RAG Enhanced NCERT Tutor
1.0.0
Este proyecto implementa un sistema de generación de recuperación (RAG) para libros NCERT que usan Ollama para la incrustación de texto y la base de datos de vectores, y la API Groq para la respuesta del modelo de lenguaje.
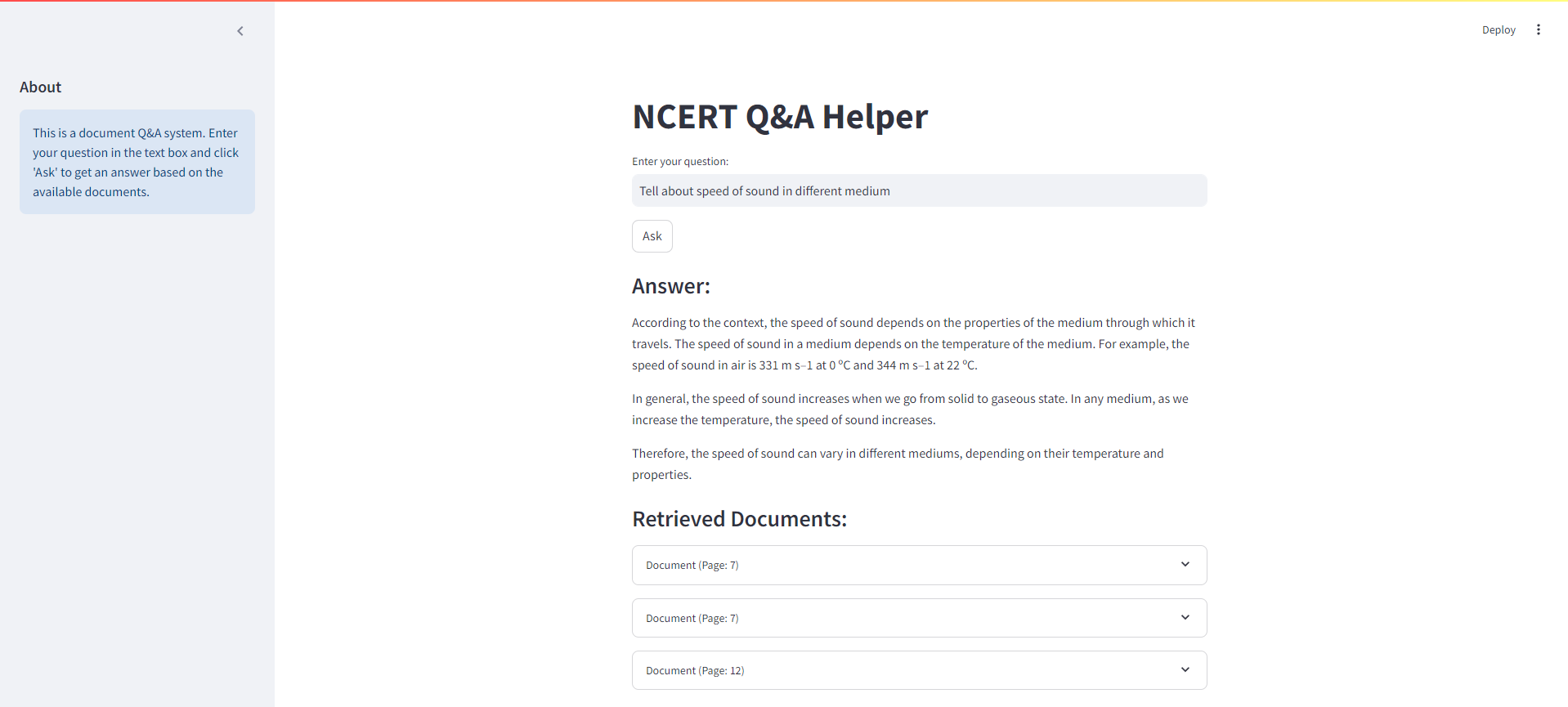
A continuación se muestra una captura de pantalla de la interfaz de transmisión para nuestro sistema de trapo de NCERT Books:
Aquí hay una descripción general de la arquitectura del sistema NCERT Books Rag:
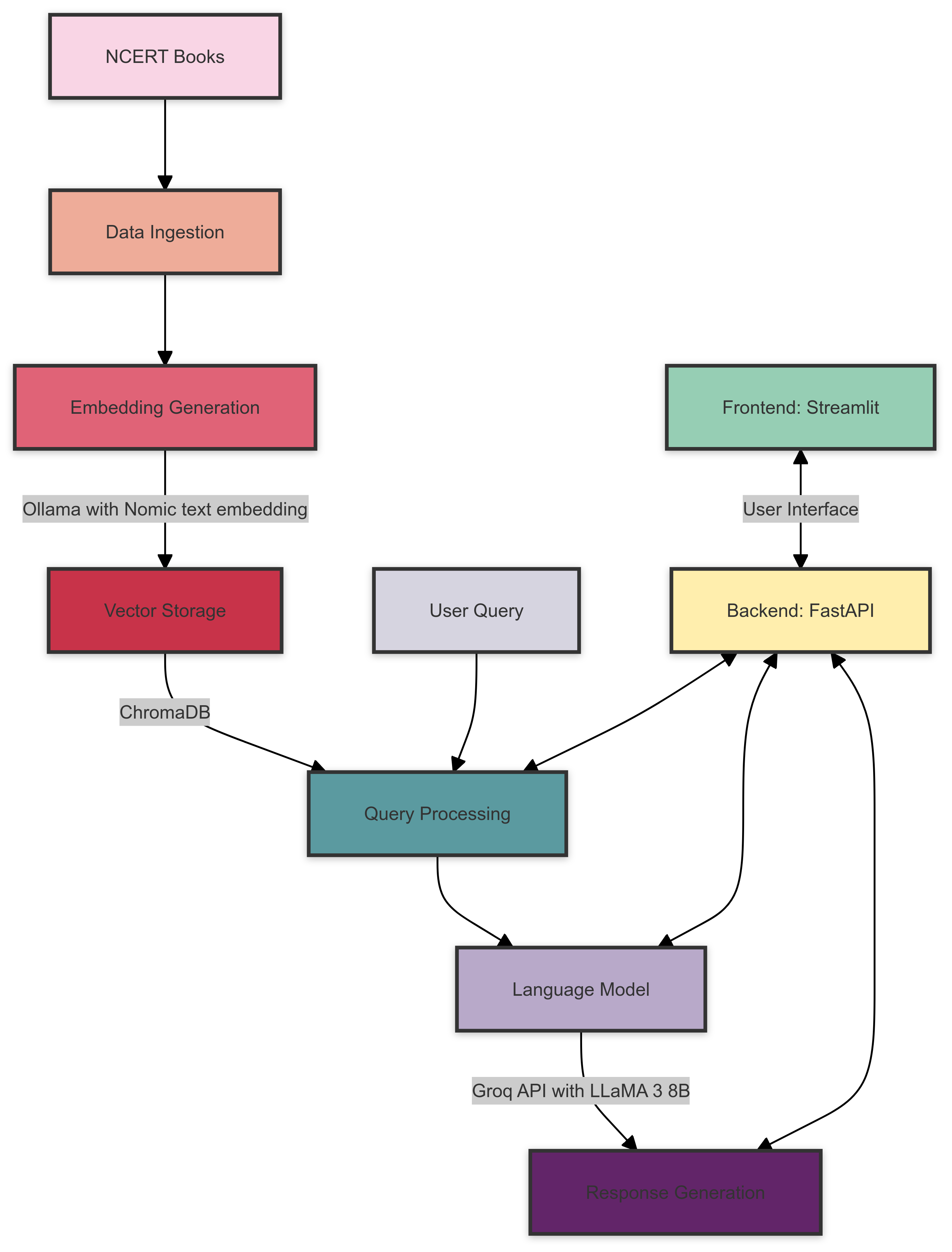
La arquitectura del sistema consta de los siguientes componentes:
Antes de comenzar, asegúrese de haber cumplido los siguientes requisitos:
Clon el repositorio:
git clone https://github.com/yourusername/ncert-rag-system.git
cd ncert-rag-system
