RAG Enhanced NCERT Tutor
1.0.0
Ce projet met en œuvre un système de génération (RAG) (RAG) de récupération pour les livres NCERT en utilisant Olllama pour l'intégration de texte et la base de données vectorielle, et API GROQ pour la réponse du modèle de langue.
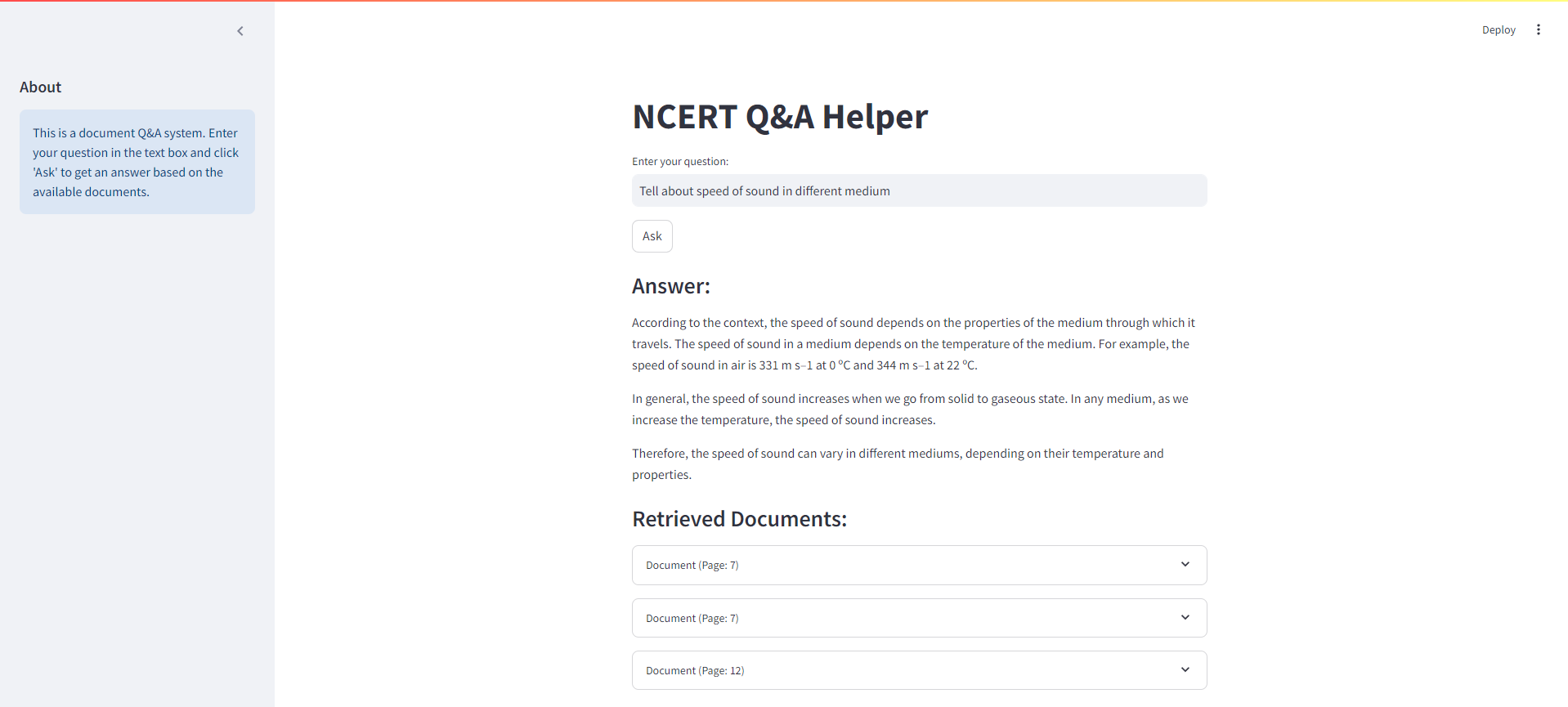
Vous trouverez ci-dessous une capture d'écran de l'interface rationalisée pour notre système de chiffon NCERT Books:
Voici un aperçu de l'architecture du système de chiffon NCERT Books:
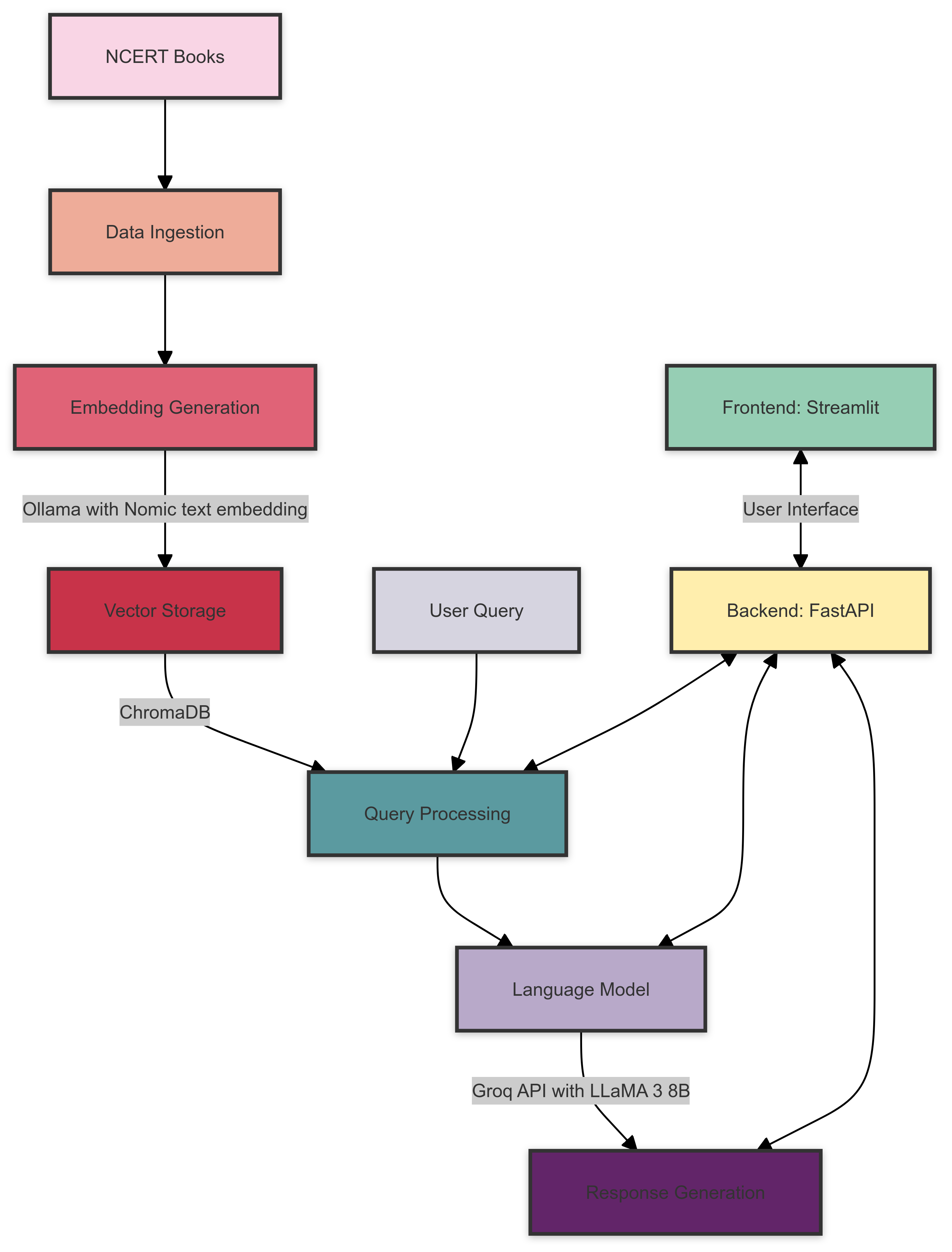
L'architecture du système se compose des composants suivants:
Avant de commencer, assurez-vous d'avoir satisfait aux exigences suivantes:
Clone le référentiel:
git clone https://github.com/yourusername/ncert-rag-system.git
cd ncert-rag-system
