 설치 :
pip install -r requirements.txt
올라마 다운로드 및 설정 :
ollama pull nomic-embed-text
Groq API 키 설정 :
.env 파일을 만듭니다 GROQ_API_KEY=your_api_key_here
Fastapi 백엔드를 시작하십시오.
uvicorn main:app --reload
간소화 UI를 시작하십시오.
streamlit run streamlit_app.py
웹 브라우저를 열고 Streamlit App URL (일반적으로 http://localhost:8501 )으로 이동하십시오.
인터페이스를 사용하여 NCERT BOOKS RAG 시스템과 상호 작용하십시오.
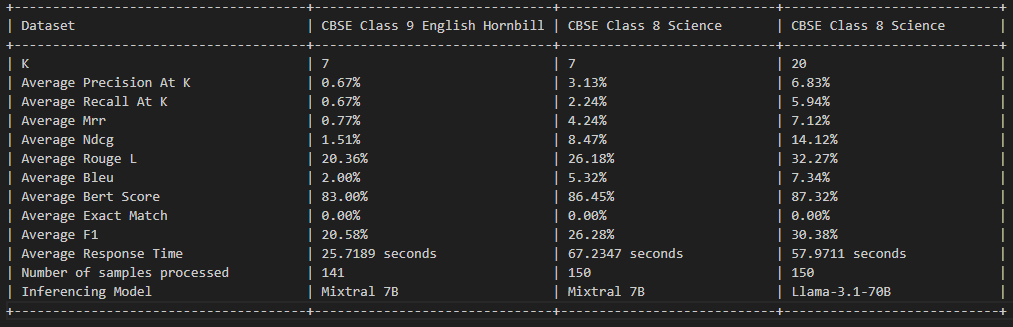
이 프로젝트는 MIT 라이센스에 따라 라이센스가 부여됩니다. 자세한 내용은 라이센스 파일을 참조하십시오.
기부금을 환영합니다! 풀 요청을 제출하십시오.