Instale las dependencias requeridas:
pip install -r requirements.txt
Descargar y configurar Ollama:
ollama pull nomic-embed-text
Configure su tecla API Groq:
.env en la raíz del proyecto GROQ_API_KEY=your_api_key_here
Comience el backend de Fastapi:
uvicorn main:app --reload
Inicie la interfaz de usuario de transmisión:
streamlit run streamlit_app.py
Abra su navegador web y navegue a la URL de la aplicación de transmisión (generalmente http://localhost:8501 )
Use la interfaz para interactuar con el sistema de trapo de NCERT Books
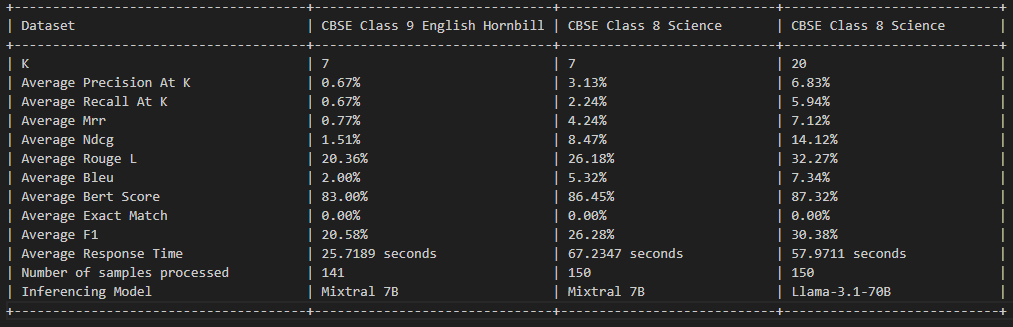
Este proyecto tiene licencia bajo la licencia MIT; consulte el archivo de licencia para obtener más detalles.
¡Las contribuciones son bienvenidas! No dude en enviar una solicitud de extracción.