Installez les dépendances requises:
pip install -r requirements.txt
Télécharger et configurer Olllama:
ollama pull nomic-embed-text
Configurez votre clé API Groq:
.env dans la racine du projet GROQ_API_KEY=your_api_key_here
Commencez le backend Fastapi:
uvicorn main:app --reload
Lancez l'interface utilisateur rationalisée:
streamlit run streamlit_app.py
Ouvrez votre navigateur Web et accédez à l'URL de l'application Streamlit (généralement http://localhost:8501 )
Utilisez l'interface pour interagir avec le système de chiffon NCERT Books
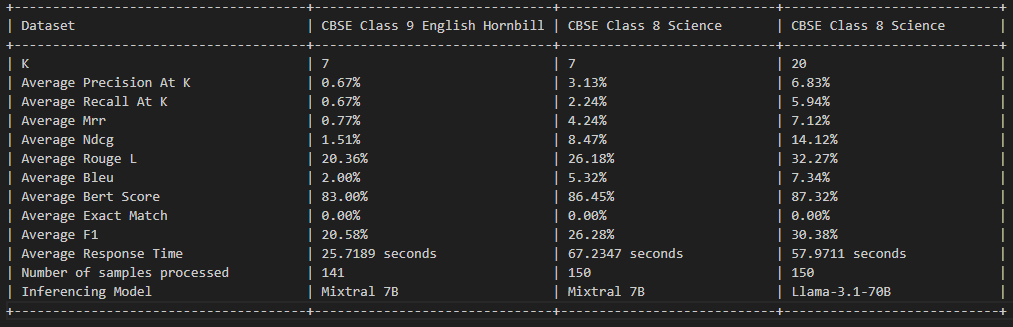
Ce projet est autorisé en vertu de la licence MIT - voir le fichier de licence pour plus de détails.
Les contributions sont les bienvenues! N'hésitez pas à soumettre une demande de traction.


